Introducción al Comercio de Aprendizaje Profundo en Fondos de Cobertura
En este artículo, el Ingeniero Software Freelance de Toptal Neven Pičuljan, te muestra las particularidades del aprendizaje profundo en los fondos de cobertura y la finanza en general.

En este artículo, el Ingeniero Software Freelance de Toptal Neven Pičuljan, te muestra las particularidades del aprendizaje profundo en los fondos de cobertura y la finanza en general.

Co-founder of Poze and CEO of an AI R&D/consulting company, Neven has an MCS degree and has built a face-recognition system in TensorFlow.
Expertise
En los últimos años, las redes neuronales profundas se han vuelto extremadamente populares. Este campo emergente de la ciencia de la computación se creó en torno al concepto de redes neuronales biológicas, y el aprendizaje profundo se ha convertido en una palabra de moda en la actualidad.
Los científicos e ingenieros de aprendizaje profundo intentan describir matemáticamente varios patrones del sistema nervioso biológico. Los sistemas de aprendizaje profundo se han aplicado a varios problemas: visión artificial, reconocimiento de voz, procesamiento del lenguaje natural, traducción automática y más. Es interesante y emocionante que, en algunas tareas, el aprendizaje profundo haya superado a los expertos humanos. Hoy vamos a echar un vistazo al aprendizaje profundo en el sector financiero.
Una de las aplicaciones más atractivas del aprendizaje profundo es en los fondos de cobertura. Los fondos de cobertura son fondos de inversión de organizaciones financieras que recaudan fondos de los inversionistas y los administran. Por lo general trabajan con datos de series de tiempo e intentan hacer algunas predicciones. Existe un tipo especial de arquitectura de aprendizaje profundo que es adecuada para el análisis de series temporales: redes neuronales recurrentes (RNR), o incluso más específicamente, un tipo especial de red neuronal recurrente: redes de memoria larga de corto-plazo (LSTM). Las LSTM son capaces de capturar las características más importantes de los datos de series de tiempo y modelar sus dependencias. Un modelo de predicción del precio de las acciones se presenta como un estudio de caso ilustrativo sobre cómo los fondos de cobertura pueden usar dichos sistemas. El framework PyTorch, escrito en Python, se usa para entrenar el modelo, diseñar experimentos y dibujar los resultados.
Comenzaremos con algunos conceptos básicos de aprendizaje profundo antes de pasar a ejemplos del mundo real:
- Introducir el aprendizaje profundo como un concepto abstracto.
- Introducir RNR—o más específicamente, LSTM—y cómo se pueden usar para modelar datos de series de tiempo.
- Familiarizar a los lectores con los datos financieros adecuados para el aprendizaje profundo.
- Ilustrar cómo un fondo de cobertura real utiliza el aprendizaje profundo para predecir los precios de las acciones.
- Finalmente, proporciona recomendaciones procesables para fondos de cobertura nuevos y existentes sobre cómo utilizar/aprovechar el aprendizaje profundo para aumentar su rendimiento.
Presentación del Caso para el Comercio de Aprendizaje Profundo
Una de las tareas más desafiantes y emocionantes en la industria financiera es predecir si los precios de las acciones subirán o bajarán en el futuro. Hoy en día, somos conscientes de que los algoritmos de aprendizaje profundo son muy buenos para resolver tareas complejas, por lo que vale la pena intentar experimentar con sistemas de aprendizaje profundo para ver si pueden resolver con éxito el problema de predecir los precios futuros.
Como concepto, la red neuronal artificial ha existido durante mucho tiempo, pero el hardware no era lo suficientemente bueno como para permitir experimentos rápidos en aprendizaje profundo. Nvidia ayudó a revolucionar las redes de aprendizaje profundo hace una década ya que comenzó a ofrecer unidades de procesamiento de gráficos (UPG) muy rápidas para computación de uso general en Tesla-series products. En lugar de sombrear polígonos en juegos y aplicaciones de diseño profesional, las UPG altamente paralelizadas también pueden computar otros datos y, en muchos casos, son muy superiores a las CPU.
Hay muy pocos artículos científicos sobre el uso del aprendizaje profundo en las finanzas, pero la demanda de expertos en aprendizaje profundo de las empresas fintech es sólida ya que obviamente reconocen su potencial. Este artículo ayudará a explicar por qué el aprendizaje profundo en finanzas se está volviendo cada vez más popular al delinear cómo se usan los datos financieros en la construcción de sistemas de aprendizaje profundo. Un tipo especial de red neuronal recurrente—la red LSTM—será presentada también. Vamos a delinear cómo una tarea relacionada con las finanzas puede ser resuelta usando redes neuronales recurrentes.
Este artículo también presenta un caso de estudio ilustrativo sobre cómo los fondos de cobertura pueden usar dichos sistemas, presentados a través de experimentos. También consideraremos cómo se pueden mejorar los sistemas de aprendizaje profundo y cómo los fondos de cobertura pueden contratar talento para construir esos sistemas, es decir, qué tipo de experiencia necesita tener el talento de aprendizaje profundo.
Lo que Hace que los Fondos de Cobertura Sean Diferentes
Antes de proceder con el aspecto técnico del problema, debemos explicar qué hace únicos a los fondos de cobertura. Entonces, ¿qué es un fondo de cobertura?
Un fondo de cobertura es un fondo de inversión—una organización financiera que recauda fondos de los inversionistas y los coloca en inversiones a corto y largo plazo, o en diferentes productos financieros. Por lo general, se forma como una sociedad limitada o una sociedad de responsabilidad limitada. El objetivo de un fondo de cobertura es maximizar los rendimientos. Un rendimiento es una ganancia o pérdida en el patrimonio neto de los fondos de cobertura durante un período de tiempo particular. En general, se acepta que cuando se toman más riesgos, existe un mayor potencial de mayores rendimientos y pérdidas.
Para lograr buenos rendimientos, los fondos de cobertura dependen de varios tipos de estrategias de inversión, tratando de ganar dinero al explotar las ineficiencias del mercado. Debido a varios tipos de estrategias de inversión que no están permitidas en los fondos de inversión ordinarios, los fondos de cobertura no se registran como fondos, es decir, generalmente no son supervisados por el estado como otros fondos. No es necesario que publiquen sus estrategias de inversión y resultados comerciales, lo que puede hacer que sean bastante arriesgados. Algunos fondos de cobertura generan más dinero que el promedio del mercado, pero algunos pierden dinero. Algunos de ellos brindan resultados permanentes, mientras que algunos de los resultados de los fondos de cobertura son variables.
Al invertir en fondos de cobertura, los inversionistas aumentan el patrimonio neto del fondo. Sin embargo, no cualquiera puede invertir en fondos de cobertura. Los fondos de cobertura están destinados a un pequeño número de inversionistas adinerados. Por lo general, los que desean participar en los fondos de cobertura deben estar acreditados. Eso significa que deben tener un estado especial con respecto a las leyes de regulación financiera. Hay una distinción de país a país con respecto a quién puede tener ese estado especial. Por lo general, el patrimonio neto de un inversor debe ser muy elevado, no solo los individuos, sino que los bancos y las grandes corporaciones también pueden operar en fondos de cobertura. Esa acreditación está diseñada para permitir que solo participen personas con un importante conocimiento de la inversión, lo que protege del riesgo a los inversionistas pequeños e inexpertos.
Este artículo considera el marco regulatorio de Estados Unidos, ya que Estados Unidos tiene el mercado financiero más desarrollado del mundo. Entonces, en los Estados Unidos, el término “inversionista acreditado” se define en la Regla 501 de la Regulación D de la Comisión de Bolsa y Valores de los Estados Unidos (SEC).
De acuerdo con esta regulación, los inversionistas acreditados pueden ser:
- Bancos
- Empresas privadas de desarrollo empresarial
- Organizaciones
- Directores, ejecutivos y socios generales de los emisores de los valores ofrecidos o vendidos
- Las personas físicas cuyo valor patrimonial individual, o patrimonio conjunto con el cónyuge de esa persona, excede de 1,000,000 de dólares
- Personas físicas que tuvieron un ingreso individual superior a 200,000 dólares en cada uno de los dos años más recientes o ingresos conjuntos con el cónyuge de esa persona en exceso de 300,000 dólares en cada uno de esos años y tienen una expectativa razonable de alcanzar el mismo nivel de ingresos en el presente año
- Fideicomisos con activos totales superiores a 5,000,000 de dólares
- Entidades en las que todos los propietarios de acciones son inversionistas acreditados
Los gerentes de fondos de cobertura administran tal fondo. Un administrador de fondos de cobertura debe encontrar la manera de crear una ventaja competitiva para tener éxito, es decir, crear una ventaja sobre los rivales y la capacidad de generar un mayor valor. Puede ser una opción de carrera muy atractiva ya que puede ser muy rentable si un individuo se destaca en la gestión del fondo.
Por otro lado, si muchas de las decisiones de los administradores de fondos de cobertura resultan ser malas, no se les pagará y obtendrán una reputación negativa. Los mejores gestores de fondos de cobertura conforman una de las profesiones mejor pagadas en todas las industrias. Los gestores de fondos de cobertura obtienen un porcentaje de los rendimientos que obtienen para los inversionistas además de la comisión de gestión. Esta forma de compensación hace que los gestores de fondos de cobertura inviertan más agresivamente para obtener mayores rendimientos pero, por otro lado, eso también conduce a un aumento en el riesgo de los inversionistas.
Una Breve Historia de los Fondos de Cobertura
El primer fondo de cobertura apareció en 1949, establecido por el ex escritor y sociólogo Alfred Winslow Jones. Fue mientras escribía un artículo sobre las tendencias de inversión actuales para Fortune, alrededor de 1948.
Trató de administrar el dinero y tuvo mucho éxito. Recaudó dinero utilizando su innovación de inversión, que ahora es ampliamente conocida como capitalización larga/corta. La estrategia sigue siendo muy popular entre los fondos de cobertura. Las acciones se pueden comprar (comprar: largo) o vender (vender: corto).
Cuando el precio de una acción es bajo y se espera que el precio de una acción sea alto, es lógico comprar una acción (larga) y venderla (en corto) tan pronto como llegue a su punto más alto, y eso es exactamente el punto de la innovación que hizo Alfred Winslow Jones: tomar posiciones largas en acciones que se espera que se aprecien y posiciones cortas en acciones que se espera que disminuyan.
