Ruby Concurrency and Parallelism: A Practical Tutorial
A thorough and practical introduction to concurrent and parallel programming in Ruby, presenting and contrasting a number of techniques and options available, from the standpoints of both performance and complexity. Discusses forking, multithreading, the Global Interpreter Lock (GIL), and more.
A thorough and practical introduction to concurrent and parallel programming in Ruby, presenting and contrasting a number of techniques and options available, from the standpoints of both performance and complexity. Discusses forking, multithreading, the Global Interpreter Lock (GIL), and more.

Eqbal is a senior full-stack developer with more than a decade of experience working in web and mobile development.
Expertise
PREVIOUSLY AT

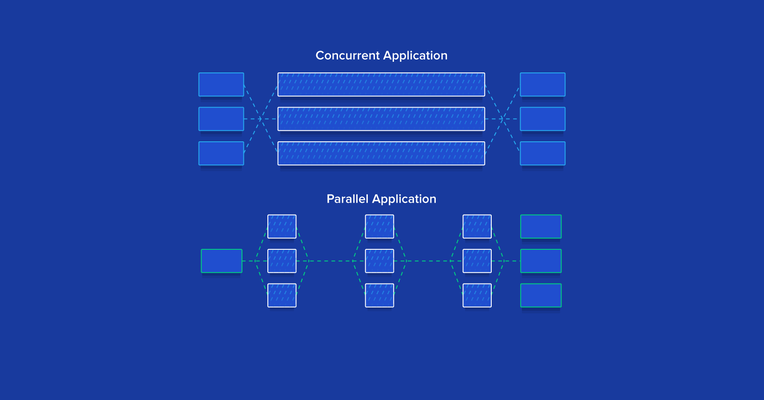
Let’s start by clearing up an all-too-common point of confusion among Ruby developers; namely: Concurrency and parallelism are not the same thing (i.e., concurrent != parallel).
In particular, Ruby concurrency is when two tasks can start, run, and complete in overlapping time periods. It doesn’t necessarily mean, though, that they’ll ever both be running at the same instant (e.g., multiple threads on a single-core machine). In contrast, parallelism is when two tasks literally run at the same time (e.g., multiple threads on a multicore processor).
The key point here is that concurrent threads and/or processes will not necessarily be running in parallel.
This tutorial provides a practical (rather than theoretical) treatment of the various techniques and approaches that are available for concurrency and parallelism in Ruby.
For more real world Ruby examples, see our article about Ruby Interpreters and Runtimes.
Our Test Case
For a simple test case, I’ll create a Mailer class and add a Fibonacci function (rather than the sleep() method) to make each request more CPU-intensive, as follows:
class Mailer
def self.deliver(&block)
mail = MailBuilder.new(&block).mail
mail.send_mail
end
Mail = Struct.new(:from, :to, :subject, :body) do
def send_mail
fib(30)
puts "Email from: #{from}"
puts "Email to : #{to}"
puts "Subject : #{subject}"
puts "Body : #{body}"
end
def fib(n)
n < 2 ? n : fib(n-1) + fib(n-2)
end
end
class MailBuilder
def initialize(&block)
@mail = Mail.new
instance_eval(&block)
end
attr_reader :mail
%w(from to subject body).each do |m|
define_method(m) do |val|
@mail.send("#{m}=", val)
end
end
end
end
We can then invoke this Mailer class as follows to send mail:
Mailer.deliver do
from "eki@eqbalq.com"
to "jill@example.com"
subject "Threading and Forking"
body "Some content"
end
(Note: The source code for this test case is available here on github.)
To establish a baseline for comparison purposes, let’s begin by doing a simple benchmark, invoking the mailer 100 times:
puts Benchmark.measure{
100.times do |i|
Mailer.deliver do
from "eki_#{i}@eqbalq.com"
to "jill_#{i}@example.com"
subject "Threading and Forking (#{i})"
body "Some content"
end
end
}
This yielded the following results on a quad-core processor with MRI Ruby 2.0.0p353:
15.250000 0.020000 15.270000 ( 15.304447)
Multiple Processes vs. Multithreading
There is no “one size fits all” answer when it comes to deciding whether to use multiple processes or to multithread your Ruby application. The table below summarizes some of the key factors to consider.
| Processes | Threads |
|---|---|
| Uses more memory | Uses less memory |
| If parent dies before children have exited, children can become zombie processes | All threads die when the process dies (no chance of zombies) |
| More expensive for forked processes to switch context since OS needs to save and reload everything | Threads have considerably less overhead since they share address space and memory |
| Forked processes are given a new virtual memory space (process isolation) | Threads share the same memory, so need to control and deal with concurrent memory issues |
| Requires inter-process communication | Can "communicate" via queues and shared memory |
| Slower to create and destroy | Faster to create and destroy |
| Easier to code and debug | Can be significantly more complex to code and debug |
Examples of Ruby solutions that use multiple processes:
- Resque: A Redis-backed Ruby library for creating background jobs, placing them on multiple queues, and processing them later.
