Integración Optimizada de Software: Un Tutorial de Apache Camel
Diseñar una arquitectura de integración de sistemas puede ser una tarea difícil. Y empeora si estás diseñando para software a escala. Un autobús de servicio empresarial puede ser una forma de solucionar los desafíos, pero definitivamente ésta no es la solución más sencilla.
En este artículo, el ingeniero de software freelance de Toptal, Anton Goncharov, nos brinda una descripción detallada de los desafíos de la integración de sistemas y una guía para abordar esos desafíos con Apache Camel.

Diseñar una arquitectura de integración de sistemas puede ser una tarea difícil. Y empeora si estás diseñando para software a escala. Un autobús de servicio empresarial puede ser una forma de solucionar los desafíos, pero definitivamente ésta no es la solución más sencilla.
En este artículo, el ingeniero de software freelance de Toptal, Anton Goncharov, nos brinda una descripción detallada de los desafíos de la integración de sistemas y una guía para abordar esos desafíos con Apache Camel.

Anton has extensive expertise in designing robust and scalable applications. He’s fluent in Java/Spring stack and JavaScript development.
Expertise
El software raramente, si es que existe, tiene en un vacío informativo. Al menos esa es la suposición que los ingenieros de software podemos hacer para la mayoría de las aplicaciones que desarrollamos.
En cualquier escala, cada pieza de software—de una forma u otra—se comunica con otro software por varias razones: para obtener datos de referencia de alguna parte, para enviar señales de monitoreo, para estar en contacto con otros servicios, mientras es parte de un sistema distribuido y más.

En este tutorial aprenderás cuáles son algunos de los mayores desafíos de integrar software de gran tamaño y cómo Apache Camel los resuelve con facilidad.
El Problema: Diseño de Arquitectura para la Integración de Sistemas
Es posible que hayas hecho lo siguiente al menos una vez en la vida de la ingeniería de software:
- Identifica un fragmento de la lógica de negocio que debes iniciar el envío de datos.
- En la misma capa de aplicación, escribe las transformaciones de datos de acuerdo con lo que espera el destinatario.
- Envuelve los datos en una estructura que sea adecuada para transferir y enrutar a través de una red.
- Abre una conexión a una aplicación de destino utilizando un controlador apropiado o un SDK de cliente.
- Envía los datos y maneja la respuesta.
¿Por qué es esta una mala línea de acción?
Si bien solo tienes unas pocas conexiones de este tipo, sigue siendo manejable. Con un número creciente de relaciones entre sistemas, la lógica de negocios de la aplicación se mezcla con la lógica de integración que trata de adaptar datos, compensar las diferencias tecnológicas entre dos sistemas y transferir datos al sistema externo con SOAP, REST o solicitudes más exóticas.
Si estuvieras integrando varias aplicaciones, sería increíblemente difícil volver a trazar la imagen completa de las dependencias en dicho código: ¿Dónde se producen los datos y qué servicios los consumen? Tendrás muchos lugares donde la lógica de integración está duplicada para arrancar.
Con este enfoque, aunque la tarea se realiza técnicamente, terminamos con grandes problemas con la capacidad de mantenimiento y la escalabilidad de la integración. La rápida reorganización de los flujos de datos en este sistema es casi imposible, por no mencionar problemas más profundos como la falta de monitoreo, la interrupción de circuitos, la laboriosa recuperación de datos, etc.
Esto es especialmente importante cuando se integra software en el ámbito de una empresa considerablemente grande. Hacer frente a la integración empresarial significa trabajar con un conjunto de aplicaciones que operan en una amplia gama de plataformas y se encuentran en diferentes ubicaciones. El intercambio de datos en un entorno de software de este tipo es bastante exigente. Debe cumplir con los estándares de alta seguridad de la industria y proporcionar una forma confiable de transferir datos. En un entorno empresarial, la integración de sistemas requiere un diseño de arquitectura separado y completamente elaborado.
Este artículo te presentará las dificultades únicas que enfrenta la integración de software y brindará algunas soluciones basadas en la experiencia para tareas de integración. Nos familiarizaremos con Apache Camel, un marco útil que puede aliviar los peores aspectos del dolor de cabeza de un desarrollador de integración. Seguiremos con un ejemplo de cómo Camel puede ayudar a establecer la comunicación en un clúster de microservicios impulsados por Kubernetes.
Dificultades de Integración
Un enfoque ampliamente utilizado para resolver el problema es desacoplar una capa de integración en tu aplicación. Puede existir dentro de la misma aplicación o como una pieza de software dedicada que se ejecuta de forma independiente—en este último caso se denomina middleware.
¿Qué problemas enfrentas normalmente cuando desarrollas y soportas middleware? En general, tiene los siguientes elementos clave:
-
Todos los canales de datos no son confiables en cierta medida. Los problemas derivados de esta falta de fiabilidad pueden no producirse mientras la intensidad de los datos sea baja o moderada. Cada nivel de almacenamiento desde la memoria de la aplicación hasta los cachés inferiores y el equipo que se encuentra debajo está sujeto a posibles fallas. Algunos errores raros surgen solo con grandes volúmenes de datos. Incluso los productos maduros de proveedores listos para producción tienen problemas de seguimiento de errores no resueltos relacionados con la pérdida de datos. Un sistema de middleware debería poder informarle sobre estas víctimas de datos y reenviar el mensaje de suministro de manera oportuna.
-
Las aplicaciones usan diferentes protocolos y formatos de datos. Esto significa que un sistema de integración es una cortina para transformaciones de datos y adaptadores para otros participantes y utiliza una variedad de tecnologías. Estos pueden incluir llamadas de API REST simples, pero también podrían tener acceso a un intermediario de colas, enviar órdenes CSV a través de FTP o datos de extracción de lotes a una tabla de base de datos. Esta es una larga lista y nunca se acortará.