Datos Financieros y Conjuntos de Datos
Los datos financieros pertenecen a los datos de series de tiempo. Una serie temporal es una serie de puntos de datos indexados en el tiempo. Por lo general, una serie de tiempo es una secuencia tomada en puntos sucesivos e igualmente espaciados en el tiempo: una secuencia de datos de tiempo discreto. Ejemplos de series temporales son las alturas de mareas oceánicas, recuentos de manchas solares y el valor de cierre diario del promedio industrial Dow Jones. Los datos históricos en este contexto son datos de series de tiempo del pasado. Es una de las partes más importantes y valiosas para especular sobre los precios futuros. Hay algunos conjuntos de datos disponibles públicamente en línea, pero generalmente—esos datos no contienen muchas características, generalmente son datos de intervalos de 1 día, datos de intervalos de 1 hora o datos de intervalos de 1 minuto.
Los conjuntos de datos con características más ricas y en intervalos de tiempo más pequeños generalmente no están disponibles al público y pueden ser muy costosos de obtener. Intervalos más pequeños significan más datos de series de tiempo en un período fijo—en un año hay 365 (o 366) días, por lo que hay un máximo de 365 (o 366) puntos de datos disponibles. Cada día tiene 24 horas, por lo que en un año hay 8,760 (u 8,784) puntos de datos por hora disponibles, y cada día tiene 86,400 minutos, por lo que en un año hay 525,600 (o 527,040) puntos de datos por minuto disponibles.
Con más datos, hay más información disponible y, con más información, es posible sacar mejores conclusiones sobre lo que sucederá en el próximo período de tiempo, suponiendo, por supuesto, que los datos consten de una característica lo suficientemente buena para generalizar bien. Los datos del precio de las acciones de 2007-2008, en el momento álgido de la crisis financiera mundial, son parciales y probablemente no sean relevantes para hacer predicciones de precios en estos días. Con un intervalo de tiempo más pequeño, es más fácil predecir qué sucederá a continuación debido a una gran cantidad de puntos de datos en un intervalo fijo. Es más fácil predecir lo que sucederá en el próximo nanosegundo si tenemos todos los puntos de datos por cada nanosegundo en un intervalo fijo de n años que lo que sucederá en el mercado de valores el próximo año si tenemos todos los puntos de datos n por cada año en un intervalo fijo de n-años.
Sin embargo, eso no significa que, suponiendo que una serie rápida de predicciones a corto plazo es correcta, la predicción a largo plazo también debería ser correcta. Cada predicción introduce un error y, al encadenar múltiples predicciones, la predicción a largo plazo contendrá una cantidad significativa de error al final y será inútil. A continuación se muestra un ejemplo de datos de intervalo de 1 día para las acciones de Google recortadas en línea de Yahoo Finance.

Hay solo unas pocas columnas en el conjunto de datos: Fecha, Abierto, Alto, Bajo y Cerrar—respectivamente, el precio al que un valor se negocia por primera vez en la apertura de un intercambio, el precio más alto que la seguridad lograda en un determinado día de negociación, el precio más bajo alcanzado en un día de negociación determinado y el precio final al que se negocia un valor ese día.
Por lo general, hay dos columnas más en dichos conjuntos de datos—Cierre ajustado y Volumen, pero no son relevantes aquí. Cierre ajustado es el precio de cierre después de los ajustes por divisiones y distribuciones de dividendos aplicables, mientras que el Volumen es el número de acciones negociadas en el mercado durante un período de tiempo determinado.
Puedes ver que faltan algunas de las fechas. Estos son los días en que la bolsa de valores no está funcionando, generalmente durante los fines de semana y días festivos. A los efectos de nuestra demostración del algoritmo de aprendizaje profundo, los días faltantes se complementan con el precio disponible anteriormente. Por ejemplo, los precios de cierre para 2010-01-16, 2010-01-17, 2010-01-18 serán de 288.126007 porque así fue el 2010-01-15. Es importante para nuestro algoritmo que los datos estén sin brechas para que no lo confundamos. El algoritmo de aprendizaje profundo podría aprender de aquí cuando son los fines de semana y las vacaciones—por ejemplo, aprenderá que después de cinco días hábiles, debe haber dos días con precios fijos desde el último día hábil.
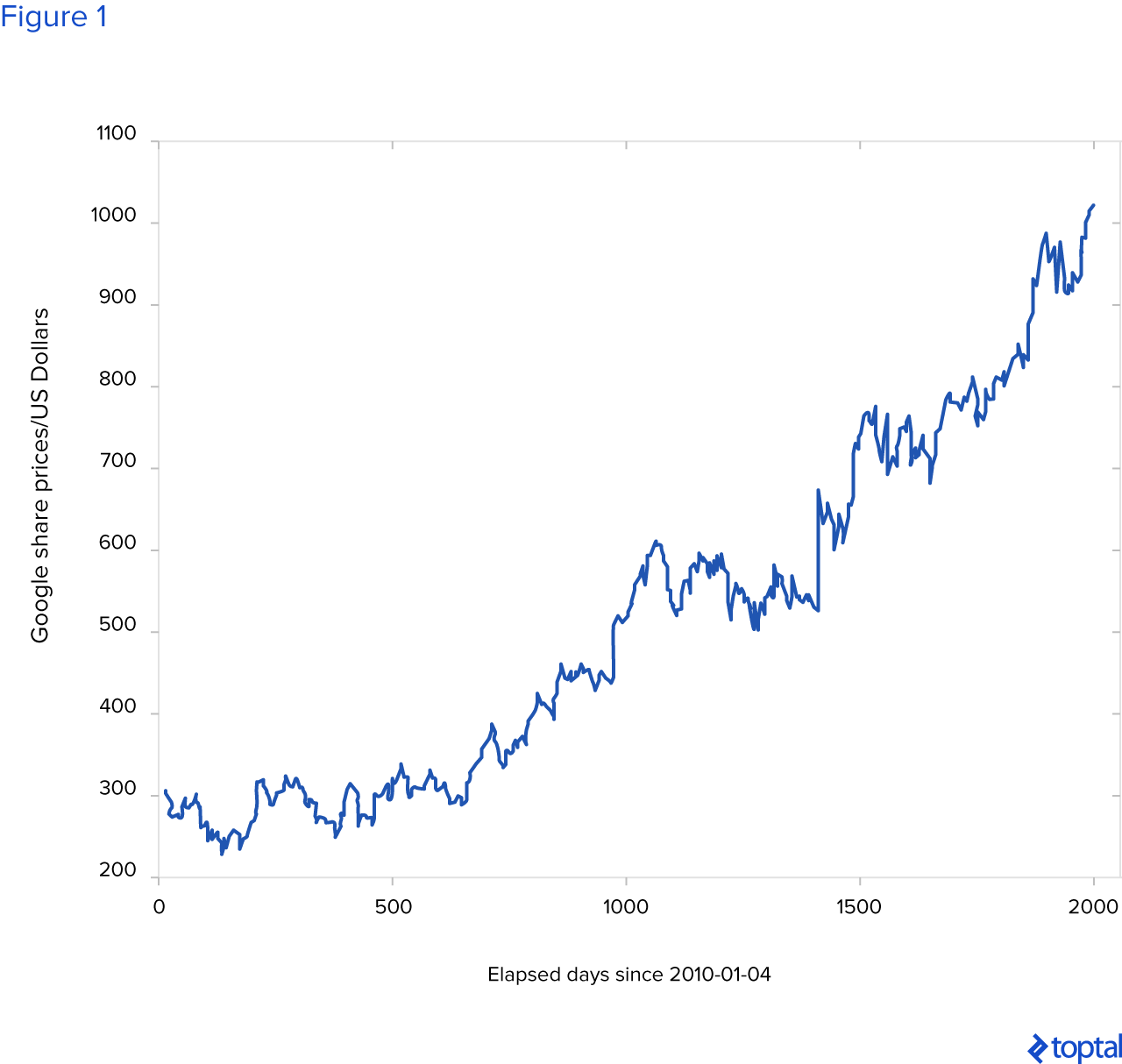
Este es un gráfico de los movimientos de los precios de las acciones de Google desde 2010-01-04. Ten en cuenta que sólo los días de negociación se utilizan para trazar el gráfico.
¿Qué es el Aprendizaje Profundo?
El aprendizaje profundo es parte del aprendizaje automático y se basa en el aprendizaje de representaciones de datos. El aprendizaje automático examina algoritmos cuya funcionalidad no está programada pero se aprende de los datos. Es esencialmente un acercamiento a la inteligencia artificial.
El aprendizaje profundo se ha aplicado a diversos campos: visión artificial, reconocimiento de voz, procesamiento del lenguaje natural, traducción automática—y en algunas de estas tareas, ha logrado un rendimiento superior al de los humanos.
Una red neuronal profunda está en el centro del aprendizaje profundo. El ejemplo más simple y básico de una red neuronal profunda es una red neuronal predictiva. A continuación se muestra una imagen de una red neuronal feedforward simple. Consiste en las capas de entrada y salida y capas ocultas.
