Webpack or Browserify & Gulp: Which Is Better?
Gone are the days where front-end developers for web applications could use ad-hoc JavaScript with jQuery and such all in a single JavaScript file. Modern web applications require more effort from the developer to adopt an overall architecture and development process. Building such front-end applications relies on lots of external dependencies and modular source code, and these elements necessitate automation to save developers time and reduce the chances of mistakes.
In this article, Toptal Freelance Software Engineer Eric Grosse shows us how various combinations of the popular tools Webpack, Browserify, Gulp and Npm can benefit us by enhancing our development environment and allowing us to focus on writing the app itself.

Gone are the days where front-end developers for web applications could use ad-hoc JavaScript with jQuery and such all in a single JavaScript file. Modern web applications require more effort from the developer to adopt an overall architecture and development process. Building such front-end applications relies on lots of external dependencies and modular source code, and these elements necessitate automation to save developers time and reduce the chances of mistakes.
In this article, Toptal Freelance Software Engineer Eric Grosse shows us how various combinations of the popular tools Webpack, Browserify, Gulp and Npm can benefit us by enhancing our development environment and allowing us to focus on writing the app itself.

Eric is a full-stack developer specializing in front-end work using React, Node, and HAPI. His passion is cutting-edge technology.
As web applications grow increasingly complex, making your web app scalable becomes of the utmost importance. Whereas in the past writing ad-hoc JavaScript and jQuery would suffice, nowadays building a web app requires a much greater degree of discipline and formal software development practices, such as:
- Unit tests to ensure modifications to your code don’t break existing functionality
- Linting to ensure consistent coding style free of errors
- Production builds that differ from development builds
The web also provides some of its own unique development challenges. For example, since webpages make a lot of asynchronous requests, your web app’s performance can be significantly degraded from having to request hundreds of JS and CSS files, each with their own tiny overhead (headers, handshakes, and so on). This particular issue can often be addressed by bundling the files together, so you’re only requesting a single bundled JS and CSS file rather than hundreds of individual ones.