-
Los cambios en los formatos de datos y las reglas de enrutamiento son inevitables. Cada paso en el proceso de desarrollo de una aplicación, que cambia la estructura de datos, generalmente conduce a cambios en los formatos de datos de integración y las transformaciones. A veces los cambios de infraestructura con los flujos de datos reorganizados de la empresa son necesarios. Por ejemplo, estos cambios pueden ocurrir cuando se introduce un único punto de validación de datos de referencia que debe procesar todas las entradas de datos maestros en toda la empresa. Con los sistemas
N, podemos terminar teniendo un máximo de casi conexionesN^2entre ellos, por lo que la cantidad de lugares donde los cambios deben aplicarse crece bastante rápido. Será como una avalancha. Para mantener la capacidad de mantenimiento, una capa de middleware debe proporcionar una imagen clara de las dependencias con un enrutamiento y una transformación de datos versátiles.
Estas ideas deben tenerse en cuenta al diseñar la integración y elegir la solución de middleware más adecuada. Una de las formas posibles de manejarlo es aprovechar un bus de servicio empresarial (ESB). Pero los ESB proporcionados por los principales proveedores generalmente son demasiado pesados y con frecuencia son muy problemáticos: es casi imposible comenzar rápidamente con un ESB, tiene una curva de aprendizaje bastante empinada y su flexibilidad se sacrifica a una larga lista de características y herramientas incorporadas. En mi opinión, las soluciones livianas de integración de código abierto son muy superiores: son más elásticas, fáciles de implementar en la nube y fáciles de escalar.
La integración del software no es fácil de hacer. Hoy, a medida que construimos arquitecturas de microservicios y nos ocupamos de enjambres de pequeños servicios, también tenemos grandes expectativas de cuán eficientemente deben comunicarse.
Patrones de Integración Empresarial
Como era de esperar, como el desarrollo de software en general, el desarrollo del enrutamiento y la transformación de datos implica operaciones repetitivas. La experiencia en esta área ha sido resumida y sistematizada por profesionales que manejan problemas de integración desde hace bastante tiempo. En el resultado, hay un conjunto de plantillas extraídas llamadas patrones de integración empresarial utilizado para diseñar flujos de datos. Estos métodos de integración fueron descritos en el libro del mismo nombre por Gregor Hophe y Bobby Wolfe, que es muy parecido al significativo libro de Gang of Four, pero en el área de software de pegado.
Para dar un ejemplo, el patrón de normalizador introduce un componente que mapea semánticamente mensajes iguales que tienen diferentes formatos de datos para un único modelo canónico, o el agregador es un EIP que combina una secuencia de mensajes en uno.
Dado que se trata de abstracciones tecnológicamente independientes que se utilizan para resolver problemas arquitectónicos, los EIP ayudan a redactar un diseño de arquitectura que no profundiza en el nivel del código sino que describe los flujos de datos con suficiente detalle. Tal notación para describir las rutas de integración no solo hace que el diseño sea conciso sino que también establece una nomenclatura común y un lenguaje común, que son muy importantes en el contexto de la solución de una tarea de integración con los miembros del equipo de diversas áreas comerciales
Presentando Apache Camel
Hace varios años, estaba construyendo una integración empresarial en una gran red minorista de comestibles con tiendas en ubicaciones ampliamente distribuidas. Comencé con una solución propietaria de ESB que resultó ser demasiado engorrosa de mantener. Entonces, nuestro equipo se encontró con Apache Camel y después de hacer un trabajo de “prueba de concepto”, rápidamente reescribimos todos nuestros flujos de datos en las rutas de Camel.
Apache Camel se puede describir como un “enrutador de mediación”, un marco de middleware orientado a mensajes que implementa la lista de EIP, con lo que me familiaricé. Hace uso de estos patrones, admite todos los protocolos de transporte comunes y tiene un amplio conjunto de adaptadores útiles incluidos. Camel permite el manejo de una serie de rutinas de integración sin necesidad de escribir su propio código.
Aparte de esto, destacaría las siguientes características de Apache Camel:
- Las rutas de integración se escriben como tuberías hechas de bloques. Crea una imagen totalmente transparente para ayudar a rastrear los flujos de datos.
- Camel tiene adaptadores para muchas API populares. Por ejemplo, obtener datos de Apache Kafka, supervisar las instancias de AWS EC2, integrarse con Salesforce: todas estas tareas se pueden resolver utilizando componentes disponibles listos para usar.
Las rutas de Apache Camel se pueden escribir en Java o Scala DSL. (Una configuración XML también está disponible pero se vuelve demasiado detallada y tiene peores capacidades de depuración). No impone restricciones en la pila tecnológica de los servicios de comunicación pero si escribe en Java o Scala, puede incrustar Camel en una aplicación en lugar de ejecutarlo de forma independiente.
La notación de enrutamiento utilizada por Camel se puede describir con el siguiente pseudocódigo simple:
from(Source)
.transform(Transformer)
.to(Destination)
La Fuente, Transformador, y Destino son los puntos finales que hacen referencia a los componentes de implementación por sus URI.
¿Qué le permite a Camel resolver los problemas de integración que describí anteriormente? Echemos un vistazo. En primer lugar, la lógica de enrutamiento y transformación ahora sólo se encuentra en una configuración de Apache Camel dedicada. En segundo lugar, a través de la DSL concisa y natural junto con el uso de EIP, aparece una imagen de las dependencias entre los sistemas. Está hecho de abstracciones comprensibles, y la lógica de enrutamiento es fácilmente ajustable. Y, por último, no tenemos que escribir montones de código de transformación porque los adaptadores apropiados probablemente ya estén incluidos.
Debo añadir que Apache Camel es un marco maduro y recibe actualizaciones periódicas. Tiene una gran comunidad y una considerable base de conocimientos acumulada.
Tiene sus propias desventajas. Camel no debe tomarse como una suite de integración compleja. Es una caja de herramientas sin funciones de alto nivel, como herramientas de gestión de procesos de negocio o monitores de actividad pero se puede usar para crear dicho software.
Los sistemas alternativos pueden ser, por ejemplo, Spring Integration o Mule ESB. Para Spring Integration, aunque se considera ligero, en mi experiencia, armarlo y escribir muchos archivos de configuración XML puede resultar inesperadamente complicado y no es una salida fácil. Mule ESB es un conjunto de herramientas robusto y muy funcional, pero como su nombre lo indica, es un bus de servicio empresarial, por lo que pertenece a una categoría de peso diferente. Mule se puede comparar con Fuse ESB, un producto similar basado en Apache Camel con un amplio conjunto de características. Para mí, utilizar Apache Camel para pegar servicios hoy en día es una tarea obvia. Es fácil de usar y produce una descripción clara de lo que pasa, al mismo tiempo, es lo suficientemente funcional para construir integraciones complejas.