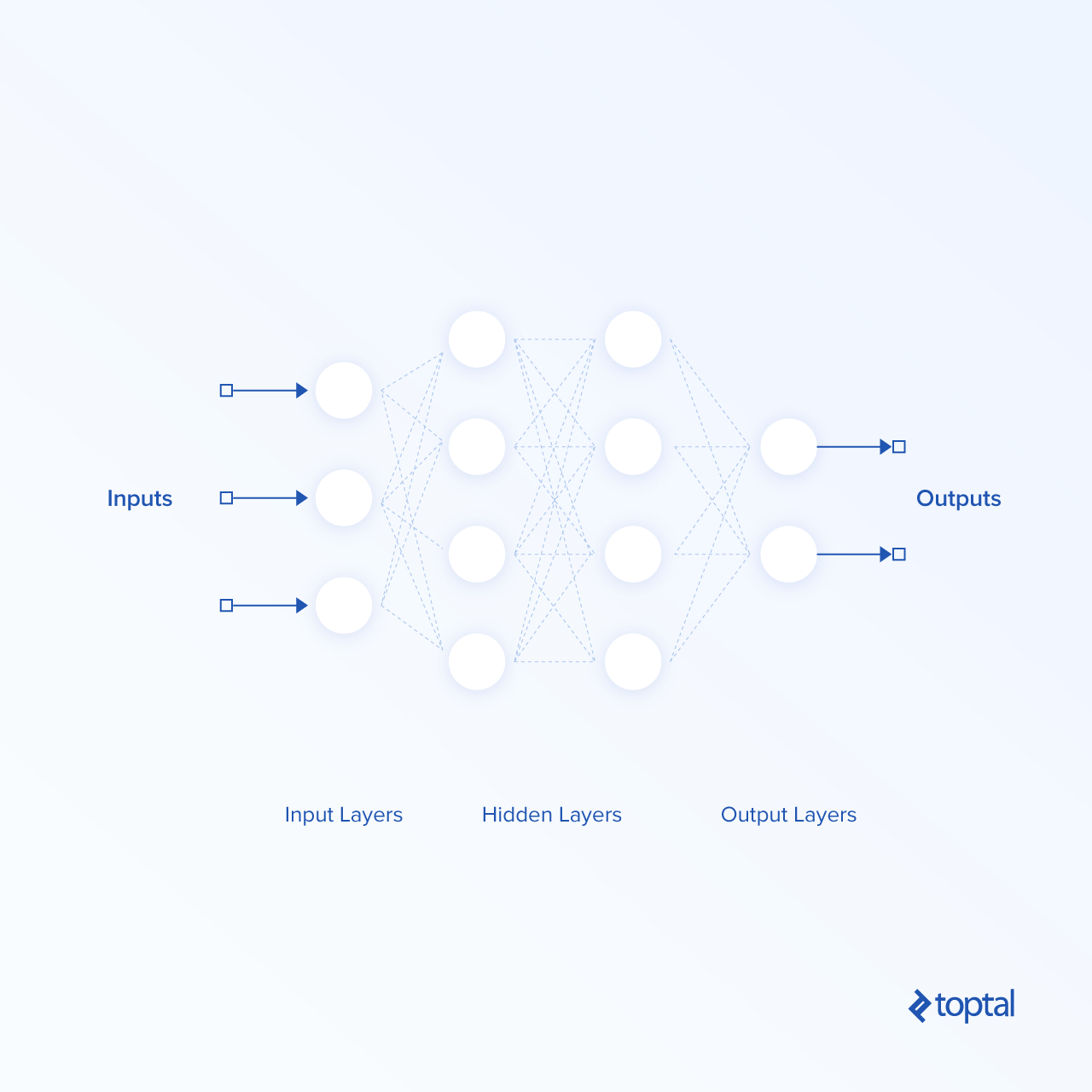
Las capas ocultas son todas capas entre las capas de entrada y salida. Decimos que una red neuronal es profunda si tiene más de una capa oculta. Cada capa está compuesta de varios números de neuronas. Las capas en esta red neuronal básica de avance se denominan capas lineales: las neuronas en la capa lineal sólo multiplican los valores de 1-D (o 2-D si los datos se envían a través de la red en lotes) con el peso apropiado, sumando productos juntos y da el resultado final como salida 1-D o 2-D.
La función de activación generalmente se aplica en las redes de feedforward para introducir no linealidades, por lo que la red puede modelar problemas no lineales más complejos. En las redes de feedforward, los datos fluyen desde la capa de entrada a la capa de salida sin realizar un bucle. Las conexiones entre las neuronas son ponderadas. Los pesos deben ajustarse para que la red neuronal devuelva salidas correctas para las entradas dadas. La red de feedforward mapea los datos del espacio de entrada al espacio de salida. Las capas ocultas extraen características importantes y más abstractas de las características de la capa anterior.
La tubería general de aprendizaje profundo es la misma que la tubería de aprendizaje automático y consta de los siguientes pasos:
- Recopilación de datos. Los datos se separan en tres partes: datos de entrenamiento, datos de validación y datos de prueba.
- Entrenando el DNN usando los datos de entrenamiento sobre un número de “épocas” (cada una de las cuales consiste en varias iteraciones) y validación después de cada época usando los datos de validación.
- Prueba del modelo (una instancia de una red neuronal con parámetros fijos) después de la secuencia de sesiones de entrenamiento y validaciones.
El entrenamiento de la red neuronal en realidad significa ajustar los pesos entre los pares de neuronas al minimizar la función de pérdida utilizando un algoritmo de retropropagación en combinación con el descenso de gradiente estocástico. A excepción de los pesos que se determinan a través del proceso de aprendizaje, los algoritmos de aprendizaje profundo generalmente requieren el establecimiento de los hiperparámetros, parámetros que no se aprenden sino que se reparan antes del aprendizaje. Los hiperparámetros son el número de capas, el número de neuronas en capas, tipos de capas, tipos de neuronas e inicialización de peso.
Hay restricciones de hardware en la configuración de hiperparámetros; actualmente no es físicamente posible establecer un trillón de neuronas en una sola GPU. El segundo problema para la búsqueda exhaustiva de hiperparámetros es la explosión combinatoria; no es posible buscar a través de todas las combinaciones posibles de hiperparámetros porque tomaría un tiempo infinito. Por eso, los hiperparámetros se configuran aleatoriamente o usan algunos heurísticos y ejemplos bien conocidos que se describen en artículos científicos: uno de los hiperparámetros utilizados para el análisis de datos financieros que se muestra más adelante en este blog es el uso de neuronas recurrentes, como científicos e ingenieros han demostrado que funcionan bien con datos de series de tiempo. Por lo general, la mejor manera de ver si los hiperparámetros para un problema determinado son buenos o no es a través de experimentos. El objetivo del entrenamiento es hacer que las redes neuronales se ajusten a los datos de entrenamiento. Tanto la validación del modelo que se realiza después de cada paso de capacitación, como la prueba del modelo que se realiza después del procedimiento de entrenamiento completo, se realizan para ver si el modelo se puede generalizar bien. La generalización significa que la red neuronal puede hacer buenas predicciones sobre datos nuevos no vistos.
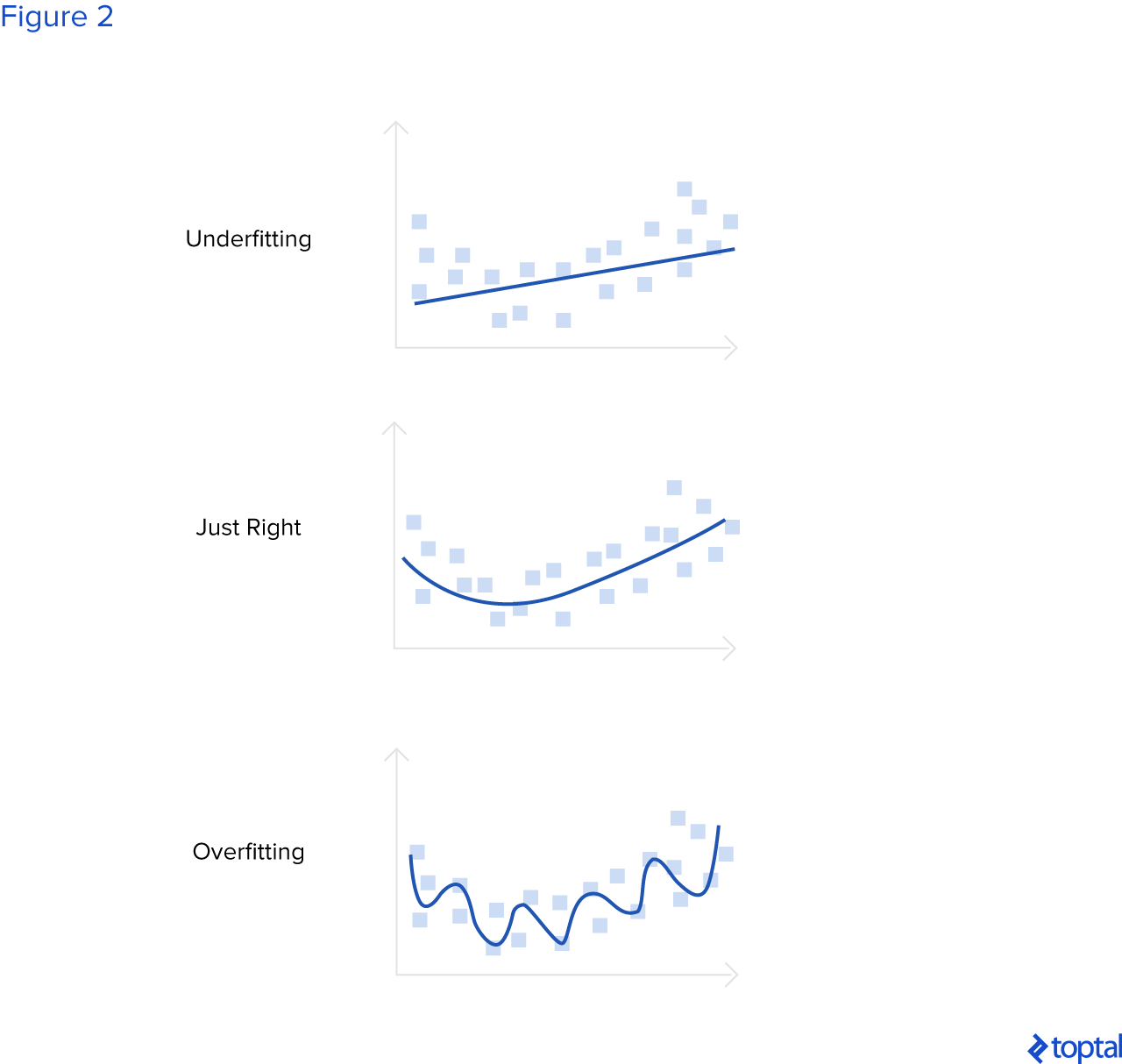
Hay dos términos importantes relacionados con la selección del modelo: sobreajuste y desajuste. Si una red neuronal es demasiado compleja con respecto a los datos en los que está entrenada, si tiene demasiados parámetros (demasiadas capas y/o demasiadas neuronas en capas), la red neuronal puede sobreajustar los datos. Puede ajustarse bien a los datos de capacitación porque tiene capacidad más que suficiente para ajustarse a todos los datos, pero luego el rendimiento en los conjuntos de validación y prueba es pobre.