It’s also quite common to use language preprocessors such as SASS and JSX that compile to native JS and CSS, as well as JS transpilers such as Babel, to benefit from ES6 code while maintaining ES5 compatibility.
This amounts to a significant number of tasks that have nothing to do with writing the logic of the web app itself. This is where task runners come in. The purpose of a task runner is to automate all of these tasks so that you can benefit from an enhanced development environment while focusing on writing your app. Once the task runner is configured, all you need to do is invoke a single command in a terminal.
I will be using Gulp as a task runner because it is very developer friendly, easy to learn, and readily understandable.
A Quick Introduction to Gulp
Gulp’s API consists of four functions:
gulp.srcgulp.destgulp.taskgulp.watch
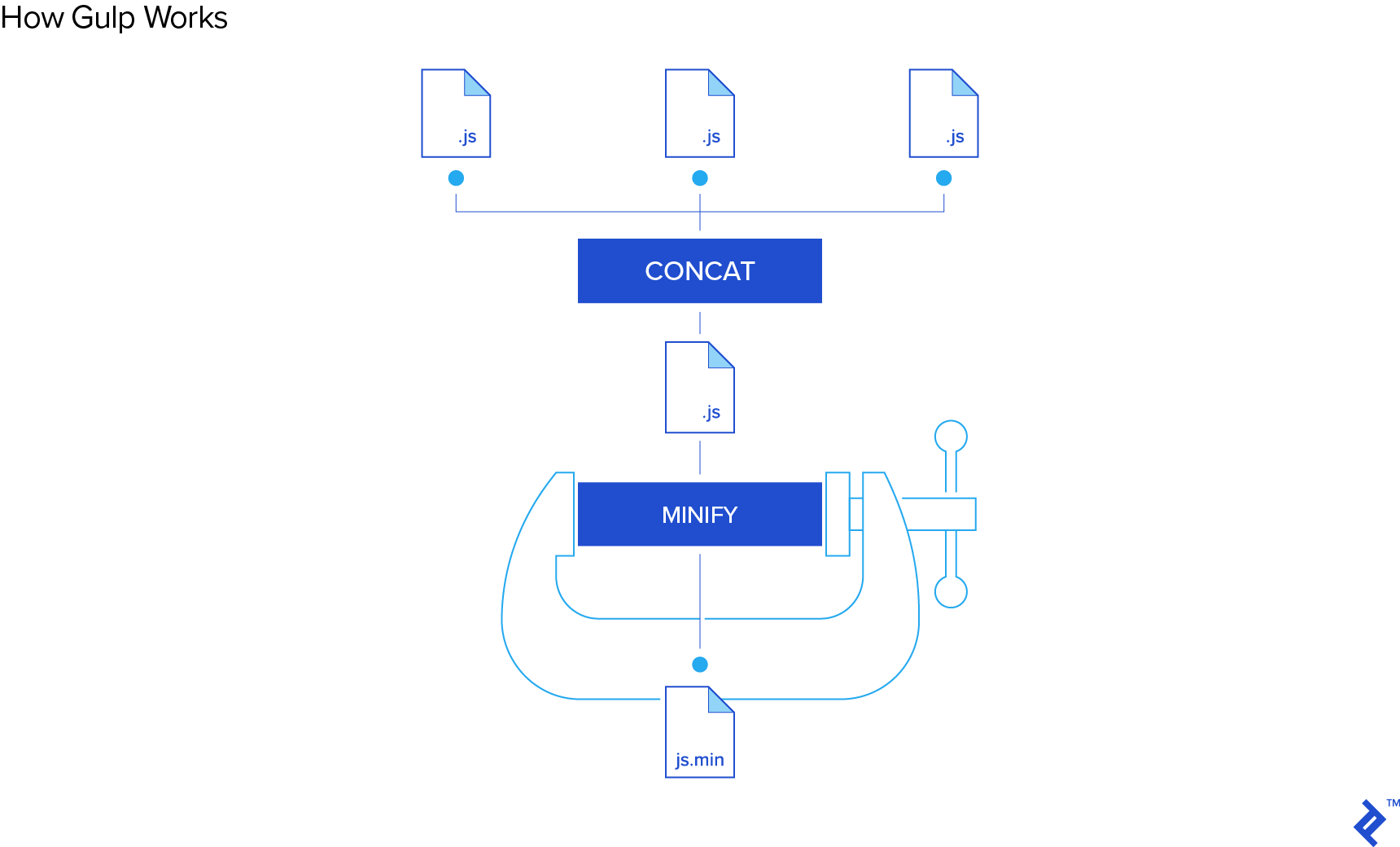
Here, for example, is a sample task that makes use of three of these four functions:
gulp.task('my-first-task', function() {
gulp.src('/public/js/**/*.js')
.pipe(concat())
.pipe(minify())
.pipe(gulp.dest('build'))
});
When my-first-task is performed, all the files matching the glob pattern /public/js/**/*.js are minified and then transferred to a build folder.
The beauty of this is in the .pipe() chaining. You take a set of input files, pipe them through a series of transformations, then return the output files. To make things even more convenient, the actual piping transformations, such as minify(), are often done by NPM libraries. As a result, it’s very rare in practice that you need to write your own transformations beyond renaming files in the pipe.
The next step to understand Gulp is understanding the array of task dependencies.
gulp.task('my-second-task', ['lint', 'bundle'], function() {
...
});
Here, my-second-task only runs the callback function after the lint and bundle tasks are completed. This allows for separation of concerns: You create a series of small tasks with a single responsibility, such as converting LESS to CSS, and create a sort of master task that simply calls all the other tasks via the array of task dependencies.
Finally, we have gulp.watch, which watches a glob file pattern for changes, and when a change is detected, runs a series of tasks.
gulp.task('my-third-task', function() {
gulp.watch('/public/js/**/*.js', ['lint', 'reload'])
})