Escribir una Ruta de Muestra
Comencemos a escribir el código. Comenzaremos por un flujo de datos sincrónico que enruta los mensajes de una sola fuente a una lista de destinatarios. Las reglas de enrutamiento se escribirán en Java DSL.
Usaremos Maven para construir el proyecto. Primero agrega la siguiente dependencia al pom.xml:
<dependencies>
...
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-core</artifactId>
<version>2.20.0</version>
</dependency>
</dependencies>
Alternativamente, la aplicación se puede construir encima del arquetipo camel-archetype-java.
Las definiciones de ruta de Camel se declaran en el método RouteBuilder.configure.
public void configure() {
errorHandler(defaultErrorHandler().maximumRedeliveries(0));
from("file:orders?noop=true").routeId("main")
.log("Incoming File: ${file:onlyname}")
.unmarshal().json(JsonLibrary.Jackson, Order.class) // unmarshal JSON to Order class containing List<OrderItem>
.split().simple("body.items") // split list to process one by one
.to("log:inputOrderItem")
.choice()
.when().simple("${body.type} == 'Drink'")
.to("direct:bar")
.when().simple("${body.type} == 'Dessert'")
.to("direct:dessertStation")
.when().simple("${body.type} == 'Hot Meal'")
.to("direct:hotMealStation")
.when().simple("${body.type} == 'Cold Meal'")
.to("direct:coldMealStation")
.otherwise()
.to("direct:others");
from("direct:bar").routeId("bar").log("Handling Drink");
from("direct:dessertStation").routeId("dessertStation").log("Handling Dessert");
from("direct:hotMealStation").routeId("hotMealStation").log("Handling Hot Meal");
from("direct:coldMealStation").routeId("coldMealStation").log("Handling Cold Meal");
from("direct:others").routeId("others").log("Handling Something Other");
}
En esta definición, creamos una ruta que recupera los registros del archivo JSON, los divide en elementos y enruta a un conjunto de controladores en función del contenido del mensaje.
Vamos a ejecutarlo en los datos de prueba preparados. Obtendremos la salida:
INFO | Total 6 routes, of which 6 are started
INFO | Apache Camel 2.20.0 (CamelContext: camel-1) started in 10.716 seconds
INFO | Incoming File: order1.json
INFO | Exchange[ExchangePattern: InOnly, BodyType: com.antongoncharov.camel.example.model.OrderItem, Body: OrderItem{id='1', type='Drink', name='Americano', qty='1'}]
INFO | Handling Drink
INFO | Exchange[ExchangePattern: InOnly, BodyType: com.antongoncharov.camel.example.model.OrderItem, Body: OrderItem{id='2', type='Hot Meal', name='French Omelette', qty='1'}]
INFO | Handling Hot Meal
INFO | Exchange[ExchangePattern: InOnly, BodyType: com.antongoncharov.camel.example.model.OrderItem, Body: OrderItem{id='3', type='Hot Meal', name='Lasagna', qty='1'}]
INFO | Handling Hot Meal
INFO | Exchange[ExchangePattern: InOnly, BodyType: com.antongoncharov.camel.example.model.OrderItem, Body: OrderItem{id='4', type='Hot Meal', name='Rice Balls', qty='1'}]
INFO | Handling Hot Meal
INFO | Exchange[ExchangePattern: InOnly, BodyType: com.antongoncharov.camel.example.model.OrderItem, Body: OrderItem{id='5', type='Dessert', name='Blueberry Pie', qty='1'}]
INFO | Handling Dessert
Como era de esperar, Camel envió mensajes a los destinos.
Opciones de Transferencia de Datos
En el ejemplo anterior, la interacción entre componentes es sincrónica y se realiza a través de la memoria de la aplicación. Sin embargo, hay muchas más formas de comunicarse cuando manejamos aplicaciones separadas que no comparten memoria:
- Intercambio de archivos. Una aplicación produce archivos de datos compartidos para que el otro los consuma. Es donde vive el espíritu de la vieja escuela. Este método de comunicación tiene una plétora de consecuencias: falta de transacciones y consistencia, bajo rendimiento y coordinación aislada entre sistemas. Muchos desarrolladores terminaron escribiendo soluciones de integración caseras para hacer que el proceso sea más o menos manejable.
- Base de datos común. Haz que las aplicaciones almacenen los datos que desean compartir en un esquema común de una única base de datos. Diseñar un esquema unificado y manejar el acceso concurrente a las tablas son los desafíos más importantes de este enfoque. Al igual que con el intercambio de archivos, es fácil que esto se convierta en un cuello de botella permanente.
- Llamada de API remota. Proporciona una interfaz para permitir que una aplicación interactúe con otra aplicación en ejecución, como una llamada de método típica. Las aplicaciones comparten funcionalidad a través de invocaciones de API, pero las vinculas estrechamente en el proceso.
- Mensajería. Haz que cada aplicación se conecte a un sistema de mensajería común e intercambie datos e invoque el comportamiento de forma asíncrona mediante mensajes. Ni el remitente ni el destinatario deben estar en funcionamiento al mismo tiempo para entregar el mensaje.
Hay más formas de interactuar, pero debemos tener en cuenta que, en términos generales, existen dos tipos de interacción: sincrónica y asincrónica. El primero es como llamar a una función en su código: el flujo de ejecución estará esperando hasta que se ejecute y devuelva un valor. Con un enfoque asincrónico, los mismos datos se envían a través de una cola de mensajes intermedia o un tema de suscripción. Se puede implementar una llamada a función remota asíncrona como EIP solicitud-respuesta.
Sin embargo, la mensajería asíncrona no es un remedio; implica ciertas restricciones. Raramente ves API de mensajería en la web; Los servicios REST sincrónicos son mucho más populares. Pero el middleware de mensajería se usa ampliamente en intranet empresarial o infraestructura de back-end del sistema distribuido.