Si la red neuronal es demasiado simple con respecto a los datos en los que está capacitada, la red neuronal puede desajustar los datos. En ese caso, la red neuronal tiene un rendimiento deficiente en los conjuntos de entrenamiento, validación y prueba porque su capacidad no es lo suficientemente buena como para adaptarse a los datos de entrenamiento y generalizar. En la imagen a continuación, esos términos se explican gráficamente. La línea azul representa lo que está modelado por la red neuronal. La primera imagen muestra la situación cuando hay pocos parámetros de red neuronal, no lo suficiente para adaptarse a los datos de entrenamiento y para generalizar. La segunda imagen muestra la situación cuando existe el número óptimo de parámetros y la red neuronal puede generalizarse bien en datos no vistos, y la tercera imagen muestra la situación cuando el número de parámetros de una red neuronal es demasiado grande y la red neuronal puede perfectamente ajustar todos los datos del conjunto de entrenamiento, pero tiene un rendimiento bajo en los conjuntos de validación y prueba.
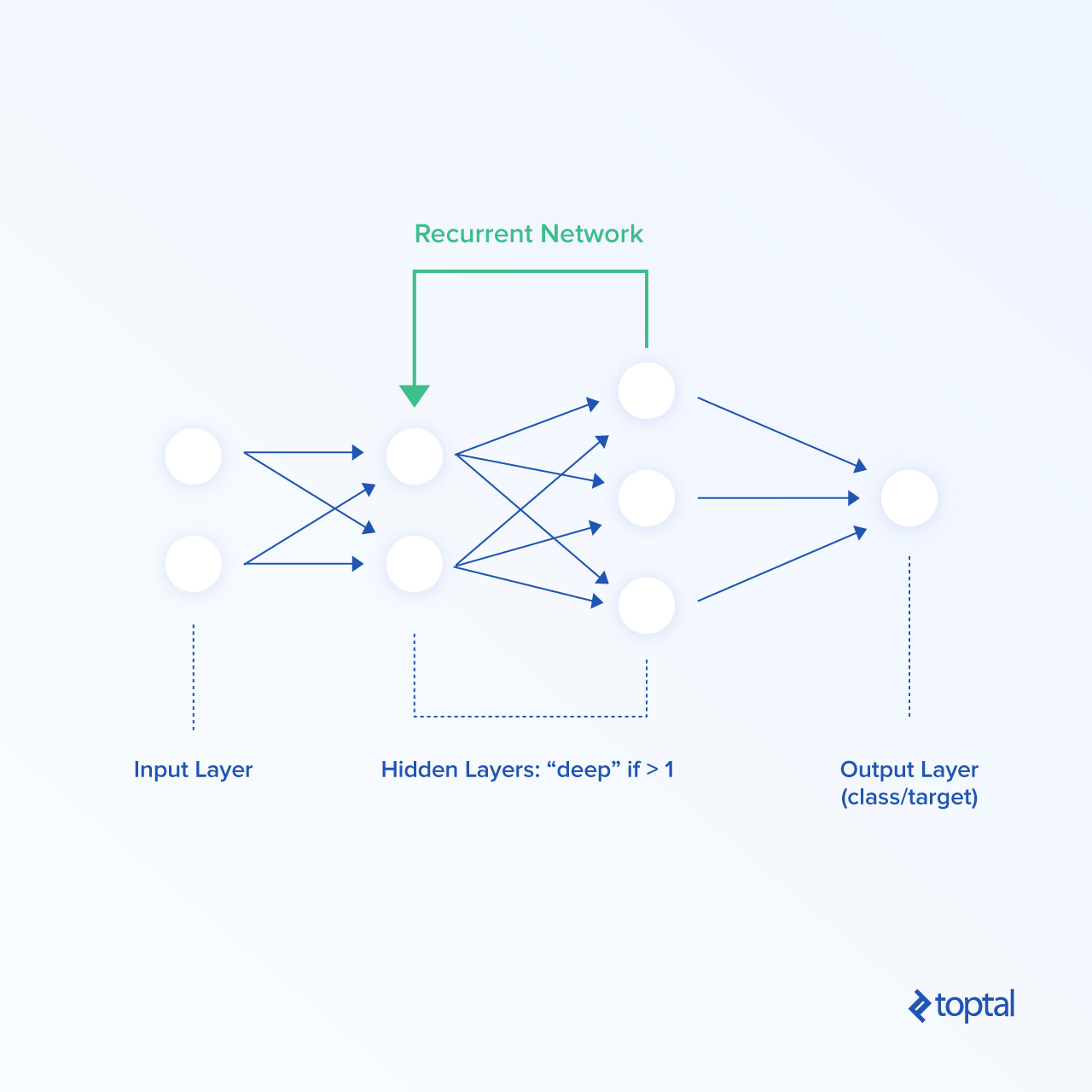
Redes Neuronales Recurrentes
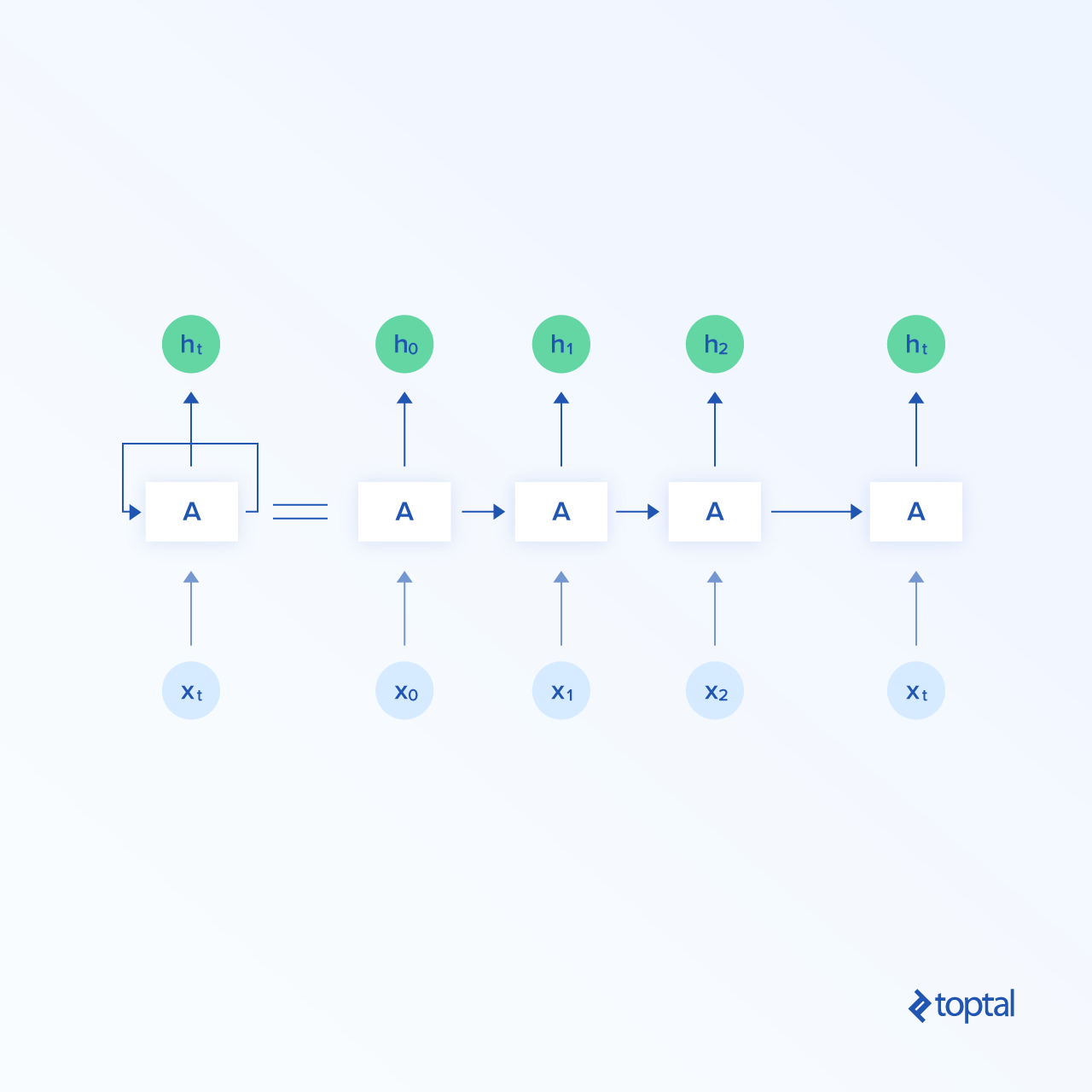
Una versión más complicada de una red neuronal es una red neuronal recurrente. En las redes neuronales recurrentes, los datos pueden fluir en cualquier dirección, a diferencia de las redes neuronales predictivas. Pueden aprender bien las dependencias de series temporales. La arquitectura de una red neuronal recurrente general se muestra en la imagen a continuación.
En la imagen de abajo se muestra una neurona recurrente. Se necesita X_{t},
punto en el tiempo t, como entrada y regresos h_{t}, estado oculto en el tiempo t, como una salida. La salida oculta se propaga otra vez hacia la neurona. La neurona recurrente se puede desenrollar, ya que se muestra en la misma imagen desde el lado derecho. X_{t_0}
es un punto en el período de tiempo t_{0}, X_{t_1} en el periodo de tiempo t_{1}, y X_{t} en el periodo de tiempo t. Productos obtenidos utilizando entradas X_{t_0}, X_{t_1}, …, X_{t_n} en periodos de tiempo t_{0}, t_{1}, …, t_{n} también se llaman salidas ocultas: h_{t_0}, h_{t_1}, …, h_{t_n}, respectivamente.