In the above example, any changes to a file matching /public/js/**/*.js would trigger the lint and reload task. A common use of gulp.watch is to trigger live reloads in the browser, a feature so useful for development that you won’t be able to live without it once you’ve experienced it.
And just like that, you understand all you really need to know about gulp.
Where Does Webpack Fit In?
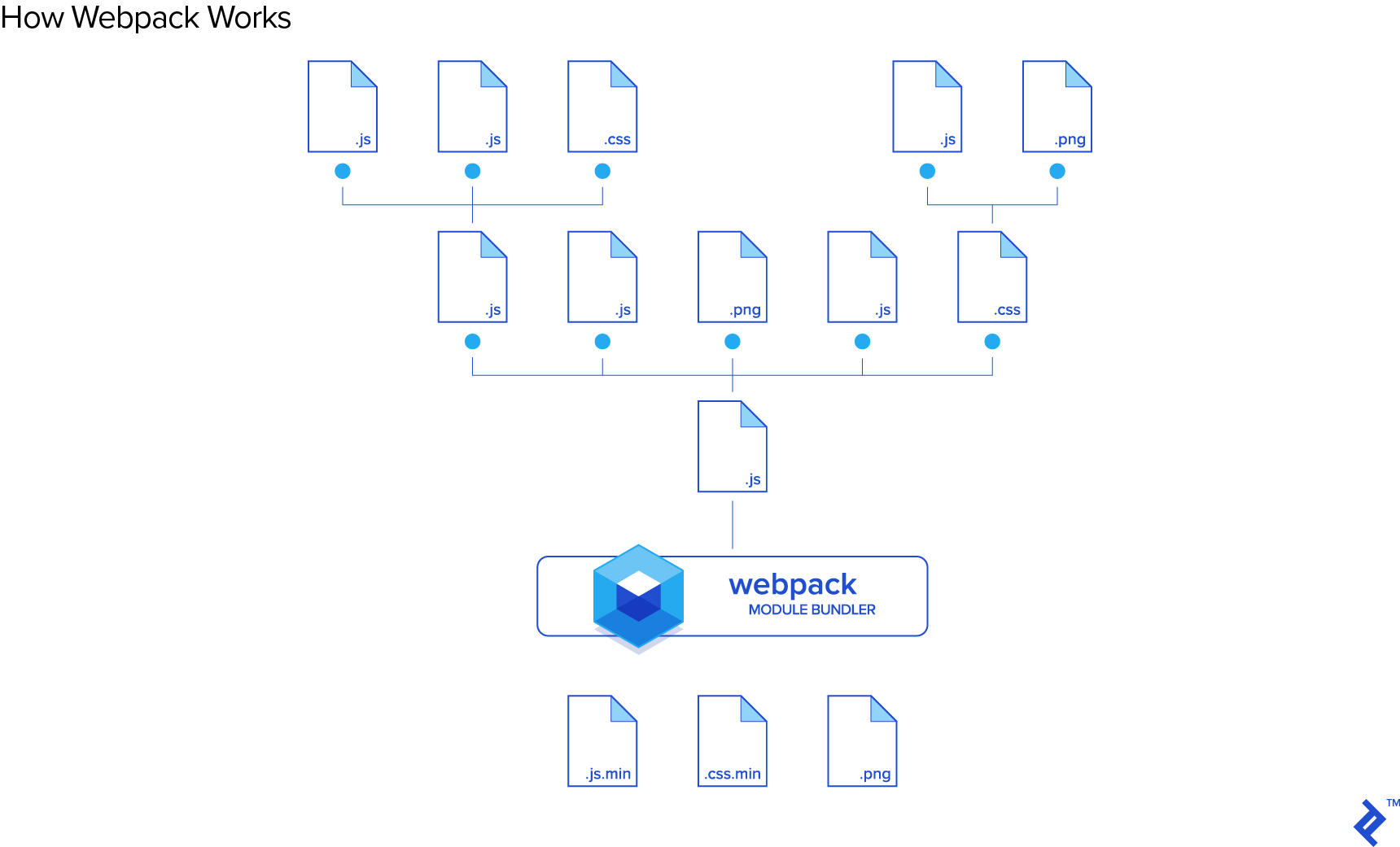
When using the CommonJS pattern, bundling JavaScript files isn’t as simple as concatenating them. Rather, you have an entry point (usually called index.js or app.js) with a series of require or import statements at the top of the file:
ES5
var Component1 = require('./components/Component1');
var Component2 = require('./components/Component2');
ES6
import Component1 from './components/Component1';
import Component2 from './components/Component2';
The dependencies have to be resolved before the remaining code in app.js, and those dependencies may themselves have further dependencies to resolve. Furthermore, you might require the same dependency in multiple places in your application, but you only want to resolve that dependency once. As you can imagine, once you have a dependency tree a few levels deep, the process of bundling your JavaScript becomes rather complex. This is where bundlers such as Browserify and Webpack come in.
Why Are Developers Using Webpack Instead of Gulp?
Webpack is a bundler whereas Gulp is a task runner, so you’d expect to see these two tools commonly used together. Instead, there’s a growing trend, especially among the React community, to use Webpack instead of Gulp. Why is this?
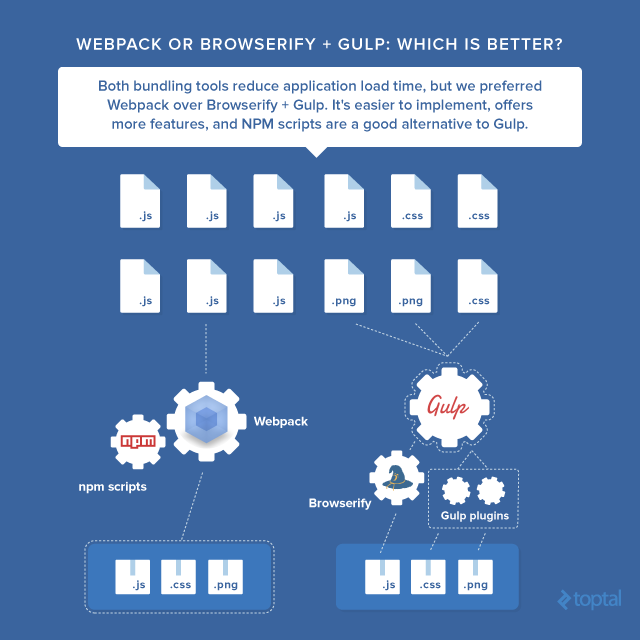
Simply put, Webpack is such a powerful tool that it can already perform the vast majority of the tasks you’d otherwise do through a task runner. For instance, Webpack already provides options for minification and sourcemaps for your bundle. In addition, Webpack can be run as middleware through a custom server called webpack-dev-server, which supports both live reloading and hot reloading (we’ll talk about these features later). By using loaders, you can also add ES6 to ES5 transpilation, and CSS pre- and post-processors. That really just leaves unit tests and linting as major tasks that Webpack can’t handle independently. Given that we’ve cut down at least half a dozen potential gulp tasks down to two, many devs opt to instead use NPM scripts directly, as this avoids the overhead of adding Gulp to the project (which we’ll also talk about later).