Uso de Colas de Mensajes
Hagamos nuestro ejemplo asincrónico. Un sistema de software que gestiona colas y temas de suscripción se llama agente de mensajes. Es como un Sistema de Gestión de Bases de Datos Relacionables (RDBMS) para tablas y columnas. Las colas funcionan como una integración punto a punto, mientras que los temas son para la comunicación publicación-suscripción con muchos destinatarios. Usaremos Apache ActiveMQ como intermediario de mensajes JMS porque es sólido e incrustable.
Agrega la siguiente dependencia. A veces es excesivo agregar activemq-all, que contiene todos los archivos jar de ActiveMQ, para el proyecto, pero mantendremos las dependencias de nuestra aplicación sin complicaciones.
<dependency>
<groupId>org.apache.activemq</groupId>
<artifactId>activemq-all</artifactId>
<version>5.15.2</version>
</dependency>
Luego inicia el intermediario programáticamente. En Spring Boot, tenemos una autoconfiguración para esto al conectar la Dependencia Maven. spring-boot-starter-activemq.
Ejecuta un nuevo intermediario de mensajes con los siguientes comandos, especificando sólo el punto final del conector:
BrokerService broker = new BrokerService();
broker.addConnector("tcp://localhost:61616");
broker.start();
Y agrega el siguiente fragmento de configuración al cuerpo del método configure:
ConnectionFactory connectionFactory = new ActiveMQConnectionFactory("tcp://localhost:61616");
this.getContext().addComponent("activemq", ActiveMQComponent.jmsComponent(connectionFactory));
Ahora podemos actualizar el ejemplo anterior usando colas de mensajes. Las colas se crearán automáticamente en la entrega de mensajes.
public void configure() {
errorHandler(defaultErrorHandler().maximumRedeliveries(0));
ConnectionFactory connectionFactory = new ActiveMQConnectionFactory("tcp://localhost:61616");
this.getContext().addComponent("activemq", ActiveMQComponent.jmsComponent(connectionFactory));
from("file:orders?noop=true").routeId("main")
.log("Incoming File: ${file:onlyname}")
.unmarshal().json(JsonLibrary.Jackson, Order.class) // unmarshal JSON to Order class containing List<OrderItem>
.split().simple("body.items") // split list to process one by one
.to("log:inputOrderItem")
.choice()
.when().simple("${body.type} == 'Drink'")
.to("activemq:queue:bar")
.when().simple("${body.type} == 'Dessert'")
.to("activemq:queue:dessertStation")
.when().simple("${body.type} == 'Hot Meal'")
.to("activemq:queue:hotMealStation")
.when().simple("${body.type} == 'Cold Meal'")
.to("activemq:queue:coldMealStation")
.otherwise()
.to("activemq:queue:others");
from("activemq:queue:bar").routeId("barAsync").log("Drinks");
from("activemq:queue:dessertStation").routeId("dessertAsync").log("Dessert");
from("activemq:queue:hotMealStation").routeId("hotMealAsync").log("Hot Meals");
from("activemq:queue:coldMealStation").routeId("coldMealAsync").log("Cold Meals");
from("activemq:queue:others").routeId("othersAsync").log("Others");
}
Bien, ahora la interacción se ha vuelto asincrónica. Los consumidores potenciales de esta información pueden acceder a ella cuando estén listos para hacerlo. Este es un ejemplo de acoplamiento flexible que tratamos de lograr en una arquitectura reactiva. La falta de disponibilidad de uno de los servicios no bloqueará a los demás. Además, un consumidor puede escalar y leer de la cola en paralelo. La cola en sí misma puede escalar y ser particionada. Las colas persistentes pueden almacenar los datos en el disco, a la espera de ser procesados, incluso cuando todos los participantes se cayeron. En consecuencia, este sistema es más tolerante a las fallas.
Un hecho sorprendente es que CERN usa Apache Camel y ActiveMQ para monitorear los sistemas del Gran Colisionador de Hadrones (LHC). También hay una tesis de maestría interesante que explica la elección de una solución de middleware apropiada para esta tarea. Entonces, como dicen en la parte clave, “Sin JMS—no hay física de partículas!”
Monitorear
En el ejemplo anterior, creamos el canal de datos entre dos servicios. Es un punto de falla potencial adicional en una arquitectura, por lo que debemos cuidarlo. Echemos un vistazo a las funciones de monitoreo que ofrece Apache Camel. Básicamente, expone información estadística sobre sus rutas a través de los MBeans a los que puede acceder JMX. ActiveMQ expone estadísticas de cola de la misma manera.
Vamos a encender el servidor JMX en la aplicación para permitir que se ejecute con las opciones de línea de comando:
-Dorg.apache.camel.jmx.createRmiConnector=true
-Dorg.apache.camel.jmx.mbeanObjectDomainName=org.apache.camel
-Dorg.apache.camel.jmx.rmiConnector.registryPort=1099
-Dorg.apache.camel.jmx.serviceUrlPath=camel
Ahora ejecuta la aplicación para que la ruta haya hecho su trabajo. Abre la herramienta estándar jconsole y conéctate al proceso de solicitud. Conéctate a la URL service:jmx:rmi:///jndi/rmi://localhost:1099/camel. Dirígete al dominio org.apache.camel en el árbol MBeans.