Una de las mejores arquitecturas de redes neuronales recurrentes es la arquitectura LSTM. LSTM se muestra a continuación:
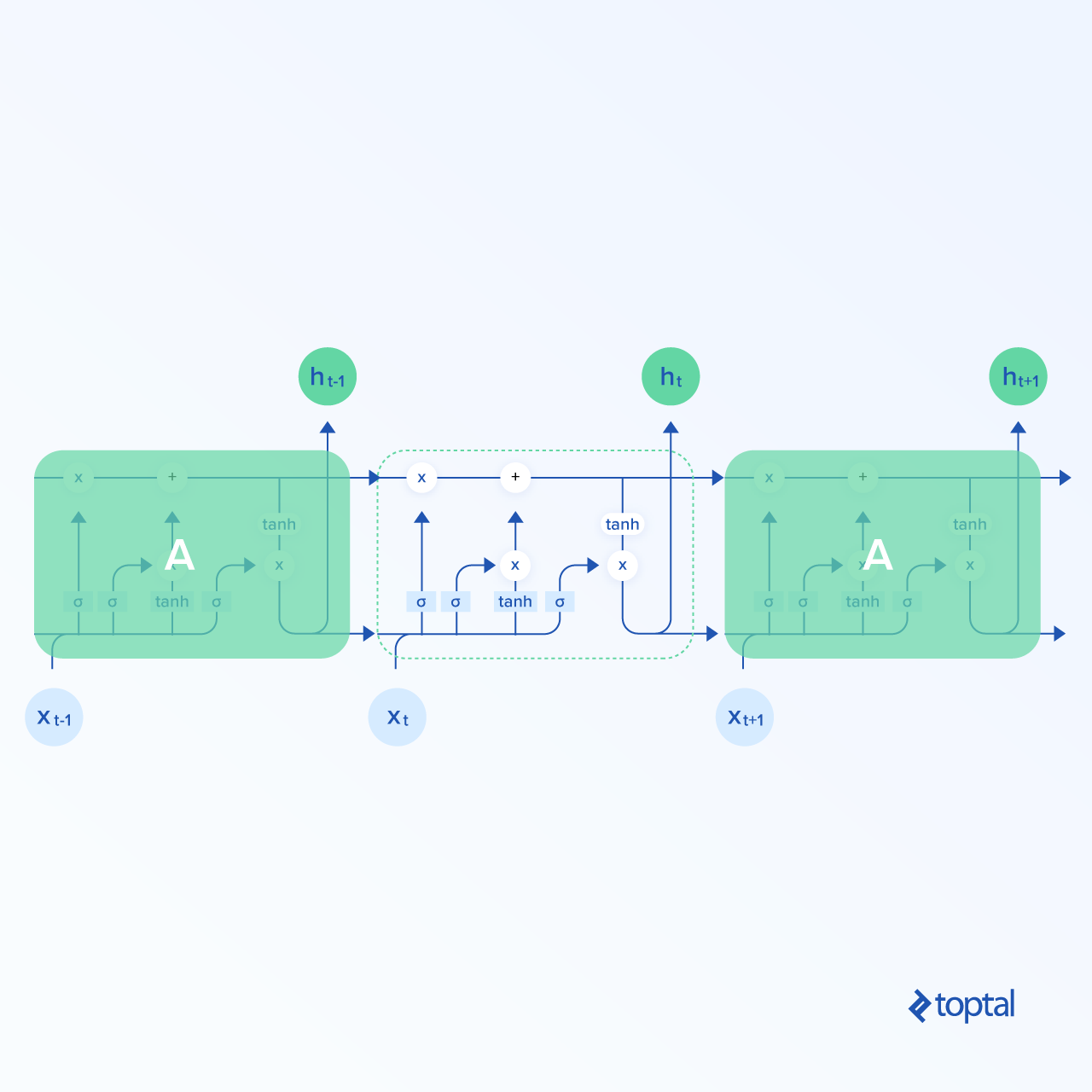
Las LSTM tienen la misma estructura general que las redes neuronales recurrentes generales, pero la neurona recurrente es un poco diferente con una estructura más compleja. Se puede ver en la imagen anterior que se realizan muchos cálculos dentro de una celda LSTM. Las celdas LSTM se pueden observar como una caja negra en el contexto de esta publicación, pero para lectores más curiosos, este blog post explica los cálculos dentro de LSTM y mucho más.
Vamos a llamar a la entrada de la red neuronal un “vector de características”. Es un vector dimensional n- cuyos elementos son características: f_{0}, f_{1}, f_{2} …, f_{n}.
~~~
\vv{X} = [f_{0}, f_{1}, f_{2}, …, f_{n}]
~~~
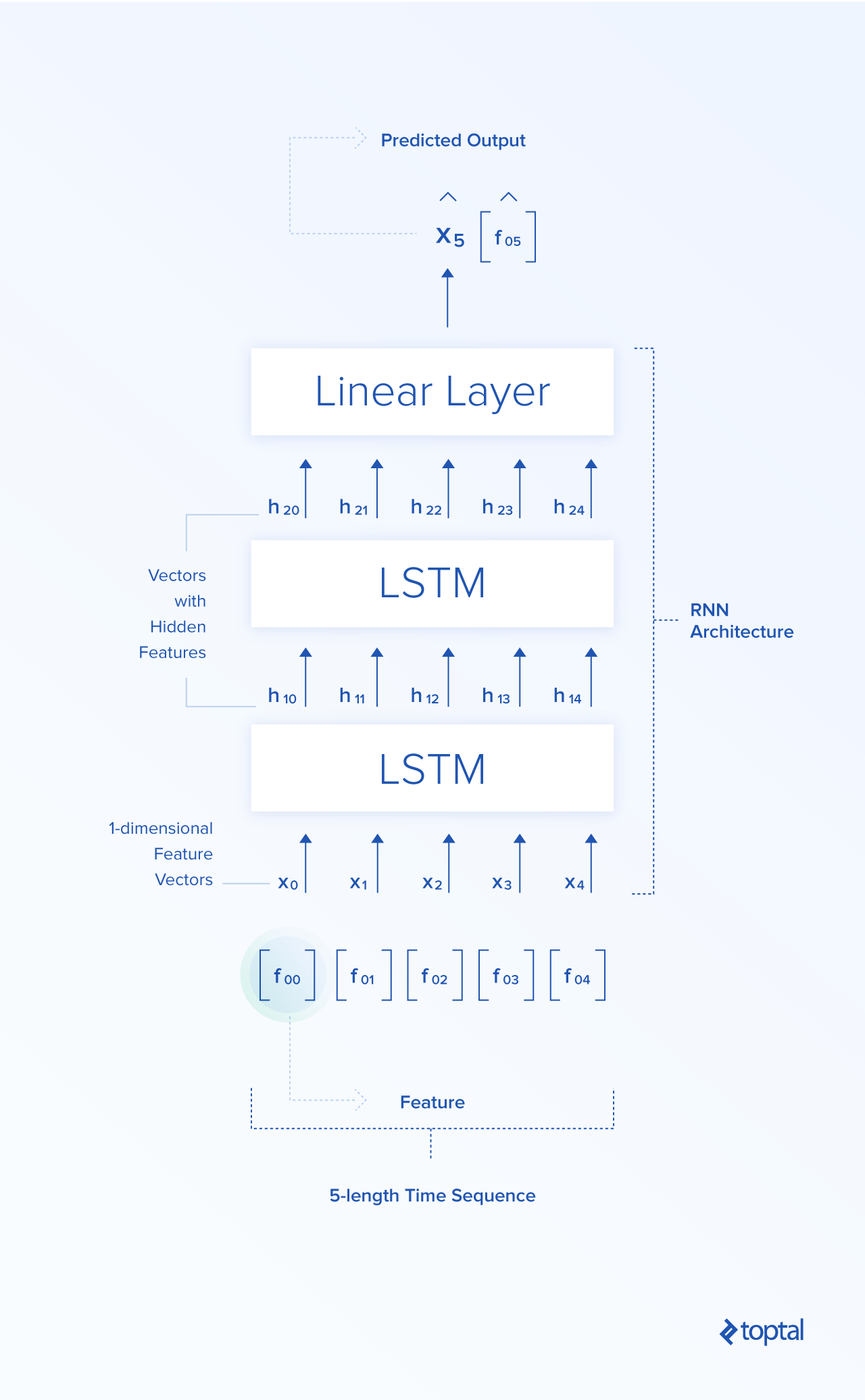
Ahora, expliquemos cómo las redes neuronales recurrentes se pueden aplicar a una tarea relacionada con las finanzas. La entrada para la red neuronal recurrente es [X_{t_0}, X_{t_1}, X_{t_2}, …, X_{t_n}]. Digamos que n = 5. Tomamos cinco precios de acciones de Google Close de cinco días consecutivos (consulta la tabla con datos de Abierto/Alto/Bajo/Cerrado/Arriba) entre, digamos, 2010-01-04 y 2010-01-08, ej., [[311.35], [309.98], [302.16], [295.13], [299.06]]. El vector de características en este ejemplo es unidimensional. La secuencia de tiempo consiste en cinco de tales vectores de características. Las salidas de la red neuronal recurrente son funciones ocultas [h_{t_0}, h_{t_1}, h_{t_2}, …, h_{t_n}]. Esas características están en un nivel más abstracto que las características de entrada [X_{t_0}, X_{t_1}, X_{t_2}, …, X_{t_n}]—LSTM debe aprender las partes importantes de las características de entrada y proyectarlas al espacio de características ocultas. Esas características ocultas y abstractas se pueden propagar en la siguiente celda LSTM, que proporcionará el siguiente conjunto de funciones ocultas y más abstractas que luego pueden propagarse nuevamente a la siguiente LSTM, y así sucesivamente. Después de la secuencia de LSTM encadenadas, el componente final de la red neuronal es la capa lineal (la parte de construcción de la red de avance simple explicada en la sección anterior) que mapea las características ocultas desde la última LSTM hasta el punto en un espacio dimensional, y ese punto es el resultado final de la red—el precio de cierre previsto en el período de tiempo X_{t+1}. La verdad del terreno en este ejemplo para X_{t+1} es 298.61.
Nota: También puede haber tan solo una LSTM—establecer el número de LSTM es un hiperparámetro, que generalmente se encuentra empíricamente, aunque podemos usar algunas heurísticas. Si los datos no son tan complejos, utilizamos una arquitectura menos compleja para que el modelo no sobreponga los datos. Si los datos son complejos, usamos un modelo complejo para que el modelo no desajuste los datos.
En la fase de entrenamiento, los precios de cierre predichos se comparan con los precios de verdad del terreno y la diferencia entre los precios de cierre previstos y los precios de verdad del terreno se minimiza utilizando un algoritmo de retropropagación y un algoritmo de optimización del descenso del gradiente (o una de sus formas—concretamente, en este blog, se usa la versión llamada “Adam” de un algoritmo de optimización de descenso de gradiente) al cambiar los pesos de la red neuronal.