The major drawback to using Webpack is that it is rather difficult to configure, which is unattractive if you’re trying to quickly get a project up and running.
Our 3 Task Runner Setups
I will set up a project with three different task runner setups. Each setup will perform the following tasks:
- Set up a development server with live reloading on watched file changes
- Bundle our JS & CSS files (including ES6 to ES5 transpilation, SASS to CSS conversion and sourcemaps) in a scalable manner on watched file changes
- Run unit tests either as a standalone task or in watch mode
- Run linting either as a standalone task or in watch mode
- Provide the ability to execute all of the above via a single command in the terminal
- Have another command for creating a production bundle with minification and other optimizations
Our three setups will be:
- Gulp + Browserify
- Gulp + Webpack
- Webpack + NPM Scripts
The application will use React for the front-end. Originally, I wanted to use a framework-agnostic approach, but using React actually simplifies the responsibilities of the task runner, since only one HTML file is needed, and React works very well with the CommonJS pattern.
We will cover the benefits and drawbacks of each setup so you can make an informed decision on what type of setup best suits your project needs.
I’ve setup a Git repository with three branches, one for each approach (link). Testing each setup is as simple as:
git checkout <branch name>
npm prune (optional)
npm install
gulp (or npm start, depending on the setup)
Let’s examine the code in each branch in detail…
Common Code
Folder Structure
- app
- components
- fonts
- styles
- index.html
- index.js
- index.test.js
- routes.js
A straightforward HTML file. The React application is loaded into <div id="app"></div> and we only use a single bundled JS and CSS file. In fact, in our Webpack development setup, we won’t even need bundle.css.
This acts as the JS entry point of our app. Essentially, we’re just loading React Router into the div with id app that we mentioned earlier.
This file defines our routes. The urls /, /about and /contact are mapped to the HomePage, AboutPage, and ContactPage components, respectively.
This is a series of unit tests that test native JavaScript behavior. In a real production quality app, you’d write a unit test per React component (at least ones that manipulate state), testing React-specific behavior. However, for the purposes of this post, it’s enough to simply have a functional unit test that can run in watch mode.
This can be thought of as the container for all our page views. Each page contains a <Header/> component as well as this.props.children, which evaluates to the page view itself (ex/ ContactPage if at /contact in the browser).
This is our home view. I’ve opted to use react-bootstrap since bootstrap’s grid system is excellent for creating responsive pages. With proper use of bootstrap, the number of media queries you must write for smaller viewports is dramatically reduced.
The remaining components (Header, AboutPage, ContactPage) are structured similarly (react-bootstrap markup, no state manipulation).
Now let’s talk more about styling.
CSS Styling Approach
My preferred approach to styling React components is to have one stylesheet per component, whose styles are scoped to only apply to that specific component. You’ll notice that in each of my React components, the top-level div has a class name matching the name of the component. So, for example, HomePage.js has its markup wrapped by:
<div className="HomePage">
...
</div>
There is also an associated HomePage.scss file that’s structured as follows:
@import '../../styles/variables';
.HomePage {
// Content here
}
Why is this approach so useful? It results in highly modular CSS, largely eliminating the issue of unwanted cascading behavior.
Suppose we have two React components, Component1 and Component2. In both cases, we want to override the h2 font size.
/* Component1.scss */
.Component1 {
h2 {
font-size: 30px;
}
}
/* Component2.scss */
.Component2 {
h2 {
font-size: 60px;
}
}
The h2 font size of Component1 and Component2 are independent whether the components are adjacent, or one component is nested inside the other. Ideally, this means a component’s styling is completely self-contained, meaning the component will look exactly the same no matter where it is placed in your markup. In reality, it’s not always that simple, but it’s certainly a huge step in the right direction.
In addition to per-component styles, I like to have a styles folder containing a global stylesheet global.scss, along with SASS partials that handle a specific responsibility (in this case, _fonts.scss and _variables.scss for fonts and variables, respectively). The global stylesheet allows us to define the general look and feel of the entire app, while the helper partials can be imported by the per-component stylesheets as needed.
Now that the common code in each branch has been explored in depth, let’s shift our focus to the first task runner / bundler approach.
