Predicting Likes: Inside A Simple Recommendation Engine’s Algorithms
The Internet is becoming “smarter” every day. The video-sharing website that you frequently visit seems to know exactly what you will like, even before you have seen it. The online shopping cart holding your items almost magically figures out the one thing that you may have missed or intended to add before checking out. It’s as if these web services are reading your mind—or are they?
Turns out, predicting a user’s likes involves more math than magic. In this article we explore one of the many ways of building a recommendation engine that is both simple to implement and understand.

The Internet is becoming “smarter” every day. The video-sharing website that you frequently visit seems to know exactly what you will like, even before you have seen it. The online shopping cart holding your items almost magically figures out the one thing that you may have missed or intended to add before checking out. It’s as if these web services are reading your mind—or are they?
Turns out, predicting a user’s likes involves more math than magic. In this article we explore one of the many ways of building a recommendation engine that is both simple to implement and understand.

Mahmud is a software developer with many years of experience and a knack for efficiency, scalability, and stable solutions.
Expertise
A recommendation engine (sometimes referred to as a recommender system) is a tool that lets algorithm developers predict what a user may or may not like among a list of given items. Recommendation engines are a pretty interesting alternative to search fields, as recommendation engines help users discover products or content that they may not come across otherwise. This makes recommendation engines a great part of web sites and services such as Facebook, YouTube, Amazon, and more.
Recommendation engines work ideally in one of two ways. It can rely on the properties of the items that a user likes, which are analyzed to determine what else the user may like; or, it can rely on the likes and dislikes of other users, which the recommendation engine then uses to compute a similarity index between users and recommend items to them accordingly. It is also possible to combine both these methods to build a much more robust recommendation engine. However, like all other information related problems, it is essential to pick an algorithm that is suitable for the problem being addressed.

In this tutorial, we will walk you through the process of building a recommendation engine that is collaborative and memory-based. This recommendation engine will recommend movies to users based on what they like and dislike, and will function like the second example that was mentioned before. For this project, we will be using basic set operations, a little mathematics, and Node.js/CoffeeScript. All source code relevant to this tutorial can be found here.
Sets and Equations
Before implementing a collaborative memory-based recommendation engine, we must first understand the core idea behind such a system. To this engine, each item and each user is nothing but identifiers. Therefore, we will not take any other attribute of a movie (for example, the cast, director, genre, etc.) into consideration while generating recommendations. The similarity between two users is represented using a decimal number between -1.0 and 1.0. We will call this number the similarity index. Finally, the possibility of a user liking a movie will be represented using another decimal number between -1.0 and 1.0. Now that we have modelled the world around this system using simple terms, we can unleash a handful of elegant mathematical equations to define the relationship between these identifiers and numbers.
In our recommendation algorithm, we will maintain a number of sets. Each user will have two sets: a set of movies the user likes, and a set of movies the user dislikes. Each movie will also have two sets associated with it: a set of users who liked the movie, and a set of users who disliked the movie. During the stages where recommendations are generated, a number of sets will be produced - mostly unions or intersections of the other sets. We will also have ordered lists of suggestions and similar users for each user.
To calculate the similarity index, we will use a variation of the Jaccard index formula. Originally known as “coefficient de communauté” (coined by Paul Jaccard), the formula compares two sets and produces a simple decimal statistic between 0 and 1.0:
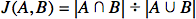
The formula involves the division of the number of common elements in either set by the number of all the elements (counted only once) in both sets. The Jaccard index of two identical sets will always be 1, while the Jaccard index of two sets with no common elements will always yield 0. Now that we know how to compare two sets, let us think of a strategy we can use to compare two users. As discussed earlier, the users, from the system’s point of view, are three things: an identifier, a set of liked movies, and a set of disliked movies. If we were to define our users’ similarity index based only on the set of their liked movies, we could directly use the Jaccard index formula:
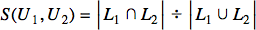
Here, U1 and U2 are the two users we are comparing, and L1 and L2 are the sets of movies that U1 and U2 have liked, respectively. Now, if you think about it, two users liking the same movies are similar, then two users disliking the same movies should also be similar. This is where we modify the equation a little:
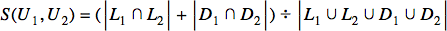
Instead of just considering the common likes in the formula’s numerator, we now add the number of common dislikes as well. In the denominator, we take the number of all the items that either user has liked or disliked. Now that we have considered both likes and dislikes in an independent sort of way, we should also think about the case where two users are polar opposites in their preferences. The similarity index of two users where one likes a movie and the other dislikes it shouldn’t be 0:
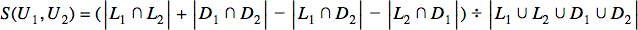
That’s one long formula! But it’s simple, I promise. It’s similar to our previous formula with a small difference in the numerator. We are now subtracting the number of conflicting likes and dislikes of the two users from the number of their common likes and dislikes. This causes the similarity index formula to have a range of values between -1.0 and 1.0. Two users having identical tastes will have a similarity index of 1.0 while two users having entirely conflicting tastes in movies will have a similarity index of -1.0.