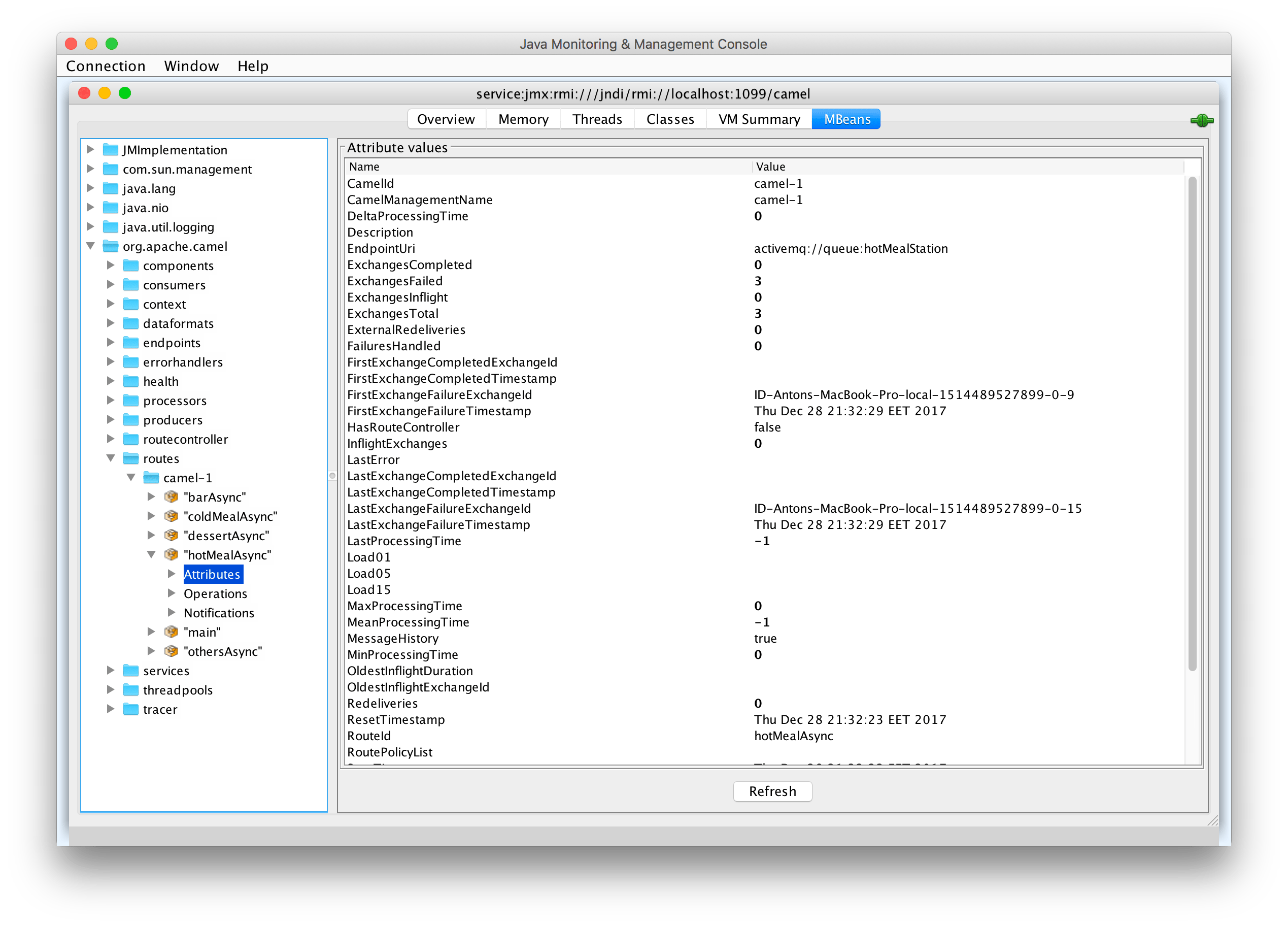
Podemos ver que todo sobre enrutamiento está bajo control. Tenemos el número de mensajes en vuelo, el recuento de errores y el recuento de mensajes en las colas. Esta información se puede canalizar a algún conjunto de herramientas de monitoreo con una gran funcionalidad como Graphana o Kibana. Puedes hacer esto implementando la conocida pila ELK.
También hay una consola web conectable y extensible que proporciona una interfaz de usuario para administrar Camel, ActiveMQ y muchos más, llamada hawt.io.
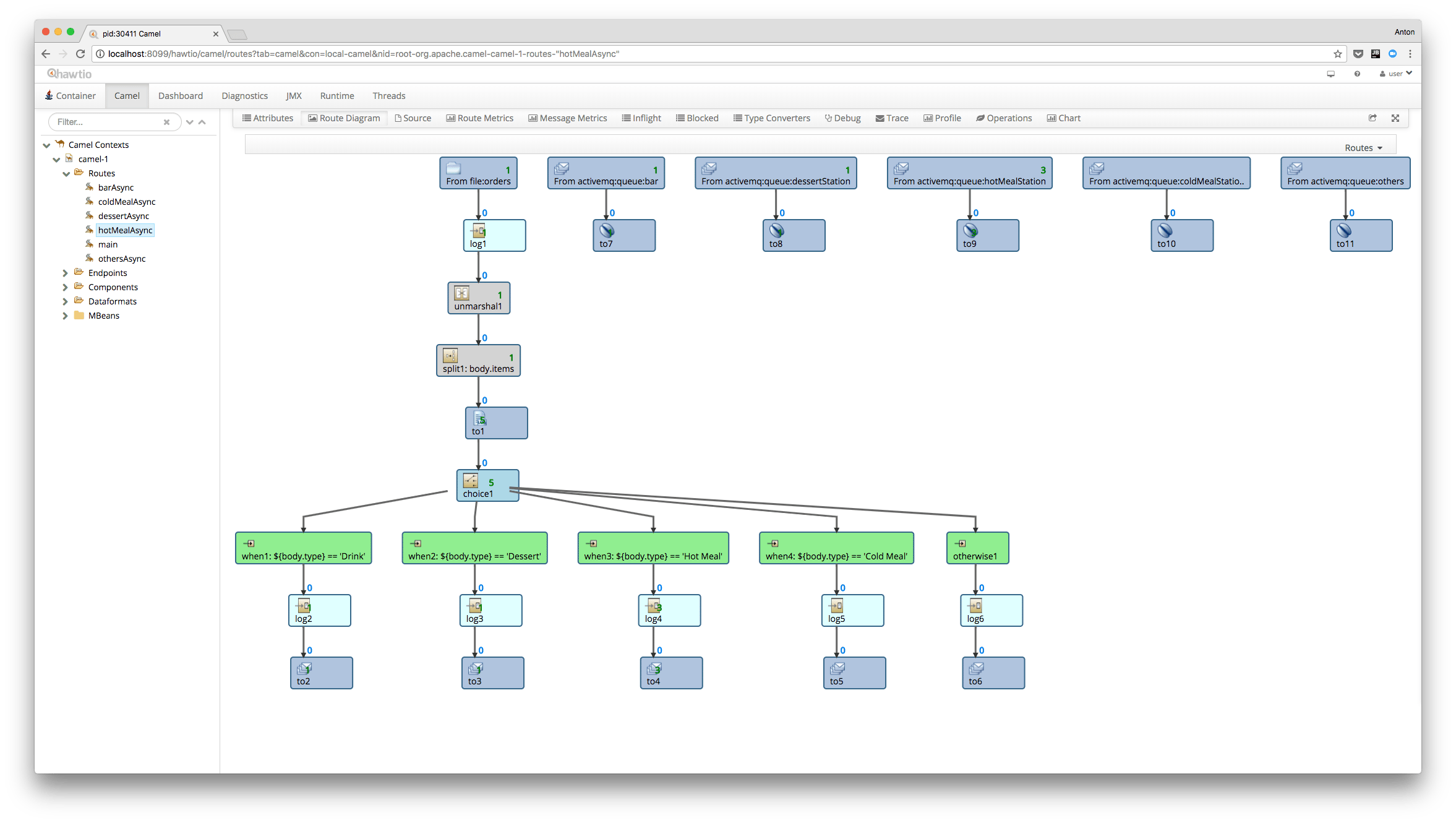
Probando Rutas
Apache Camel tiene una funcionalidad bastante amplia para escribir rutas de prueba con componentes simulados. Es una herramienta poderosa pero escribir rutas separadas solo para las pruebas es un proceso que consume tiempo. Sería más eficiente ejecutar pruebas en las rutas de producción sin modificar su canalización. Camel tiene esta característica y puede implementarse utilizando el componente AdviceWith.