Gulp + Browserify Setup
This comes out to a surprisingly large gulpfile, with 22 imports and 150 lines of code. So, for the sake of brevity, I’ll only review the js, css, server, watch, and default tasks in detail.
JS bundle
// Browserify specific configuration
const b = browserify({
entries: [config.paths.entry],
debug: true,
plugin: PROD ? [] : [hmr, watchify],
cache: {},
packageCache: {}
})
.transform('babelify');
b.on('update', bundle);
b.on('log', gutil.log);
(...)
gulp.task('js', bundle);
(...)
// Bundles our JS using Browserify. Sourcemaps are used in development, while minification is used in production.
function bundle() {
return b.bundle()
.on('error', gutil.log.bind(gutil, 'Browserify Error'))
.pipe(source('bundle.js'))
.pipe(buffer())
.pipe(cond(PROD, minifyJS()))
.pipe(cond(!PROD, sourcemaps.init({loadMaps: true})))
.pipe(cond(!PROD, sourcemaps.write()))
.pipe(gulp.dest(config.paths.baseDir));
}
This approach is rather ugly for a number of reasons. For one thing, the task is split into three separate parts. First, you create your Browserify bundle object b, passing in some options and defining some event handlers. Then you have the Gulp task itself, which has to pass a named function as its callback instead of inlining it (since b.on('update') uses that very same callback). This hardly has the elegance of a Gulp task where you just pass in a gulp.src and pipe some changes.
Another issue is that this forces us to have different approaches to reloading html, css and js in the browser. Looking at our Gulp watch task:
gulp.task('watch', () => {
livereload.listen({basePath: 'dist'});
gulp.watch(config.paths.html, ['html']);
gulp.watch(config.paths.css, ['css']);
gulp.watch(config.paths.js, () => {
runSequence('lint', 'test');
});
});
When an HTML file is changed, the html task is re-run.
gulp.task('html', () => {
return gulp.src(config.paths.html)
.pipe(gulp.dest(config.paths.baseDir))
.pipe(cond(!PROD, livereload()));
});
The last pipe calls livereload() if the NODE_ENV is not production, which triggers a refresh in the browser.
The same logic is used for the CSS watch. When a CSS file is changed, the css task is re-run, and the last pipe in the css task triggers livereload() and refreshes the browser.
However, the js watch doesn’t call the js task at all. Instead, Browserify’s event handler b.on('update', bundle) handles the reload using a completely different approach (namely, hot module replacement). The inconsistency in this approach is irritating, but unfortunately necessary in order to have incremental builds. If we naively just called livereload() at the end of the bundle function, this would re-build the entire JS bundle on any individual JS file change. Such an approach obviously doesn’t scale. The more JS files you have, the longer each rebundle takes. Suddenly, your 500 ms rebundles start taking 30 seconds, which really inhibits agile development.
CSS bundle
gulp.task('css', () => {
return gulp.src(
[
'node_modules/bootstrap/dist/css/bootstrap.css',
'node_modules/font-awesome/css/font-awesome.css',
config.paths.css
]
)
.pipe(cond(!PROD, sourcemaps.init()))
.pipe(sass().on('error', sass.logError))
.pipe(concat('bundle.css'))
.pipe(cond(PROD, minifyCSS()))
.pipe(cond(!PROD, sourcemaps.write()))
.pipe(gulp.dest(config.paths.baseDir))
.pipe(cond(!PROD, livereload()));
});
The first issue here is the cumbersome vendor CSS inclusion. Whenever a new vendor CSS file is added to the project, we have to remember to change our gulpfile to add an element to the gulp.src array, rather than adding the import into a relevant place in our actual source code.
The other main issue is the convoluted logic in each pipe. I had to add an NPM library called gulp-cond just to setup conditional logic in my pipes, and the end result isn’t too readable (triple brackets everywhere!).
Server Task
gulp.task('server', () => {
nodemon({
script: 'server.js'
});
});
This task is very straightforward. It’s essentially a wrapper around the command line invocation nodemon server.js, which runs server.js in a node environment. nodemon is used instead of node so that any changes to the file cause it to restart. By default, nodemon would restart the running process on any JS file change, which is why it’s important to include a nodemon.json file to limit its scope:
{
"watch": "server.js"
}
Let’s review our server code.
const baseDir = process.env.NODE_ENV === 'production' ? 'build' : 'dist';
const port = process.env.NODE_ENV === 'production' ? 8080: 3000;
const app = express();
This sets the base directory of the server and the port based on the node environment, and creates an instance of express.
app.use(require('connect-livereload')({port: 35729}));
app.use(express.static(path.join(__dirname, baseDir)));
This adds connect-livereload middleware (necessary for our live reloading setup) and static middleware (necessary for handling our static assets).
app.get('/api/sample-route', (req, res) => {
res.send({
website: 'Toptal',
blogPost: true
});
});
This is just a simple API route. If you navigate to localhost:3000/api/sample-route in the browser, you will see:
{
website: "Toptal",
blogPost: true
}
In a real backend, you would have an entire folder dedicated to API routes, separate files for establishing DB connections, and so on. This sample route was merely included to show that we can easily build a backend on top of the frontend we have set up.
app.get('*', (req, res) => {
res.sendFile(path.join(__dirname, './', baseDir ,'/index.html'));
});
This is a catch-all route, meaning no matter what url you type into the browser, the server will return our lone index.html page. It is then the responsibility of the React Router to resolve our routes on the client side.
app.listen(port, () => {
open(`http://localhost:${port}`);
});
This tells our express instance to listen to the port we specified, and open the browser in a new tab at the specified URL.