Después del entrenamiento y las pruebas, en el futuro el usuario solo necesita dar datos de entrada a la red neuronal y devolverá el precio previsto (y con suerte, un precio muy cercano al precio de verdad del futuro). Una cosa más que mencionar aquí es que, por lo general, los lotes de datos se envían a través de la red, en capacitación en fases de prueba para que la red calcule múltiples salidas en una sola pasada. A continuación se muestra una imagen de una arquitectura utilizada en este blog para experimentos. Consiste en dos LSTM apiladas y una capa lineal.
Experimentos con Algoritmos de Fondos de Cobertura
Intenta utilizar estrategias de negociación algorítmicas tan simples de la siguiente manera: si el algoritmo predice que el precio aumentará al día siguiente, compra n (n = 1 en este ejemplo) acciones de una empresa (larga), de lo contrario vender todas las acciones de una empresa (corto). El valor inicial del portafolio (el valor de efectivo y acciones combinadas) se establece en 100,000 dólares. Cada acción larga o corta comprará acciones n de una compañía (Google, en este ejemplo) o vender todas las acciones de una compañía, respectivamente. Al principio, el sistema posee 0 acciones de una compañía determinada.
Recuerda siempre que este es un ejemplo muy básico y simple, no destinado para el uso en el mundo real ya que se necesitaría mucho más trabajo de I+D para modificar el modelo y que funcione bien en la práctica. Aquí se descuidan algunas cosas que deberían considerarse en un escenario del mundo real; por ejemplo, las tarifas de transacción no están incorporadas en el modelo. Se supone que el sistema puede operar exactamente a la misma hora todos los días, y se supone que todos los días, incluso en un fin de semana o día feriado, es un día de negociación.
Para las pruebas, se usa un método de backtesting. El método de backtesting usa datos históricos para reconstruir operaciones que habrían ocurrido en el pasado utilizando las reglas definidas con la estrategia que se desarrolla. El conjunto de datos se divide en dos partes—la primera parte es el conjunto de entrenamiento (pasado) y la segunda parte es el conjunto de pruebas (futuro). El modelo está entrenado en un conjunto de entrenamiento y, después del entrenamiento, simulamos el futuro en la segunda parte del conjunto de datos para ver cómo el modelo entrenado se habría comportado en el futuro sin haber sido capacitado en él.
La métrica para evaluar la estrategia de negociación es la relación de Sharpe (su versión anualizada, suponiendo que todos los días de un año son días de negociación, y el año tiene 365 días).: sqrt(365)*mean(returns)/std(returns)), donde el retorno se define como p_{t}/p_{t-1} - 1, y p_{t} es el precio en el período de tiempo t. La relación de Sharpe muestra la relación entre los rendimientos y el riesgo adicional en que se incurre, por lo que es bueno tener una relación de Sharpe más grande. Por lo general, una proporción mayor a 1 es aceptable para los inversionistas, 2 es muy buena y 3 es excelente.
Sólo se utiliza como una característica el precio de cierre diario de los precios históricos de Google del conjunto de datos de Yahoo Finance. Más características ayudarán, pero está fuera del alcance de este blog probar qué otras características del conjunto de datos (Abierto, Alto, Bajo) son importantes. Algunas otras características no incluidas en la tabla también podrían ser útiles, por ejemplo, el sentimiento de las noticias en un minuto en particular o acontecimientos importantes en un día en particular. Sin embargo, a veces es muy difícil hacer representaciones de datos que sean útiles para la entrada de la red neuronal y combinarlas con las características existentes. Por ejemplo, es fácil extender el vector de características y poner un número que represente el sentimiento de noticias o el sentimiento de tweet de Trump (-1 muy negativo, 0 neutral, +1 muy positivo, etc.) para cada período de tiempo dado, pero no es tan fácil poner determinados momentos fijados por eventos (piratas en el canal de Suez, bomba en una refinería en Texas) en el vector de características porque, para cada momento específico, necesitaremos tener un elemento adicional en el vector de características para poner 1 si el evento sucedió o 0 de lo contrario, lo que conducirá a un número infinito de elementos para todos los momentos posibles.
Para los datos más difíciles, podríamos definir algunas categorías y, para cada momento, determinar a qué categoría pertenece. También podríamos agregar características de las acciones de otras compañías para que un sistema conozca la correlación entre los precios de las acciones de las diferentes compañías. Además, existe un tipo de red neuronal especializada en visión artificial, redes neuronales convolucionales, que sería interesante combinar con capas recurrentes y ver cómo las características visuales se correlacionan con los precios de algunas compañías. Tal vez podríamos usar la alimentación de la cámara desde una estación de tren abarrotada como una función y conectar esa alimentación a una red neuronal y ver si lo que la red neuronal ve está correlacionado con los precios de las acciones de algunas compañías—podría haber algún conocimiento oculto incluso en ese ejemplo banal y absurdo.
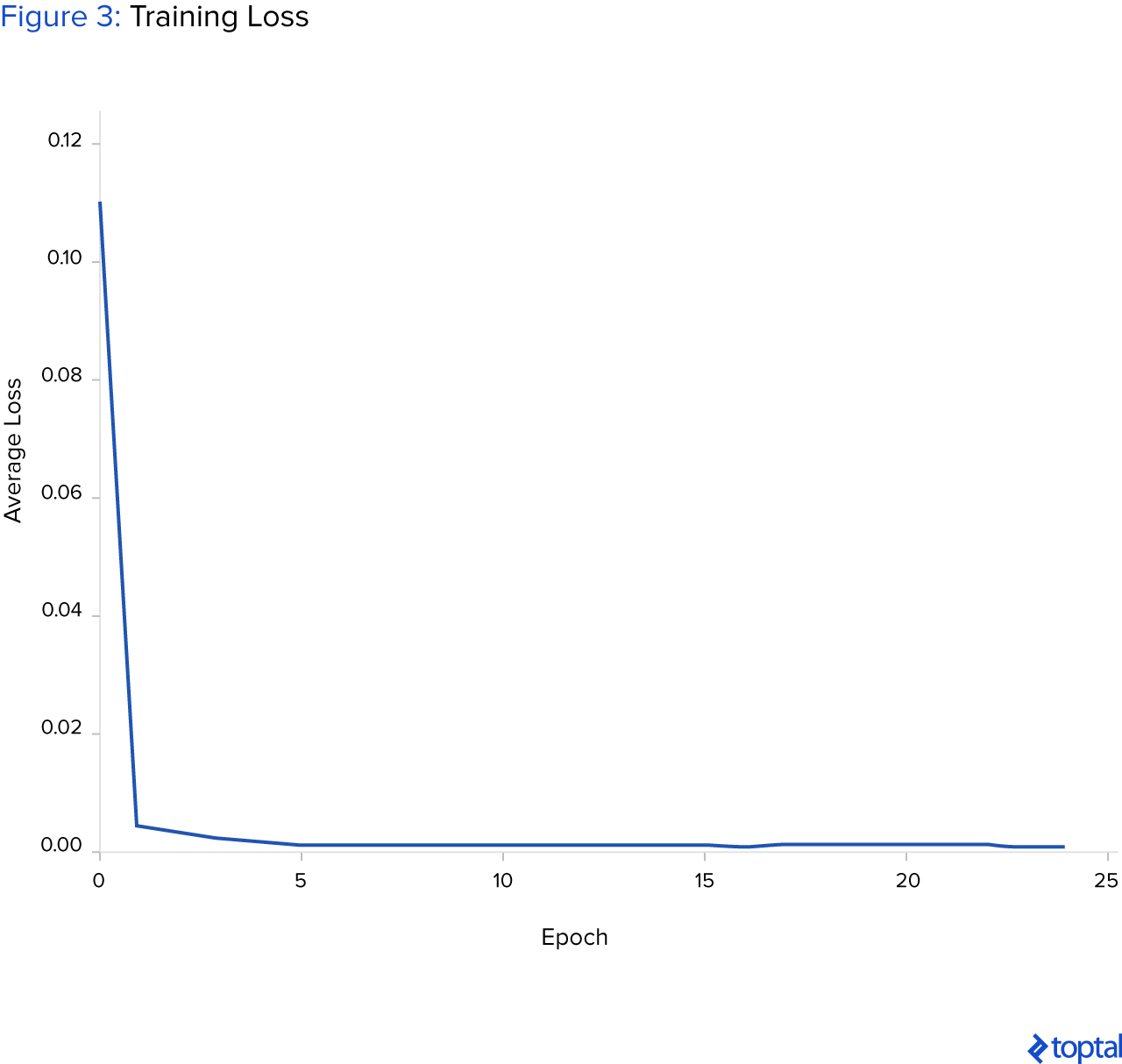
A continuación se muestra un gráfico que muestra cómo la pérdida de entrenamiento promedio está disminuyendo con el tiempo, lo que significa que la red neuronal tiene suficiente capacidad para adaptarse a los datos de entrenamiento. Es importante decir que los datos deben normalizarse para que el algoritmo de aprendizaje profundo pueda converger.
