Clean Code and the Art of Exception Handling
Exceptions are a fundamental element of modern programming—and nothing to fear. Implement these exception handling best practices to write clean code that is easier to maintain.

Exceptions are a fundamental element of modern programming—and nothing to fear. Implement these exception handling best practices to write clean code that is easier to maintain.

Ahmed is a back-end (API) developer who loves building useful and fun tools. He also has experience as a web developer.
Expertise
Exceptions are as old as programming itself. Back in the days when programming was done in hardware, or via low-level programming languages, exceptions were used to alter the flow of the program, and to avoid hardware failures. Today, Wikipedia defines exceptions as:
anomalous or exceptional conditions requiring special processing – often changing the normal flow of program execution…
And that handling them requires:
specialized programming language constructs or computer hardware mechanisms.
So, exceptions require special treatment, and an unhandled exception may cause unexpected behavior. The results are often spectacular. In 1996, the famous Ariane 5 rocket launch failure was attributed to an unhandled overflow exception. History’s Worst Software Bugs contains some other bugs that could be attributed to unhandled or miss-handled exceptions.
Over time, these errors, and countless others (that were, perhaps, not as dramatic, but still catastrophic for those involved) contributed to the impression that exceptions are bad.
But exceptions are a fundamental element of modern programming; they exist to make our software better. Rather than fearing exceptions, we should embrace them and learn how to benefit from them. In this article, we will discuss how to manage exceptions elegantly, and use them to write clean code that is more maintainable.
Exception Handling: It’s a Good Thing
With the rise of object-oriented programming (OOP), exception support has become a crucial element of modern programming languages. A robust exception handling system is built into most languages, nowadays. For example, Ruby provides for the following typical pattern:
begin
do_something_that_might_not_work!
rescue SpecificError => e
do_some_specific_error_clean_up
retry if some_condition_met?
ensure
this_will_always_be_executed
end
There is nothing wrong with the previous code. But overusing these patterns will cause code smells, and won’t necessarily be beneficial. Likewise, misusing them can actually do a lot of harm to your code base, making it brittle, or obfuscating the cause of errors.
The stigma surrounding exceptions often makes programmers feel at a loss. It’s a fact of life that exceptions can’t be avoided, but we are often taught they must be dealt with swiftly and decisively. As we will see, this is not necessarily true. Rather, we should learn the art of handling exceptions gracefully, making them harmonious with the rest of our code.
Following are some recommended practices that will help you embrace exceptions and make use of them and their abilities to keep your code maintainable, extensible, and readable:
- maintainability: Allows us to easily find and fix new bugs, without the fear of breaking current functionality, introducing further bugs, or having to abandon the code altogether due to increased complexity over time.
- extensibility: Allows us to easily add to our code base, implementing new or changed requirements without breaking existing functionality. Extensibility provides flexibility, and enables a high level of reusability for our code base.
- readability: Allows us to easily read the code and discover it’s purpose without spending too much time digging. This is critical for efficiently discovering bugs and untested code.
These elements are the main factors of what we might call cleanliness or quality, which is not a direct measure itself, but instead is the combined effect of the previous points, as demonstrated in this comic:

With that said, let’s dive into these practices and see how each of them affects those three measures.
Note: We will present examples from Ruby, but all of the constructs demonstrated here have equivalents in the most common OOP languages.
Always create your own ApplicationError hierarchy
Most languages come with a variety of exception classes, organized in an inheritance hierarchy, like any other OOP class. To preserve the readability, maintainability, and extensibility of our code, it’s a good idea to create our own subtree of application-specific exceptions that extend the base exception class. Investing some time in logically structuring this hierarchy can be extremely beneficial. For example:
class ApplicationError < StandardError; end
# Validation Errors
class ValidationError < ApplicationError; end
class RequiredFieldError < ValidationError; end
class UniqueFieldError < ValidationError; end
# HTTP 4XX Response Errors
class ResponseError < ApplicationError; end
class BadRequestError < ResponseError; end
class UnauthorizedError < ResponseError; end
# ...
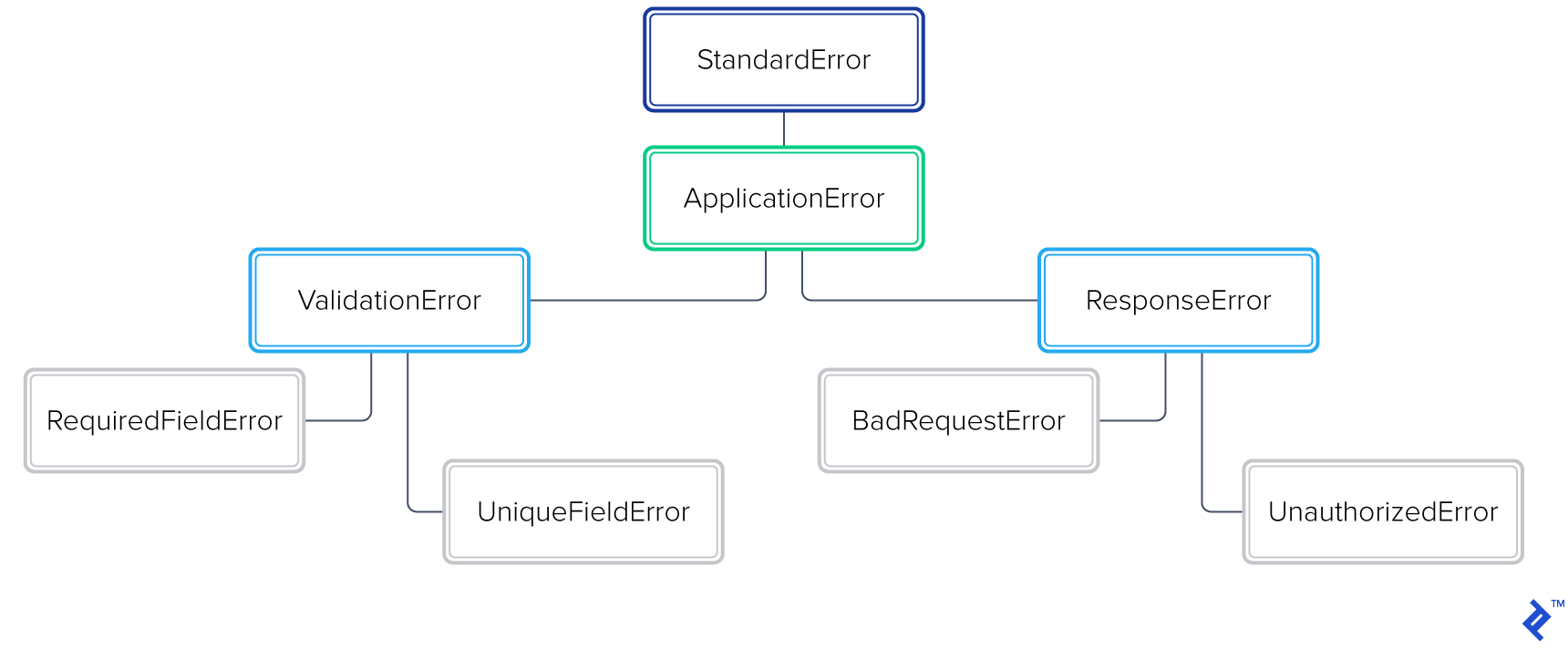
Having an extensible, comprehensive exceptions package for our application makes handling these application-specific situations much easier. For example, we can decide which exceptions to handle in a more natural way. This not only boosts the readability of our code, but also increases the maintainability of our applications and libraries (gems).
From the readability perspective, it’s much easier to read:
rescue ValidationError => e
Than to read:
rescue RequiredFieldError, UniqueFieldError, ... => e
From the maintainability perspective, say, for example, we are implementing a JSON API, and we have defined our own ClientError with several subtypes, to be used when a client sends a bad request. If any one of these is raised, the application should render the JSON representation of the error in its response. It will be easier to fix, or add logic, to a single block that handles ClientErrors rather than looping over each possible client error and implementing the same handler code for each. In terms of extensibility, if we later have to implement another type of client error, we can trust it will already be handled properly here.
Moreover, this does not prevent us from implementing additional special handling for specific client errors earlier in the call stack, or altering the same exception object along the way:
# app/controller/pseudo_controller.rb
def authenticate_user!
fail AuthenticationError if token_invalid? || token_expired?
User.find_by(authentication_token: token)
rescue AuthenticationError => e
report_suspicious_activity if token_invalid?
raise e
end
def show
authenticate_user!
show_private_stuff!(params[:id])
rescue ClientError => e
render_error(e)
end
As you can see, raising this specific exception didn’t prevent us from being able to handle it on different levels, altering it, re-raising it, and allowing the parent class handler to resolve it.
Two things to note here:
- Not all languages support raising exceptions from within an exception handler.
- In most languages, raising a new exception from within a handler will cause the original exception to be lost forever, so it’s better to re-raise the same exception object (as in the above example) to avoid losing track of the original cause of the error. (Unless you are doing this intentionally).