Now that we know how to compare two users based on their taste in movies, we have to explore one more formula before we can start implementing our homebrewed recommendation engine algorithm:
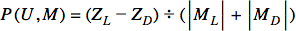
Let’s break this equation down a little. What we mean by P(U,M) is the possibility of a user U liking the movie M. ZL and ZD are the sum of the similarity indices of user U with all the users who have liked or disliked the movie M, respectively. |ML|+|MD| represents the total number of users who have liked or disliked the movie M. The result P(U,M) produces a number between -1.0 and 1.0.
That’s about it. In the next section, we can use these formulae to start implementing our collaborative memory-based recommendation engine.
Building the Recommendation Engine
We will build this recommendation engine as a very simple Node.js application. There will also be very little work on the front-end, mostly some HTML pages and forms (we will use Bootstrap to make the pages look neat). On the server side, we will use CoffeeScript. The application will have a few GET and POST routes. Even though we will have the notion of users in the application, we will not have any elaborate registration/login mechanism. For persistency, we will use the Bourne package available via NPM which enables an application to store data in plain JSON files, and perform basic database queries on them. We will use Express.js to ease the process of managing the routes and handlers.
At this point, if you are new to Node.js development, you might want to clone the GitHub repository so that it’s easier to follow this tutorial. As with any other Node.js project, we will begin by creating a package.json file and installing a set of dependency packages required for this project. If you are using the cloned repository, the package.json file should already be there, from where installing the dependencies will require you to execute “$ npm install”. This will install all the packages listed inside the package.json file.
The Node.js packages we need for this project are:
We will build the recommendation engine by splitting all relevant methods into four separate CoffeeScript classes, each of which will stored under “lib/engine”: Engine, Rater, Similars, and Suggestions. The class Engine will be responsible for providing a simple API for the recommendation engine, and will bind the other three classes together. Rater will be responsible for tracking likes and dislikes (as two separate instances of the Rater class). Similars and Suggestions will be responsible for determining and tracking similar users and recommended items for the users, respectively.
Tracking Likes and Dislikes
Let us first begin with our Raters class. This is a simple one:
class Rater
constructor: (@engine, @kind) ->
add: (user, item, done) ->
remove: (user, item, done) ->
itemsByUser: (user, done) ->
usersByItem: (item, done) ->
As indicated earlier in this tutorial, we will have one instance of Rater for likes, and another one for dislikes. To record that a user likes an item, we will pass them to “Rater#add()”. Similarly, to remove the rating, we will pass them to “Rater#remove()”.
Since we are using Bourne as a server-less database solution, we will store these ratings in a file named “./db-#{@kind}.json”, where kind is either “likes” or “dislikes”. We will open the database inside the constructor of the Rater instance:
constructor: (@engine, @kind) ->
@db = new Bourne "./db-#{@kind}.json"
This will make adding rating records as simple as calling a Bourne database method inside our “Rater#add()” method:
@db.insert user: user, item: item, (err) =>
And it is similar to remove them (“db.delete” instead of “db.insert”). However, before we either add or remove something, we must ensure it doesn’t already exist in the database. Ideally, with a real database, we could have done it as a single operation. With Bourne, we have to do a manual check first; and, once the insertion or deletion is done, we need to make sure we recalculate the similarity indices for this user, and then generate a set of new suggestions. The “Rater#add()” and “Rater#remove()” methods will look something like this:
add: (user, item, done) ->
@db.find user: user, item: item, (err, res) =>
if res.length > 0
return done()
@db.insert user: user, item: item, (err) =>
async.series [
(done) =>
@engine.similars.update user, done
(done) =>
@engine.suggestions.update user, done
], done
remove: (user, item, done) ->
@db.delete user: user, item: item, (err) =>
async.series [
(done) =>
@engine.similars.update user, done
(done) =>
@engine.suggestions.update user, done
], done
For brevity, we will skip the parts where we check for errors. This might be a reasonable thing to do in an article, but is not an excuse for ignoring errors in real code.