Vamos a habilitar la lógica de prueba en nuestro ejemplo y ejecutar una prueba de muestra.
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-test</artifactId>
<version>2.20.0</version>
<scope>test</scope>
</dependency>
La clase de prueba es:
public class AsyncRouteTest extends CamelTestSupport {
@Override
protected RouteBuilder createRouteBuilder() throws Exception {
return new AsyncRouteBuilder();
}
@Before
public void mockEndpoints() throws Exception {
context.getRouteDefinition("main").adviceWith(context, new AdviceWithRouteBuilder() {
@Override
public void configure() throws Exception {
// we substitute all actual queues with mock endpoints
mockEndpointsAndSkip("activemq:queue:bar");
mockEndpointsAndSkip("activemq:queue:dessertStation");
mockEndpointsAndSkip("activemq:queue:hotMealStation");
mockEndpointsAndSkip("activemq:queue:coldMealStation");
mockEndpointsAndSkip("activemq:queue:others");
// and replace the route's source with test endpoint
replaceFromWith("file://testInbox");
}
});
}
@Test
public void testSyncInteraction() throws InterruptedException {
String testJson = "{\"id\": 1, \"order\": [{\"id\": 1, \"name\": \"Americano\", \"type\": \"Drink\", \"qty\": \"1\"}, {\"id\": 2, \"name\": \"French Omelette\", \"type\": \"Hot Meal\", \"qty\": \"1\"}, {\"id\": 3, \"name\": \"Lasagna\", \"type\": \"Hot Meal\", \"qty\": \"1\"}, {\"id\": 4, \"name\": \"Rice Balls\", \"type\": \"Hot Meal\", \"qty\": \"1\"}, {\"id\": 5, \"name\": \"Blueberry Pie\", \"type\": \"Dessert\", \"qty\": \"1\"}]}";
// get mocked endpoint and set an expectation
MockEndpoint mockEndpoint = getMockEndpoint("mock:activemq:queue:hotMealStation");
mockEndpoint.expectedMessageCount(3);
// simulate putting file in the inbox folder
template.sendBodyAndHeader("file://testInbox", testJson, Exchange.FILE_NAME, "test.json");
//checks that expectations were met
assertMockEndpointsSatisfied();
}
}
Ahora ejecuta pruebas para la aplicación con mvn test. Podemos ver que nuestra ruta se ha ejecutado con éxito con el asesoramiento de prueba. No hay mensajes pasados a través de las colas reales y las pruebas se han pasado.
INFO | Route: main started and consuming from: file://testInbox
<...>
INFO | Incoming File: test.json
<...>
INFO | Asserting: mock://activemq:queue:hotMealStation is satisfied
Usando Apache Camel con Kubernetes Cluster
Uno de los problemas de integración hoy en día es que las aplicaciones ya no son estáticas. En una infraestructura en la nube, trabajamos con servicios virtuales que se ejecutan en múltiples nodos al mismo tiempo. Permite la arquitectura de microservicios con una red de servicios pequeños y livianos que interactúan entre sí. Estos servicios tienen una vida no confiable y tenemos que descubrirlos dinámicamente.
Pegar servicios en la nube en conjunto es una tarea que se puede resolver con Apache Camel. Es especialmente interesante por el sabor de EIP y el hecho de que Camel tiene muchos adaptadores y admite una amplia gama de protocolos. La versión reciente 2.18 agrega el componente ServiceCall, que introduce una característica de llamar a una API y resolver su dirección a través de mecanismos de descubrimiento de clúster. Actualmente, es compatible con Consul, Kubernetes, Ribbon, etc. Algunos ejemplos de código, donde ServiceCall está configurado con Consul, se pueden encontrar fácilmente. Usaremos Kubernetes aquí porque es mi solución de clúster favorita.