Never rescue Exception
That is, never try to implement a catch-all handler for the base exception type. Rescuing or catching all exceptions wholesale is never a good idea in any language, whether it’s globally on a base application level, or in a small buried method used only once. We don’t want to rescue Exception because it will obfuscate whatever really happened, damaging both maintainability and extensibility. We can waste a huge amount of time debugging what the actual problem is, when it could be as simple as a syntax error:
# main.rb
def bad_example
i_might_raise_exception!
rescue Exception
nah_i_will_always_be_here_for_you
end
# elsewhere.rb
def i_might_raise_exception!
retrun do_a_lot_of_work!
end
You might have noticed the error in the previous example; return is mistyped. Although modern editors provide some protection against this specific type of syntax error, this example illustrates how rescue Exception does harm to our code. At no point is the actual type of the exception (in this case a NoMethodError) addressed, nor is it ever exposed to the developer, which may cause us to waste a lot of time running in circles.
Never rescue more exceptions than you need to
The previous point is a specific case of this rule: We should always be careful not to over-generalize our exception handlers. The reasons are the same; whenever we rescue more exceptions than we should, we end up hiding parts of the application logic from higher levels of the application, not to mention suppressing the developer’s ability to handle the exception his or herself. This severely affects the extensibility and maintainability of the code.
If we do attempt to handle different exception subtypes in the same handler, we introduce fat code blocks that have too many responsibilities. For example, if we are building a library that consumes a remote API, handling a MethodNotAllowedError (HTTP 405), is usually different from handling an UnauthorizedError (HTTP 401), even though they are both ResponseErrors.
As we will see, often there exists a different part of the application that would be better suited to handle specific exceptions in a more DRY way.
So, define the single responsibility of your class or method, and handle the bare minimum of exceptions that satisfy this responsibility requirement. For example, if a method is responsible for getting stock info from a remote a API, then it should handle exceptions that arise from getting that info only, and leave the handling of the other errors to a different method designed specifically for these responsibilities:
def get_info
begin
response = HTTP.get(STOCKS_URL + "#{@symbol}/info")
fail AuthenticationError if response.code == 401
fail StockNotFoundError, @symbol if response.code == 404
return JSON.parse response.body
rescue JSON::ParserError
retry
end
end
Here we defined the contract for this method to only get us the info about the stock. It handles endpoint-specific errors, such as an incomplete or malformed JSON response. It doesn’t handle the case when authentication fails or expires, or if the stock doesn’t exist. These are someone else’s responsibility, and are explicitly passed up the call stack where there should be a better place to handle these errors in a DRY way.
Resist the urge to handle exceptions immediately
This is the complement to the last point. An exception can be handled at any point in the call stack, and any point in the class hierarchy, so knowing exactly where to handle it can be mystifying. To solve this conundrum, many developers opt to handle any exception as soon as it arises, but investing time in thinking this through will usually result in finding a more appropriate place to handle specific exceptions.
One common pattern that we see in Rails applications (especially those that expose JSON-only APIs) is the following controller method:
# app/controllers/client_controller.rb
def create
@client = Client.new(params[:client])
if @client.save
render json: @client
else
render json: @client.errors
end
end
(Note that although this is not technically an exception handler, functionally, it serves the same purpose, since @client.save only returns false when it encounters an exception.)
In this case, however, repeating the same error handler in every controller action is the opposite of DRY, and damages maintainability and extensibility. Instead, we can make use of the special nature of exception propagation, and handle them only once, in the parent controller class, ApplicationController:
# app/controllers/client_controller.rb
def create
@client = Client.create!(params[:client])
render json: @client
end
# app/controller/application_controller.rb
rescue_from ActiveRecord::RecordInvalid, with: :render_unprocessable_entity
def render_unprocessable_entity(e)
render \
json: { errors: e.record.errors },
status: 422
end
This way, we can ensure that all of the ActiveRecord::RecordInvalid errors are properly and DRY-ly handled in one place, on the base ApplicationController level. This gives us the freedom to fiddle with them if we want to handle specific cases at the lower level, or simply let them propagate gracefully.
Not all exceptions need handling
When developing a gem or a library, many developers will try to encapsulate the functionality and not allow any exception to propagate out of the library. But sometimes, it’s not obvious how to handle an exception until the specific application is implemented.
Let’s take ActiveRecord as an example of the ideal solution. The library provides developers with two approaches for completeness. The save method handles exceptions without propagating them, simply returning false, while save! raises an exception when it fails. This gives developers the option of handling specific error cases differently, or simply handling any failure in a general way.
But what if you don’t have the time or resources to provide such a complete implementation? In that case, if there is any uncertainty, it is best to expose the exception, and release it into the wild.
Here’s why: We are working with moving requirements almost all the time, and making the decision that an exception will always be handled in a specific way might actually harm our implementation, damaging extensibility and maintainability, and potentially adding huge technical debt, especially when developing libraries.
Take the earlier example of a stock API consumer fetching stock prices. We chose to handle the incomplete and malformed response on the spot, and we chose to retry the same request again until we got a valid response. But later, the requirements might change, such that we must fall back to saved historical stock data, instead of retrying the request.