The other two methods, “Rater#itemsByUser()” and “Rater#usersByItem()” of this class will involve doing what their names imply - looking up items rated by a user and users who have rated an item, respectively. For example, when Rater is instantiated with kind = “likes”, “Rater#itemsByUser()” will find all the items the user has rated.
Finding Similar Users
Moving on to our next class: Similars. This class will help us compute and keep track of the similarity indices between the users. As discussed before, calculating the similarity between two users involves analyzing the sets of items they like and dislike. To do that, we will rely on the Rater instances to fetch the sets of relevant items, and then determine the similarity index for certain pairs of users using the similarity index formula.
Just like our previous class, Rater, we will put everything in a Bourne database named “./db-similars.json”, which we will open in the constructor of Rater. The class will have a method “Similars#byUser()”, which will let us look up users similar to a given user through a simple database lookup:
@db.findOne user: user, (err, {others}) =>
However, the most important method of this class is “Similars#update()” which works by taking a user and computing a list of other users who are similar, and storing the list in the database, along with their similarity indices. It starts by finding the user’s likes and dislikes:
async.auto
userLikes: (done) =>
@engine.likes.itemsByUser user, done
userDislikes: (done) =>
@engine.dislikes.itemsByUser user, done
, (err, {userLikes, userDislikes}) =>
items = _.flatten([userLikes, userDislikes])
We also find all the users who have rated these items:
async.map items, (item, done) =>
async.map [
@engine.likes
@engine.dislikes
], (rater, done) =>
rater.usersByItem item, done
, done
, (err, others) =>
Next, for each of these other users, we compute the similarity index and store it all in the database:
async.map others, (other, done) =>
async.auto
otherLikes: (done) =>
@engine.likes.itemsByUser other, done
otherDislikes: (done) =>
@engine.dislikes.itemsByUser other, done
, (err, {otherLikes, otherDislikes}) =>
done null,
user: other
similarity: (_.intersection(userLikes, otherLikes).length+_.intersection(userDislikes, otherDislikes).length-_.intersection(userLikes, otherDislikes).length-_.intersection(userDislikes, otherLikes).length) / _.union(userLikes, otherLikes, userDislikes, otherDislikes).length
, (err, others) =>
@db.insert
user: user
others: others
, done
Within the snippet above, you will notice that we have an expression identical in nature to our similarity index formula, a variant of the Jaccard index formula.
Generating Recommendations
Our next class, Suggestions, is where all the predictions take place. Like the class Similars, we rely on another Bourne database named “./db-suggestions.json”, opened inside the constructor.
The class will have a method “Suggestions#forUser()” to lookup computed suggestions for the given user:
forUser: (user, done) ->
@db.findOne user: user, (err, {suggestions}={suggestion: []}) ->
done null, suggestions
The method that will compute these results is “Suggestions#update()”. This method, like “Similars#update()”, will take a user as an argument. The method begins by listing all the users similar to the given user, and all the items the given user has not rated:
@engine.similars.byUser user, (err, others) =>
async.auto
likes: (done) =>
@engine.likes.itemsByUser user, done
dislikes: (done) =>
@engine.dislikes.itemsByUser user, done
items: (done) =>
async.map others, (other, done) =>
async.map [
@engine.likes
@engine.dislikes
], (rater, done) =>
rater.itemsByUser other.user, done
, done
, done
, (err, {likes, dislikes, items}) =>
items = _.difference _.unique(_.flatten items), likes, dislikes
Once we have all the other users and the unrated items listed, we can begin computing a new set of recommendations by removing any previous set of recommendations, iterating over each item, and computing the possibility of the user liking it based on available information:
@db.delete user: user, (err) =>
async.map items, (item, done) =>
async.auto
likers: (done) =>
@engine.likes.usersByItem item, done
dislikers: (done) =>
@engine.dislikes.usersByItem item, done
, (err, {likers, dislikers}) =>
numerator = 0
for other in _.without _.flatten([likers, dislikers]), user
other = _.findWhere(others, user: other)
if other?