El esquema de integración será el siguiente:
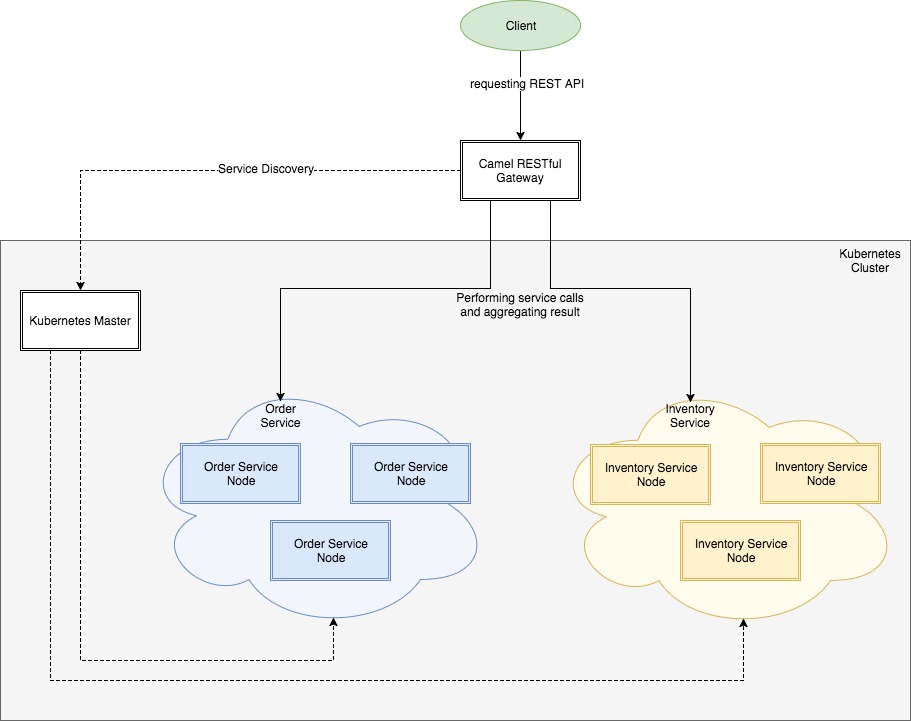
El servicio Order y el servicio Inventory será un par de aplicaciones triviales Spring Boot devolviendo datos estáticos. No estamos atados a una pila de tecnología particular aquí. Estos servicios están produciendo los datos que queremos procesar.
Controlador de Servicio de Orden:
@RestController
public class OrderController {
private final OrderStorage orderStorage;
@Autowired
public OrderController(OrderStorage orderStorage) {
this.orderStorage = orderStorage;
}
@RequestMapping("/info")
public String info() {
return "Order Service UUID = " + OrderApplication.serviceID;
}
@RequestMapping("/orders")
public List<Order> getAll() {
return orderStorage.getAll();
}
@RequestMapping("/orders/{id}")
public Order getOne(@PathVariable Integer id) {
return orderStorage.getOne(id);
}
}
Produce data en el formato:
[{"id":1,"items":[2,3,4]},{"id":2,"items":[5,3]}]
El controlador de servicio Inventory es absolutamente similar al servicio Order:
@RestController
public class InventoryController {
private final InventoryStorage inventoryStorage;
@Autowired
public InventoryController(InventoryStorage inventoryStorage) {
this.inventoryStorage = inventoryStorage;
}
@RequestMapping("/info")
public String info() {
return "Inventory Service UUID = " + InventoryApplication.serviceID;
}
@RequestMapping("/items")
public List<InventoryItem> getAll() {
return inventoryStorage.getAll();
}
@RequestMapping("/items/{id}")
public InventoryItem getOne(@PathVariable Integer id) {
return inventoryStorage.getOne(id);
}
}
InventoryStorage es un repositorio genérico que contiene datos. En este ejemplo, devuelve objetos predefinidos estáticos, que se clasifican según el siguiente formato.
[{"id":1,"name":"Laptop","description":"Up to 12-hours battery life","price":499.9},{"id":2,"name":"Monitor","description":"27-inch, response time: 7ms","price":200.0},{"id":3,"name":"Headphones","description":"Soft leather ear-cups","price":29.9},{"id":4,"name":"Mouse","description":"Designed for comfort and portability","price":19.0},{"id":5,"name":"Keyboard","description":"Layout: US","price":10.5}]
Vamos a escribir una ruta de puerta de enlace que los conecte, pero sin ServiceCall en este paso:
rest("/orders")
.get("/").description("Get all orders with details").outType(TestResponse.class)
.route()
.setHeader("Content-Type", constant("application/json"))
.setHeader("Accept", constant("application/json"))
.setHeader(Exchange.HTTP_METHOD, constant("GET"))
.removeHeaders("CamelHttp*")
.to("http4://localhost:8082/orders?bridgeEndpoint=true")
.unmarshal(formatOrder)
.enrich("direct:enrichFromInventory", new OrderAggregationStrategy())
.to("log:result")
.endRest();
from("direct:enrichFromInventory")
.transform().simple("${null}")
.setHeader("Content-Type", constant("application/json"))
.setHeader("Accept", constant("application/json"))
.setHeader(Exchange.HTTP_METHOD, constant("GET"))
.removeHeaders("CamelHttp*")
.to("http4://localhost:8081/items?bridgeEndpoint=true")
.unmarshal(formatInventory);
Ahora imagina que cada servicio ya no es una instancia específica sino una nube de instancias que funcionan como una sola. Usaremos Minikube para probar el clúster de Kubernetes localmente.
Configura las rutas de la red para ver los nodos de Kubernetes localmente (el ejemplo dado es para un entorno Mac/Linux):
# remove existing routes
sudo route -n delete 10/24 > /dev/null 2>&1
# add routes
sudo route -n add 10.0.0.0/24 $(minikube ip)
# 172.17.0.0/16 ip range is used by docker in minikube
sudo route -n add 172.17.0.0/16 $(minikube ip)
ifconfig 'bridge100' | grep member | awk '{print $2}’
# use interface name from the output of the previous command
# needed for xhyve driver, which I'm using for testing
sudo ifconfig bridge100 -hostfilter en5
Envuelve los servicios en Contenedores Docker con una configuración de Dockerfile como esta:
FROM openjdk:8-jdk-alpine
VOLUME /tmp
ADD target/order-srv-1.0-SNAPSHOT.jar app.jar
ADD target/lib lib
ENV JAVA_OPTS=""
ENTRYPOINT exec java $JAVA_OPTS -Djava.security.egd=file:/dev/./urandom -jar /app.jar
Crea y envía las imágenes del servicio al registro de Docker. Ahora ejecuta los nodos en el clúster local de Kubernetes.