So far the only thing I don’t like about the server setup is:
app.use(require('connect-livereload')({port: 35729}));
Given that we are already using gulp-livereload in our gulpfile, this makes two separate places where livereload must be used.
Now, last but not least:
Default Task
gulp.task('default', (cb) => {
runSequence('clean', 'lint', 'test', 'html', 'css', 'js', 'fonts', 'server', 'watch', cb);
});
This is the task that runs when simply typing gulp into the terminal. One oddity is the need to use runSequence in order to get the tasks to run sequentially. Normally, an array of tasks are executed in parallel, but this isn’t always the desired behavior. For example, we need to have the clean task run before html to ensure that our destination folders are empty before moving files into them. When gulp 4 is released, it will support gulp.series and gulp.parallel methods natively, but for now we have to leave with this slight quirk in our setup.
Beyond that, this is actually pretty elegant. The whole creation and hosting of our app is performed in a single command, and understanding any portion of the workflow is as simple as examining an individual task in the run sequence. In addition, we can break the whole sequence into smaller chunks for a more granular approach to creating and hosting the app. For example, we could set up a separate task called validate that runs the lint and test tasks. Or we could have a host task that runs server and watch. This ability to orchestrate tasks is very powerful, especially as your application scales and requires more automated tasks.
Development vs Production Builds
if (argv.prod) {
process.env.NODE_ENV = 'production';
}
let PROD = process.env.NODE_ENV === 'production';
Using the yargs NPM library, we can supply command line flags to Gulp. Here I instruct the gulpfile to set the node environment to production if --prod is passed to gulp in the terminal. Our PROD variable is then used as a conditional to differentiate development and production behavior in our gulpfile. For example, one of the options we pass to our browserify config is:
plugin: PROD ? [] : [hmr, watchify]
This tells browserify to not use any plugins in production mode, and use hmr and watchify plugins in other environments.
This PROD conditional is very useful because it saves us from having to write a separate gulpfile for production and development, which would ultimately contain a lot of code repetition. Instead, we can do things like gulp --prod to run the default task in production, or gulp html --prod to only run the html task in production. On the other hand, we saw earlier that littering our Gulp pipelines with statements such as .pipe(cond(!PROD, livereload())) aren’t the most readable. In the end, it’s a matter of preference whether you want to use the boolean variable approach or set up two separate gulpfiles.
Now let’s see what happens when we keep using Gulp as our task runner but replace Browserify with Webpack.
Gulp + Webpack Setup
Suddenly our gulpfile is only 99 lines long with 12 imports, quite a reduction from our previous setup! If we check the default task:
gulp.task('default', (cb) => {
runSequence('lint', 'test', 'build', 'server', 'watch', cb);
});
Now our full web app setup only requires five tasks instead of nine, a dramatic improvement.
In addition, we’ve eliminated the need for livereload. Our watch task is now simply:
gulp.task('watch', () => {
gulp.watch(config.paths.js, () => {
runSequence('lint', 'test');
});
});
This means our gulp watcher isn’t triggering any type of rebundling behavior. As an added bonus, we don’t need to transfer index.html from app to dist or build anymore.
Returning our focus to the task reduction, our html, css, js and fonts tasks have all been replaced by a single build task:
gulp.task('build', () => {
runSequence('clean', 'html');
return gulp.src(config.paths.entry)
.pipe(webpack(require('./webpack.config')))
.pipe(gulp.dest(config.paths.baseDir));
});
Simple enough. Run the clean and html tasks in sequence. Once those are complete, grab our entrypoint, pipe it through Webpack, passing in a webpack.config.js file to configure it, and send the resulting bundle to our baseDir (either dist or build, depending on node env).
Let’s have a look at the Webpack config file:
This is a pretty large and intimidating config file, so let’s explain some of the important properties being set on our module.exports object.
devtool: PROD ? 'source-map' : 'eval-source-map',
This sets the type of sourcemaps that Webpack will use. Not only does Webpack support sourcemaps out of the box, it actually supports a wide array of sourcemap options. Each option provides a different balance of sourcemap detail vs. rebuild speed (the time taken to rebundle on changes). This means we can use a “cheap” sourcemap option for development to achieve fast reloads, and a more expensive sourcemap option in production.
entry: PROD ? './app/index' :
[
'webpack-hot-middleware/client?reload=true', // reloads the page if hot module reloading fails.