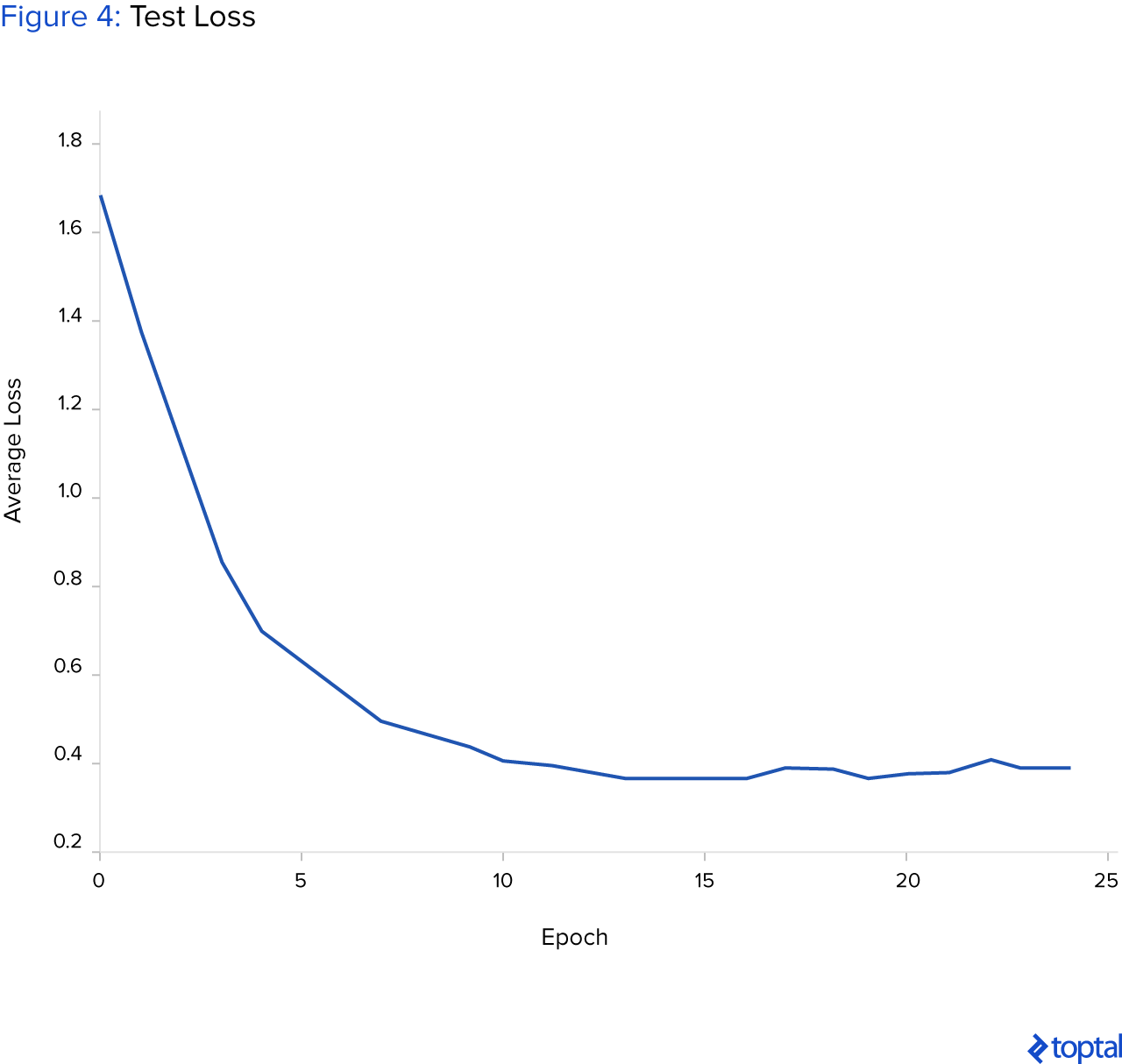
A continuación se muestra un gráfico que muestra cómo la pérdida promedio de prueba está disminuyendo con el tiempo, lo que significa que la red neuronal tiene la capacidad de generalizar en datos no vistos.
El algoritmo es codicioso; si predijo que el precio subirá al día siguiente, el algoritmo compra inmediatamente la participación n=1 de una compañía (si hay suficiente efectivo en el portafolio), y de lo contrario, vende todas las acciones de la compañía (si tiene alguna). El período de inversión es fijo y demora 300 días. Después de 300 días, todas las acciones se venden. La simulación de datos no vistos, después de algunos entrenamientos, se puede ver a continuación. Se muestra cómo el valor del portafolio aumenta a lo largo del tiempo mediante acciones largas/cortas (o no hacer nada) cada día.
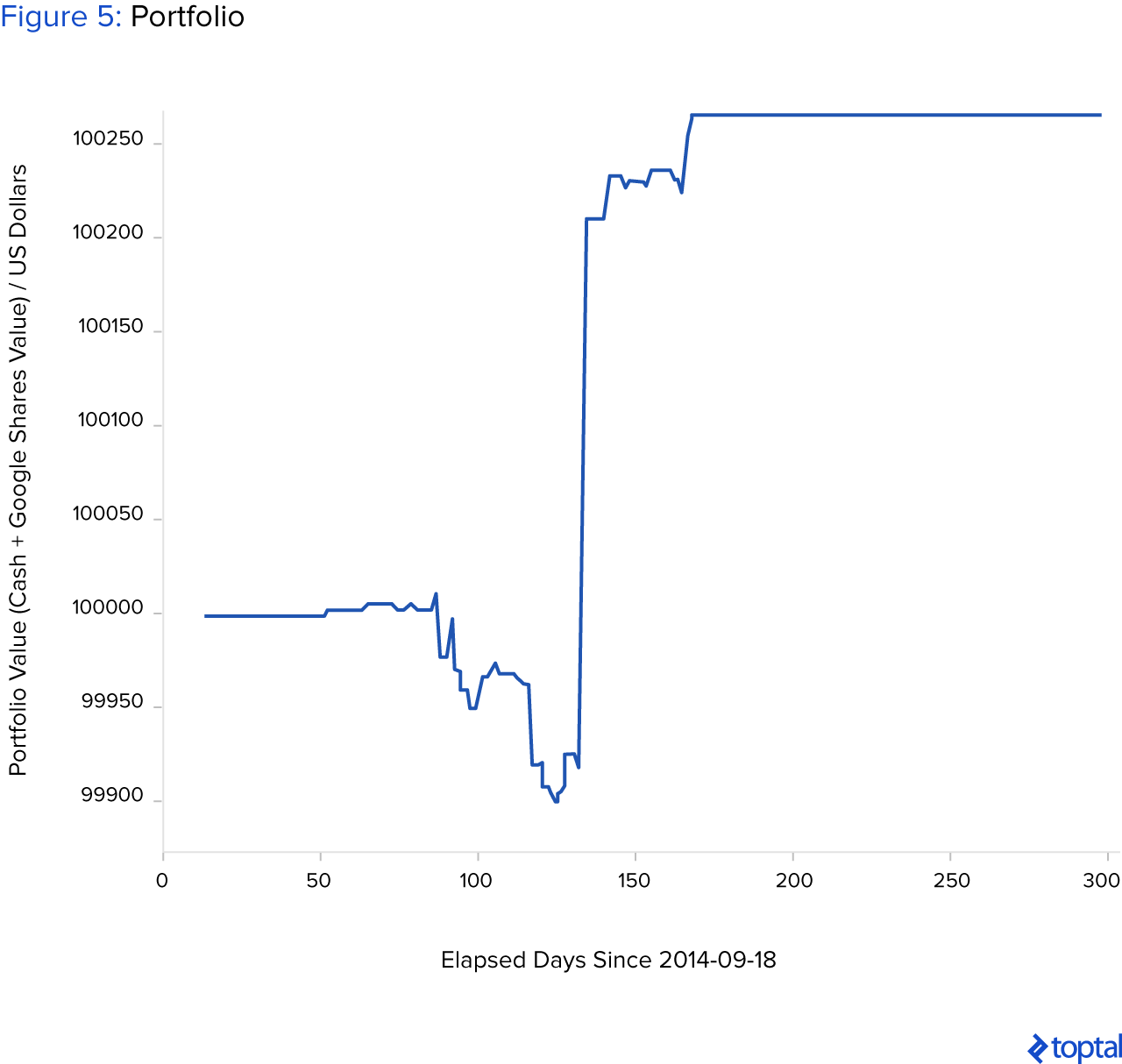
La relación de Sharpe para la simulación anterior es 1.48. El valor final del portafolio después de 300 días es de 100,263.79 dólares. Si sólo compramos acciones el primer día y las vendimos después de 300 días, el portafolio valdría 99,988.41 dólares. A continuación se muestra una situación en la que la red neuronal no está bien entrenada y pierde dinero luego de un período fijo de 300 días.
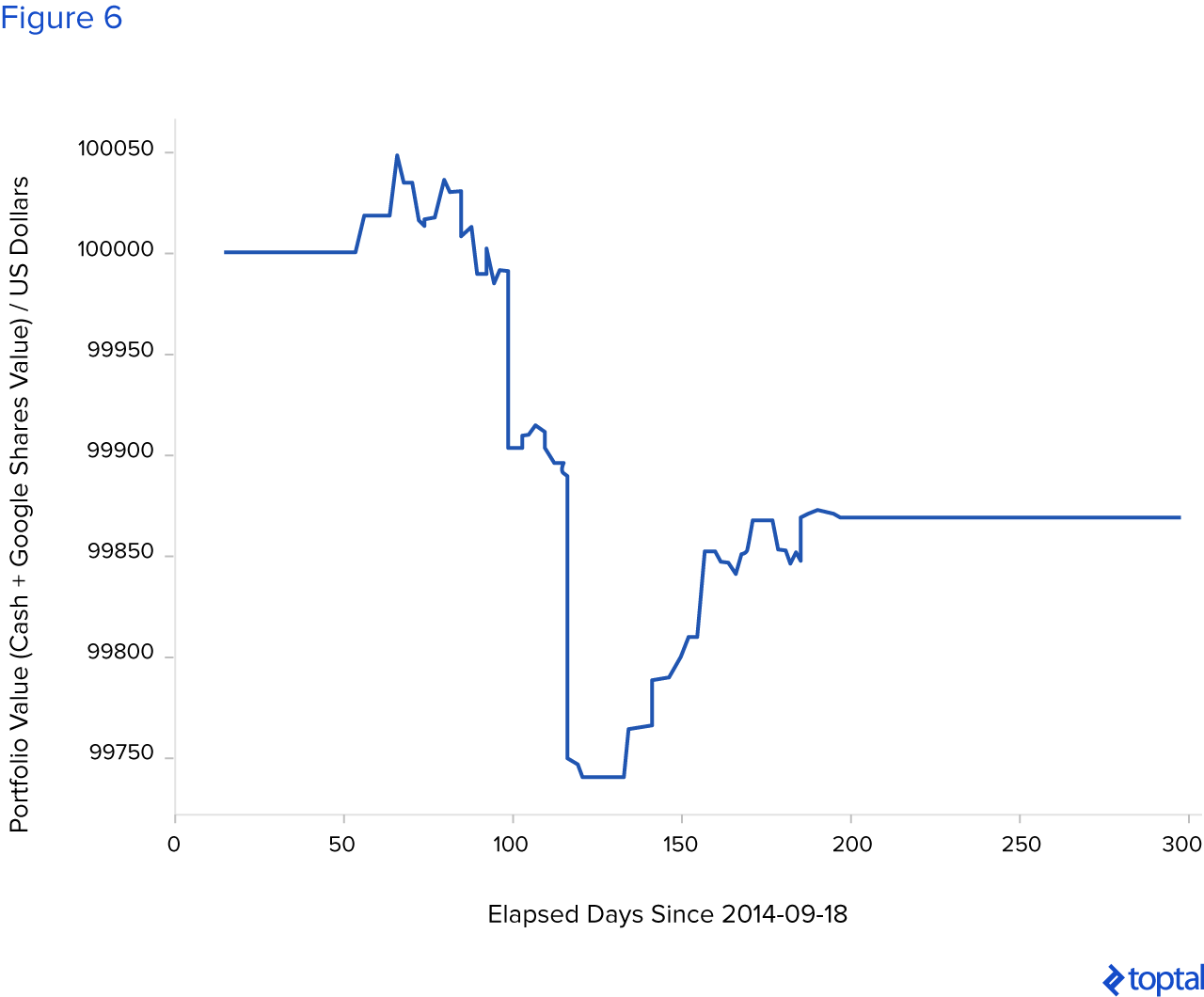
La relación de Sharpe es -0.94. El valor final del portafolio después de 300 días es de 99,868.36 dólares.