Configuración de implementación de Kubernetes.yaml:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: inventory
spec:
replicas: 3
selector:
matchLabels:
app: inventory
template:
metadata:
labels:
app: inventory
spec:
containers:
- name: inventory
image: inventory-srv:latest
imagePullPolicy: Never
ports:
- containerPort: 8081
Exponer estas implementaciones como servicios en clúster:
kubectl expose deployment order-srv --type=NodePort
kubectl expose deployment inventory-srv --type=NodePort
Ahora podemos verificar si las solicitudes son atendidas por nodos elegidos al azar del clúster. Ejecuta curl -X http://192.168.99.100:30517/info secuencialmente varias veces para acceder al minikube NodePort, para el servicio expuesto (usando tu host y puerto). En el resultado, vemos que hemos logrado equilibrio de solicitudes.
~~~
Inventory Service UUID = 22f8ca6b-f56b-4984-927b-cbf9fcf81da5
Inventory Service UUID = b7a4d326-1e76-4051-a0a6-1016394fafda
Inventory Service UUID = b7a4d326-1e76-4051-a0a6-1016394fafda
Inventory Service UUID = 22f8ca6b-f56b-4984-927b-cbf9fcf81da5
Inventory Service UUID = 50323ddb-3ace-4424-820a-6b4e85775af4
~~~
Agrega las dependencias camel-kubernetes y camel-netty4-http al pom.xml del proyecto. A continuación, configura el componente ServiceCall para usar el descubrimiento de nodo maestro de Kubernetes compartido para todas las llamadas de servicio entre las definiciones de ruta:
KubernetesConfiguration kubernetesConfiguration = new KubernetesConfiguration();
kubernetesConfiguration.setMasterUrl("https://192.168.64.2:8443");
kubernetesConfiguration.setClientCertFile("/Users/antongoncharov/.minikube/client.crt");
kubernetesConfiguration.setClientKeyFile("/Users/antongoncharov/.minikube/client.key");
kubernetesConfiguration.setNamespace("default”);
ServiceCallConfigurationDefinition config = new ServiceCallConfigurationDefinition();
config.setServiceDiscovery(new KubernetesClientServiceDiscovery(kubernetesConfiguration));
context.setServiceCallConfiguration(config);
El ServiceCall EIP complementa bien el Spring Boot. La mayoría de las opciones se pueden configurar directamente en el archivo application.properties.
Potenciar la ruta Camel con el componente ServiceCall:
rest("/orders")
.get("/").description("Get all orders with details").outType(TestResponse.class)
.route()
.hystrix()
.setHeader("Content-Type", constant("application/json"))
.setHeader("Accept", constant("application/json"))
.setHeader(Exchange.HTTP_METHOD, constant("GET"))
.removeHeaders("CamelHttp*")
.serviceCall("customer-srv","http4:customer-deployment?bridgeEndpoint=true")
.unmarshal(formatOrder)
.enrich("direct:enrichFromInventory", new OrderAggregationStrategy())
.to("log:result")
.endRest();
from("direct:enrichFromInventory")
.transform().simple("${null}")
.setHeader("Content-Type", constant("application/json"))
.setHeader("Accept", constant("application/json"))
.setHeader(Exchange.HTTP_METHOD, constant("GET"))
.removeHeaders("CamelHttp*")
.serviceCall("order-srv","http4:order-srv?bridgeEndpoint=true")
.unmarshal(formatInventory);
También activamos el Disyuntor en la ruta. Es un gancho de integración que permite detener llamadas remotas del sistema, en caso de errores de entrega o falta de disponibilidad del destinatario. Esto está diseñado para evitar fallas en el sistema en cascada. El componente Hystrix ayuda a lograr esto implementando el patrón de Disyuntor.
Vamos a ejecutarlo y enviar una solicitud de prueba; obtendremos la respuesta agregada de ambos servicios.
[{"id":1,"items":[{"id":2,"name":"Monitor","description":"27-inch, response time: 7ms","price":200.0},{"id":3,"name":"Headphones","description":"Soft leather ear-cups","price":29.9},{"id":4,"name":"Mouse","description":"Designed for comfort and portability","price":19.0}]},{"id":2,"items":[{"id":5,"name":"Keyboard","description":"Layout: US","price":10.5},{"id":3,"name":"Headphones","description":"Soft leather ear-cups","price":29.9}]}]
El resultado es el esperado.
Otros Casos de Uso
Mostré cómo Apache Camel puede integrar microservicios en un clúster. ¿Cuáles son otros usos de este marco? En general, es útil en cualquier lugar donde el enrutamiento basado en reglas sea una solución. Por ejemplo, Apache Camel puede ser un middleware para el Internet de las cosas con el adaptador Eclipse Kura. Puede manejar la monitorización mediante el transporte de señales de registro de diversos componentes y servicios, como en el sistema CERN. También puede ser un marco de integración para SOA empresarial o ser un portafolio para el procesamiento de datos por lotes, aunque no compite bien con Apache Spark en esta área.
Conclusión
Puedes ver que la integración de sistemas no es un proceso fácil. Tenemos suerte porque se ha acumulado mucha experiencia. Es importante aplicarlo correctamente para crear soluciones flexibles y tolerantes a fallas.
Para asegurar la aplicación correcta, recomiendo tener una lista de verificación de aspectos importantes de integración. Los artículos imprescindibles incluyen:
- ¿Hay una capa de integración separada?
- ¿Hay pruebas de integración?
- ¿Conocemos la intensidad máxima de datos esperada?
- ¿Conocemos el tiempo de entrega de datos esperado?
- ¿Tiene importancia la correlación de mensajes? ¿Qué pasa si una secuencia se rompe?
- ¿Deberíamos hacerlo de forma síncrona o asíncrona?
- ¿Dónde cambian los formatos y las reglas de enrutamiento con más frecuencia?
- ¿Tenemos formas de monitorear el proceso?
En este artículo, probamos Apache Camel, un framework de integración liviano, que ayuda a ahorrar tiempo y esfuerzo al resolver problemas de integración. Como mostramos, puede servir como una herramienta que respalda la arquitectura de microservicios relevante al asumir la total responsabilidad del intercambio de datos entre los microservicios.
Si estás interesado en aprender más sobre Apache Camel, recomiendo mucho el libro “Camel in Action” del creador del framework, Claus Ibsen. La documentación oficial está disponible en camel.apache.org.
Amsterdam, Netherlands
Member since July 29, 2016
About the author
Anton has extensive expertise in designing robust and scalable applications. He’s fluent in Java/Spring stack and JavaScript development.