'./app/index'
]
This is our bundle entry point. Notice that an array is passed, meaning it’s possible to have multiple entry points. In this case, we have our expected entry point app/index.js as well as the webpack-hot-middleware entry point that’s used as part of our hot module reloading setup.
output: {
path: PROD ? __dirname + '/build' : __dirname + '/dist',
publicPath: '/',
filename: 'bundle.js'
},
This is where the compiled bundle will be output. The most confusing option is publicPath. It sets the base url for where your bundle will be hosted on the server. So, for example, if your publicPath is /public/assets, then the bundle will appear under /public/assets/bundle.js on the server.
devServer: {
contentBase: PROD ? './build' : './app'
}
This tells the server which folder in your project to use as the server’s root directory.
If you ever get confused about how Webpack is mapping the created bundle in your project to the bundle on the server, simply remember the following:
-
path+filename: The exact location of the bundle in your project source code -
contentBase(as the root,/) +publicPath: The location of the bundle on the server
plugins: PROD ?
[
new webpack.optimize.OccurenceOrderPlugin(),
new webpack.DefinePlugin(GLOBALS),
new ExtractTextPlugin('bundle.css'),
new webpack.optimize.DedupePlugin(),
new webpack.optimize.UglifyJsPlugin({compress: {warnings: false}})
] :
[
new webpack.HotModuleReplacementPlugin(),
new webpack.NoErrorsPlugin()
],
These are plugins that enhance Webpack’s functionality in some way. For example, webpack.optimize.UglifyJsPlugin is responsible for minification.
loaders: [
{test: /\.js$/, include: path.join(__dirname, 'app'), loaders: ['babel']},
{
test: /\.css$/,
loader: PROD ?
ExtractTextPlugin.extract('style', 'css?sourceMap'):
'style!css?sourceMap'
},
{
test: /\.scss$/,
loader: PROD ?
ExtractTextPlugin.extract('style', 'css?sourceMap!resolve-url!sass?sourceMap') :
'style!css?sourceMap!resolve-url!sass?sourceMap'
},
{test: /\.(svg|png|jpe?g|gif)(\?\S*)?$/, loader: 'url?limit=100000&name=img/[name].[ext]'},
{test: /\.(eot|woff|woff2|ttf)(\?\S*)?$/, loader: 'url?limit=100000&name=fonts/[name].[ext]'}
]
These are loaders. Essentially, they pre-process files that are loaded through require() statements. They are somewhat similar to Gulp pipes in that you can chain loaders together.
Let’s examine one of our loader objects:
{test: /\.scss$/, loader: 'style!css?sourceMap!resolve-url!sass?sourceMap'}
The test property tells Webpack that the given loader applies if a file matches the provided regex pattern, in this case /\.scss$/. The loader property corresponds to the action the loader performs. Here we are chaining together the style, css, resolve-url and sass loaders, which are executed in reverse order.
I must admit that I don’t find the loader3!loader2!loader1 syntax very elegant. After all, when do you ever have to read anything in a program from right to left? Despite this, loaders are a very powerful feature of webpack. In fact, the loader I just mentioned allows us to import SASS files directly into our JavaScript! For instance, we can import our vendor and global stylesheets in our entrypoint file:
index.js
import React from 'react';
import {render} from 'react-dom';
import {Router, browserHistory} from 'react-router';
import routes from './routes';
// CSS imports
import '../node_modules/bootstrap/dist/css/bootstrap.css';
import '../node_modules/font-awesome/css/font-awesome.css';
import './styles/global.scss';
render(<Router history={browserHistory} routes={routes} />, document.getElementById('app'));
Similarly, in our Header component we can add import './Header.scss' to import the component’s associated stylesheet. This also applies to all our other components.
In my opinion, this can almost be considered a revolutionary change in the world of JavaScript development. There’s no need to worry about CSS bundling, minification, or sourcemaps since our loader handles all of this for us. Even hot module reloading works for our CSS files. Then being able to handle JS and CSS imports in the same file makes development conceptually simpler: More consistency, less context switching, and easier to reason about.
To give a brief summary of how this feature works: Webpack inlines the CSS into our JS bundle. In fact, Webpack can do this for images and fonts as well:
{test: /\.(svg|png|jpe?g|gif)(\?\S*)?$/, loader: 'url?limit=100000&name=img/[name].[ext]'},
{test: /\.(eot|woff|woff2|ttf)(\?\S*)?$/, loader: 'url?limit=100000&name=fonts/[name].[ext]'}
The URL loader instructs Webpack to inline our images and fonts as data urls if they are under 100 KB, otherwise serve them as separate files. Of course, we can also configure the cutoff size to a different value such as 10 KB.