numerator += other.similarity
done null,
item: item
weight: numerator / _.union(likers, dislikers).length
, (err, suggestions) =>
Once that is done, we save it back to the database:
@db.insert
user: user
suggestions: suggestions
, done
Exposing the Library API
Inside the Engine class, we bind everything up in a neat API-like structure for easy access from the outside world:
class Engine
constructor: ->
@likes = new Rater @, 'likes'
@dislikes = new Rater @, 'dislikes'
@similars = new Similars @
@suggestions = new Suggestions @
Once we instantiate an Engine object:
e = new Engine
We can easily add or remove likes and dislikes:
e.likes.add user, item, (err) ->
e.dislikes.add user, item, (err) ->
We can also begin updating user similarity indices and suggestions:
e.similars.update user, (err) ->
e.suggestions.update user, (err) ->
Finally, it is important to export this Engine class (and all the other classes) from their respective “.coffee” files:
module.exports = Engine
Then, export the Engine from the package by creating an “index.coffee” file with a single line:
module.exports = require './engine'
Creating the User Interface
To be able to use the recommendation engine algorithm in this tutorial, we want to provide a simple user interface over the web. To do that, we spawn an Express app inside our “web.iced” file and handle a few routes:
movies = require './data/movies.json'
Engine = require './lib/engine'
e = new Eengine
app = express()
app.set 'views', "#{__dirname}/views"
app.set 'view engine', 'jade'
app.route('/refresh')
.post(({query}, res, next) ->
async.series [
(done) =>
e.similars.update query.user, done
(done) =>
e.suggestions.update query.user, done
], (err) =>
res.redirect "/?user=#{query.user}"
)
app.route('/like')
.post(({query}, res, next) ->
if query.unset is 'yes'
e.likes.remove query.user, query.movie, (err) =>
res.redirect "/?user=#{query.user}"
else
e.dislikes.remove query.user, query.movie, (err) =>
e.likes.add query.user, query.movie, (err) =>
if err?
return next err
res.redirect "/?user=#{query.user}"
)
app.route('/dislike')
.post(({query}, res, next) ->
if query.unset is 'yes'
e.dislikes.remove query.user, query.movie, (err) =>
res.redirect "/?user=#{query.user}"
else
e.likes.remove query.user, query.movie, (err) =>
e.dislikes.add query.user, query.movie, (err) =>
res.redirect "/?user=#{query.user}"
)
app.route('/')
.get(({query}, res, next) ->
async.auto
likes: (done) =>
e.likes.itemsByUser query.user, done
dislikes: (done) =>
e.dislikes.itemsByUser query.user, done
suggestions: (done) =>
e.suggestions.forUser query.user, (err, suggestions) =>
done null, _.map _.sortBy(suggestions, (suggestion) -> -suggestion.weight), (suggestion) =>
_.findWhere movies, id: suggestion.item
, (err, {likes, dislikes, suggestions}) =>
res.render 'index',
movies: movies
user: query.user
likes: likes
dislikes: dislikes
suggestions: suggestions[...4]
)
Within the app, we handle four routes. The index route “/” is where we serve the front-end HTML by rendering a Jade template. Generating the template requires a list of movies, the current user’s username, the user’s likes and dislikes, and the top four suggestions for the user. The source code of the Jade template is left out of the article, but it is available in the GitHub repository.
The “/like” and “/dislike” routes are where we accept POST requests to record the user’s likes and dislikes. Both routes add a rating by first removing any conflicting rating, if necessary. For example, a user liking something they previously disliked will cause the handler to remove the “dislike” rating first. These routes also allow the user to “unlike” or “un-dislike” an item, if desired.