At this point, we will be forced to change the library itself, updating how this exception is handled, because the dependent projects won’t handle this exception. (How could they? It was never exposed to them before.) We will also have to inform the owners of projects that rely on our library. This might become a nightmare if there are many such projects, since they are likely to have been built on the assumption that this error will be handled in a specific way.
Now, we can see where we are heading with dependencies management. The outlook is not good. This situation happens quite often, and more often than not, it degrades the library’s usefulness, extensibility, and flexibility.
So here is the bottom line: if it is unclear how an exception should be handled, let it propagate gracefully. There are many cases where a clear place exists to handle the exception internally, but there are many other cases where exposing the exception is better. So before you opt into handling the exception, just give it a second thought. A good rule of thumb is to only insist on handling exceptions when you are interacting directly with the end-user.
Follow the convention
The implementation of Ruby, and, even more so, Rails, follows some naming conventions, such as distinguishing between method_names and method_names! with a “bang.” In Ruby, the bang indicates that the method will alter the object that invoked it, and in Rails, it means that the method will raise an exception if it fails to execute the expected behavior. Try to respect the same convention, especially if you are going to open-source your library.
If we were to write a new method! with a bang in a Rails application, we must take these conventions into account. There is nothing forcing us to raise an exception when this method fails, but by deviating from the convention, this method may mislead programmers into believing they will be given the chance to handle exceptions themselves, when, in fact, they will not.
Another Ruby convention, attributed to Jim Weirich, is to use fail to indicate method failure, and only to use raise if you are re-raising the exception.
An aside, because I use exceptions to indicate failures, I almost always use the
failkeyword rather than theraisekeyword in Ruby. Fail and raise are synonyms so there is no difference except that fail more clearly communicates that the method has failed. The only time I use raise is when I am catching an exception and re-raising it, because here I’m not failing, but explicitly and purposefully raising an exception. This is a stylistic issue I follow, but I doubt many other people do.
Many other language communities have adopted conventions like these around how exceptions are treated, and ignoring these conventions will damage the readability and maintainability of our code.
Logger.log(everything)
This practice doesn’t solely apply to exceptions, of course, but if there’s one thing that should always be logged, it’s an exception.
Logging is extremely important (important enough for Ruby to ship a logger with its standard version). It’s the diary of our applications, and even more important than keeping a record of how our applications succeed, is logging how and when they fail.
There is no shortage of logging libraries or log-based services and design patterns. It’s critical to keep track of our exceptions so we can review what happened and investigate if something doesn’t look right. Proper log messages can point developers directly to the cause of a problem, saving them immeasurable time.
That Clean Code Confidence
Exceptions are a fundamental part of every programming language. They are special and extremely powerful, and we must leverage their power to elevate the quality of our code instead of exhausting ourselves fighting with them.
In this article, we dived into some good practices for structuring our exception trees and how it can be beneficial for readability and quality to logically structure them. We looked at different approaches for handling exceptions, either in one place or on multiple levels.
We saw that it’s bad to “catch ‘em all”, and that it’s ok to let them float around and bubble up.
We looked at where to handle exceptions in a DRY manner, and learned that we are not obligated to handle them when or where they first arise.
We discussed when exactly it is a good idea to handle them, when it’s a bad idea, and why, when in doubt, it’s a good idea to let them propagate.
Finally, we discussed other points that can help maximize the usefulness of exceptions, such as following conventions and logging everything.
With these basic guidelines, we can feel much more comfortable and confident dealing with error cases in our code, and making our exceptions truly exceptional!
Special thanks to Avdi Grimm and his awesome talk Exceptional Ruby, which helped a lot in the making of this article.
Further Reading on the Toptal Blog:
Understanding the basics
What are clean code exceptions?
Clean code exception refers to writing exceptions in your code in a way that makes them manageable, clear, and understandable. On a broader level, “clean code” refers to code that is easy to maintain, read, and understand.
What is the purpose of exception handling in programming?
The purpose of exception handling is to respond to and manage errors that arise in the execution of a program. Without it, unhandled errors can lead to crashes, unpredictable behavior, data corruption, and poor user experience.
What is exception handling?
Exception handling is a process used for handling errors and exceptions that can happen during the execution of a program. Unhandled exceptions can cause programs to crash or behave in unexpected ways.
Exception handling vs error handling: what's the difference?
Error handling is a broad term that includes all techniques used to manage and respond to errors that occur during the execution of a program. Exception handling is a subset of error handling, specifically to address anomalies that occur during the runtime of a program.
Berlin, Germany
Member since August 6, 2014
About the author
Ahmed is a back-end (API) developer who loves building useful and fun tools. He also has experience as a web developer.