Aquí hay un ejemplo interesante: el algoritmo anterior es codicioso y sólo predice el precio para el día siguiente, tomando medidas basadas sólo en esa predicción. Es posible encadenar predicciones múltiples y predecir el precio en los siguientes pasos en el futuro. Por ejemplo, con una primera entrada de [X_ground_truth_{t0}, X_ground_truth_{t1}, X_ground_truth_{t2}, X_ground_truth_{t3}, X_ground_truth_{t4}] y la primera salida que sería [X_predicted_{t5}], podemos alimentar a la red neuronal con esa predicción para que la siguiente entrada sea [X_ground_truth_{t1}, X_ground_truth_{t2}, X_ground_truth_{t3}, X_ground_truth_{t4}, X_predicted_{t5}] y la salida es [X_predicted_{t6}]. La siguiente entrada de ahí es [X_ground_truth_{t2}, X_ground_truth_{t3}, X_ground_truth_{t4}, X_predicted_{t5}, X_predicted_{t6}] que resulta en [X_predicted_{t7}], y así sucesivamente. El problema aquí es que estamos introduciendo un error de predicción que aumenta con cada nuevo paso y finalmente termina con un resultado muy malo a largo plazo, como se muestra en la imagen a continuación. La predicción al principio sigue la tendencia descendente de la verdad del terreno y luego se estanca y empeora con el tiempo.
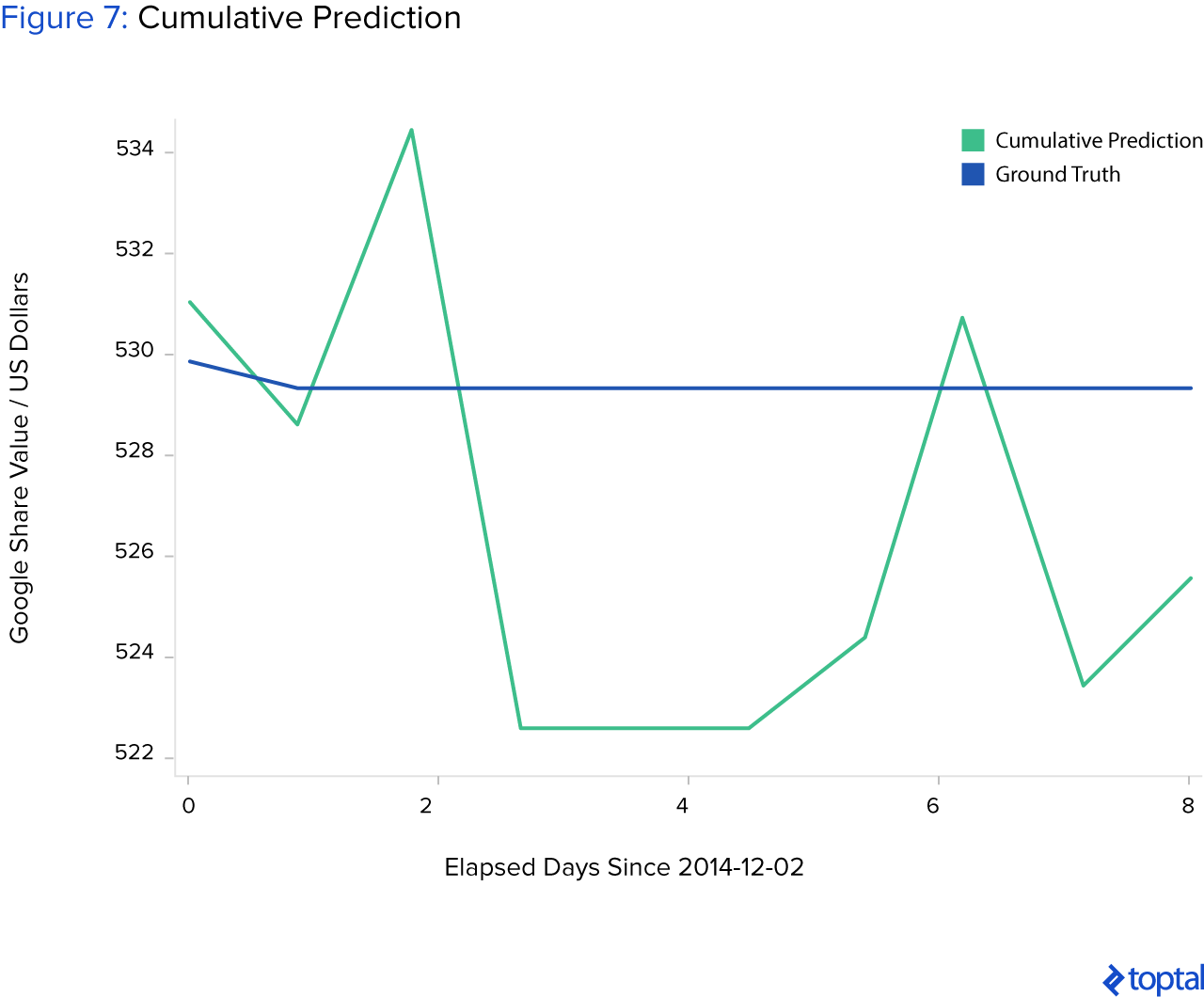
Se realizó un análisis de aprendizaje profundo muy simple sobre los precios de las acciones de Google, pero puede incorporar casi cualquier conjunto de datos financieros, siempre que la cantidad de datos sea lo suficientemente grande y de buena calidad. Los datos deben ser discriminativos y deben describir y representar bien el problema.
Para Concluir
Si funcionó y generalizó bien en extensas pruebas, este sistema podría permitir a los gestores de fondos de cobertura especular sobre los precios futuros de las acciones de una empresa mediante el aprendizaje profundo y confiando en estrategias de negociación algorítmicas.
Los administradores de fondos de cobertura podrían darle al sistema una cantidad de dinero para intercambiar automáticamente todos los días. Sin embargo, sería muy malo permitir que los algoritmos de negociación automatizados se comercialicen sin ninguna supervisión. El administrador del fondo de cobertura debe tener algunas habilidades de aprendizaje profundo o emplear a alguien con las habilidades necesarias para supervisar el sistema y determinar cuándo el sistema ha perdido la capacidad de generalizar y hacer buen comercio. Si el sistema perdiera la capacidad de generalizar, sería necesario volver a capacitarlo desde el principio y volver a probarlo (quizás introduciendo características más discriminatorias o nuevos conocimientos—utilizando datos nuevos del pasado que no existían cuando el modelo fue entrenado primero).
A veces los datos simplemente no son lo suficientemente buenos para que el sistema de aprendizaje profundo se capacite y generalice bien y, en ese caso, un ingeniero de aprendizaje profundo experimentado debería ser capaz de detectar y rectificar tal situación. Para construir un sistema de comercio de aprendizaje profundo, necesitas científicos de datos de fondos de cobertura, expertos en aprendizaje automático (tanto científicos como ingenieros), ingenieros de I+D familiarizados con el aprendizaje de máquina/aprendizaje profundo, etc. No importa con qué parte de una aplicación de aprendizaje de máquina estén familiarizados, ya sea por visión artificial o reconocimiento de voz, los profesionales con experiencia podrán utilizar su experiencia en el sector financiero. En su raíz, el aprendizaje profundo tiene los mismos conceptos básicos, independientemente de la aplicación o la industria, y debería ser fácil para alguien con experiencia cambiar de un tema a otro.
El sistema que presentamos es muy básico y para ser aplicado en el mundo real, se debe hacer más investigación y desarrollo para aumentar los retornos. Posibles mejoras del sistema podrían ser en el desarrollo de mejores estrategias de negociación. Recolectar más datos para el entrenamiento, que generalmente es muy costoso, ayudará. Un intervalo de tiempo más pequeño entre los puntos es mejor. También pueden surgir mejoras en el uso de más características (por ejemplo, sentimientos noticiosos o sucesos importantes correspondientes a cada punto del conjunto de datos, a pesar de ser difícil de codificar para una red neuronal) y una extensa grilla de búsqueda de hiperparámetros y descubrimiento de arquitectura RNR.
Además, se necesita más poder de computación (GPU potentes) para realizar muchos experimentos extensos en paralelo y procesar una gran cantidad de datos, siempre que se recopile una gran cantidad de datos.
Referencias:
- https://www.datacamp.com/community/tutorials/finance-python-trading
- http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- https://en.wikipedia.org
- https://www.investopedia.com/
- https://finance.yahoo.com/
- http://pytorch.org/
{kind=link}
Nota del Autor: Me gustaría agradecer a Ivan Čapalija y Matej Paradžik por las conversaciones y consejos constructivos sobre el aprendizaje profundo en finanzas, lo cual me ayudó a escribir este blog.
Zagreb, Croatia
Member since September 27, 2017
About the author
Co-founder of Poze and CEO of an AI R&D/consulting company, Neven has an MCS degree and has built a face-recognition system in TensorFlow.