Finally, the “/refresh” route allows the user to regenerate their set of recommendations on demand. Although, this action is automatically performed whenever the user makes any rating to an item.
Test-drive
If you have attempted to implement this application from scratch by following this article, you will need to perform one last step before you can test it. You will need to create a “.json” file at “data/movies.json”, and populate it with some movie data like so:
[
{
"id": "1",
"name": "Transformers: Age of Extinction",
"thumb": {
"url": "//upload.wikimedia.org/wikipedia/en/7/7f/Inception_ver3.jpg"
}
},
// …
]
You may want copy the one available in the GitHub repository, which is pre-populated with a handful of movie names and thumbnail URLs.
Once all the source code is ready and wired together, starting the server process requires the following command to be invoked:
$ npm start
Assuming everything went smoothly, you should see the following text appear on the terminal:
Listening on 5000
Since we have not implemented any true user authentication system, the prototype application relies on only a username picked after visiting “http://localhost:5000”. Once a username has been entered, and the form is submitted, you should be taken to another page with two sections: “Recommended Movies” and “All Movies”. Since we lack the most important element of a collaborative memory-based recommendation engine (data), we will not be able to recommend any movies to this new user.
At this point, you should open another browser window to “http://localhost:5000” and login as a different user there. Like and dislike some movies as this second user. Return to the browser window of the first user and rate some movies as well. Make sure you rate at least a couple of common movies for both users. You should start seeing recommendations immediately.
Improvements
In this algorithm tutorial, what we have built is a prototype recommendation engine. There are certainly ways to improve upon this engine. This section will briefly touch on some areas where improvements are essential for this to be used at a large scale. However, in cases where scalability, stability, and other such properties are required, you should always resort to using a good time-tested solution. Like the rest of the article, the idea here is to provide some insight into how a recommendation engine works. Instead of discussing the obvious flaws of the current method (such as race condition in some of the methods we have implemented), improvements will be discussed at a higher level.
One very obvious improvement here is to use a real database, instead of our file-based solution. The file-based solution may work fine in a prototype at a small scale, but it’s not a reasonable choice at all for real use. One option among many is Redis. Redis is fast, and has special capabilities that are useful when dealing with set-like data structures.
Another issue that we can simply work around is the fact that we are calculating new recommendations every time a user makes or changes their ratings for movies. Instead of doing recalculations on-the-fly in real time, we should queue these recommendation update requests for the users and perform them behind the scene - perhaps setting a timed refresh interval.
Besides these “technical” choices, there are also some strategic choices that can be made to improve the recommendations. As the number of items and users grow, it will become increasingly costly (in terms of time and system resources) to generate recommendations. It is possible to make this faster by choosing only a subset of users to generate recommendations from, instead of processing the entire database every time. For example, if this was a recommendation engine for restaurants, you could limit the similar user set to contain only those users that live in the same city or state.
Other improvements may involve taking a hybrid approach, where recommendations are generated based on both collaborative filtering and content-based filtering. This would be especially good with content such as movies, where the properties of the content is well defined. Netflix, for example, takes this route, recommending movies based on both other users’ activities and the movies’ attributes.
Conclusion
Memory-based collaborative recommendation engine algorithms can be a pretty powerful thing. The one we experimented with in this article may be primitive, but it’s also simple: simple to understand, and simple to build. It may be far from perfect, but robust implementations of recommendation engines, such as Recommendable, are built on similar fundamental ideas.
Like most other computer science problems that involve lots of data, getting correct recommendations is a lot about choosing the right algorithm and appropriate attributes of the content to work on. I hope this article has given you a glimpse into what happens inside a collaborative memory-based recommendation engine when you are using it.
Further Reading on the Toptal Blog:
- The Best UX Designer Portfolios: Inspiring Case Studies and Examples
- Digging Deeper: A Practical Guide to Creative Empathy for Product Design
- A Machine Learning Tutorial With Examples: An Introduction to ML Theory and Its Applications
- Strategic Listening: A Guide to Python Social Media Analysis
- Getting Started With the SRVB Cryptosystem
Dhaka, Dhaka Division, Bangladesh
Member since January 16, 2014
About the author
Mahmud is a software developer with many years of experience and a knack for efficiency, scalability, and stable solutions.