And that’s Webpack configuration in a nutshell. I will admit there’s a fair amount of setup, but the benefits of using it are simply phenomenal. Although Browserify does have plugins and transforms, they simply cannot compare to Webpack loaders in terms of added functionality.
Webpack + NPM Scripts Setup
In this setup, we use npm scripts directly instead of relying on a gulpfile for automating our tasks.
package.json
"scripts": {
"start": "npm-run-all --parallel lint:watch test:watch build",
"start:prod": "npm-run-all --parallel lint test build:prod",
"clean-dist": "rimraf ./dist && mkdir dist",
"clean-build": "rimraf ./build && mkdir build",
"clean": "npm-run-all clean-dist clean-build",
"test": "mocha ./app/**/*.test.js --compilers js:babel-core/register",
"test:watch": "npm run test -- --watch",
"lint": "esw ./app/**/*.js",
"lint:watch": "npm run lint -- --watch",
"server": "nodemon server.js",
"server:prod": "cross-env NODE_ENV=production nodemon server.js",
"build-html": "node tools/buildHtml.js",
"build-html:prod": "cross-env NODE_ENV=production node tools/buildHtml.js",
"prebuild": "npm-run-all clean-dist build-html",
"build": "webpack",
"postbuild": "npm run server",
"prebuild:prod": "npm-run-all clean-build build-html:prod",
"build:prod": "cross-env NODE_ENV=production webpack",
"postbuild:prod": "npm run server:prod"
}
To run development and production builds, enter npm start and npm run start:prod, respectively.
This is certainly more compact than our gulpfile, given we’ve cut 99 to 150 lines of code down to 19 NPM scripts, or 12 if we exclude the production scripts (most of which just mirror the development scripts with the node environment set to production). The drawback is that these commands are somewhat cryptic compared to our Gulp task counterparts, and not quite as expressive. For example, there’s no way (at least that I know of) to have a single npm script run certain commands in series and others in parallel. It’s either one or the other.
However, there is a huge advantage to this approach. By using NPM libraries such as mocha directly from the command line, you don’t need to install an equivalent Gulp wrapper for each (in this case, gulp-mocha).
Instead of NPM installing
- gulp-eslint
- gulp-mocha
- gulp-nodemon
- etc
We install the following packages:
- eslint
- mocha
- nodemon
- etc
Quoting Cory House’s post, Why I Left Gulp and Grunt for NPM Scripts:
I was a big fan of Gulp. But on my last project, I ended up with hundreds of lines in my gulpfile and around a dozen Gulp plugins. I was struggling to integrate Webpack, Browsersync, hot reloading, Mocha, and much more using Gulp. Why? Well, some plugins had insufficient documentation for my use case. Some plugins only exposed part of the API I needed. One had an odd bug where it would only watch a small number of files. Another stripped colors when outputting to the command line.
He specifies three core issues with Gulp:
- Dependence on plugin authors
- Frustrating to debug
- Disjointed documentation
I would tend to agree with all of these.
1. Dependence on Plugin Authors
Whenever a library such as eslint gets updated, the associated gulp-eslint library needs a corresponding update. If the library maintainer loses interest, the gulp version of the library falls out of sync with the native one. The same goes for when a new library is created. If someone creates a library xyz and it catches on, then suddenly you need a corresponding gulp-xyz library to use it in your gulp tasks.
In a sense, this approach just doesn’t scale. Ideally, we would want an approach like Gulp that can use the native libraries.
2. Frustrating to Debug
Although libraries such as gulp-plumber help alleviate this issue considerably, it’s nonetheless true that error reporting in gulp just isn’t very helpful. If even one pipe throws an unhandled exception, you get a stack trace for an issue that seems completely unrelated to what’s causing the issue in your source code. This can make debugging a nightmare in some cases. No amount of searching on Google or Stack Overflow can really help you if the error is cryptic or misleading enough.
3. Disjointed Documentation
Oftentimes I find that small gulp libraries tend to have very limited documentation. I suspect this is because the author usually makes the library primarily for his or her own use. In addition, it’s common to have to look at documentation for both the Gulp plugin and the native library itself, which means lots of context switching and twice as much reading to do.
Conclusion
It seems pretty clear to me that Webpack is preferable to Browserify and NPM scripts are preferable to Gulp, although each option has its benefits and drawbacks. Gulp is certainly more expressive and convenient to use than NPM scripts, but you pay the price in all the added abstraction.
Not every combination may be perfect for your app, but if you want to avoid an overwhelming number of development dependencies and a frustrating debugging experience, Webpack with NPM scripts is the way to go. I hope you will find this article useful in choosing the right tools for your next project.
About the author
Eric is a full-stack developer specializing in front-end work using React, Node, and HAPI. His passion is cutting-edge technology.