- Unicorn: An HTTP server for Rack applications designed to only serve fast clients on low-latency, high-bandwidth connections and take advantage of features in Unix/Unix-like kernels.
Examples of Ruby solutions that use multithreading:
- Sidekiq: A full-featured background processing framework for Ruby. It aims to be simple to integrate with any modern Rails application and much higher performance than other existing solutions.
- Puma: A Ruby web server built for concurrency.
- Thin: A very fast and simple Ruby web server.
Multiple Processes
Before we look into Ruby multithreading options, let’s explore the easier path of spawning multiple processes.
In Ruby, the fork() system call is used to create a “copy” of the current process. This new process is scheduled at the operating system level, so it can run concurrently with the original process, just as any other independent process can. (Note: fork() is a POSIX system call and is therefore not available if you are running Ruby on a Windows platform.)
OK, so let’s run our test case, but this time using fork() to employ multiple processes:
puts Benchmark.measure{
100.times do |i|
fork do
Mailer.deliver do
from "eki_#{i}@eqbalq.com"
to "jill_#{i}@example.com"
subject "Threading and Forking (#{i})"
body "Some content"
end
end
end
Process.waitall
}
(Process.waitall waits for all child processes to exit and returns an array of process statuses.)
This code now yields the following results (again, on a quad-core processor with MRI Ruby 2.0.0p353):
0.000000 0.030000 27.000000 ( 3.788106)
Not too shabby! We made the mailer ~5x faster by just modifying a couple of lines of code (i.e., using fork()).
Don’t get overly excited though. Although it might be tempting to use forking since it’s an easy solution for Ruby concurrency, it has a major drawback which is the amount of memory that it will consume. Forking is somewhat expensive, especially if a Copy-on-Write (CoW) is not utilized by the Ruby interpreter that you’re using. If your app uses 20MB of memory, for example, forking it 100 times could potentially consume as much as 2GB of memory!
Also, although multithreading has its own complexities as well, there are a number of complexities that need to be considered when using fork(), such as shared file descriptors and semaphores (between parent and child forked processes), the need to communicate via pipes, and so on.
Ruby Multithreading
OK, so now let’s try to make the same program faster using Ruby multithreading techniques instead.
Multiple threads within a single process have considerably less overhead than a corresponding number of processes since they share address space and memory.
With that in mind, let’s revisit our test case, but this time using Ruby’s Thread class:
threads = []
puts Benchmark.measure{
100.times do |i|
threads << Thread.new do
Mailer.deliver do
from "eki_#{i}@eqbalq.com"
to "jill_#{i}@example.com"
subject "Threading and Forking (#{i})"
body "Some content"
end
end
end
threads.map(&:join)
}
This code now yields the following results (again, on a quad-core processor with MRI Ruby 2.0.0p353):
13.710000 0.040000 13.750000 ( 13.740204)
Bummer. That sure isn’t very impressive! So what’s going on? Why is this producing almost the same results as we got when we ran the code synchronously?
The answer, which is the bane of existence of many a Ruby programmer, is the Global Interpreter Lock (GIL). Thanks to the GIL, CRuby (the MRI implementation) doesn’t really support threading.
The Global Interpreter Lock is a mechanism used in computer language interpreters to synchronize the execution of threads so that only one thread can execute at a time. An interpreter which uses GIL will always allow exactly one thread and one thread only to execute at a time, even if run on a multi-core processor. Ruby MRI and CPython are two of the most common examples of popular interpreters that have a GIL.
So back to our problem, how can we exploit multithreading in Ruby to improve performance in light of the GIL?
Well, in the MRI (CRuby), the unfortunate answer is that you’re basically stuck and there’s very little that multithreading can do for you.
Ruby concurrency without parallelism can still be very useful, though, for tasks that are IO-heavy (e.g., tasks that need to frequently wait on the network). So threads can still be useful in the MRI, for IO-heavy tasks. There is a reason threads were, after all, invented nd used even before multi-core servers were common.
But that said, if you have the option of using a version other than CRuby, you can use an alternative Ruby implementation such as JRuby or Rubinius, since they don’t have a GIL and they do support real parallel Ruby threading.
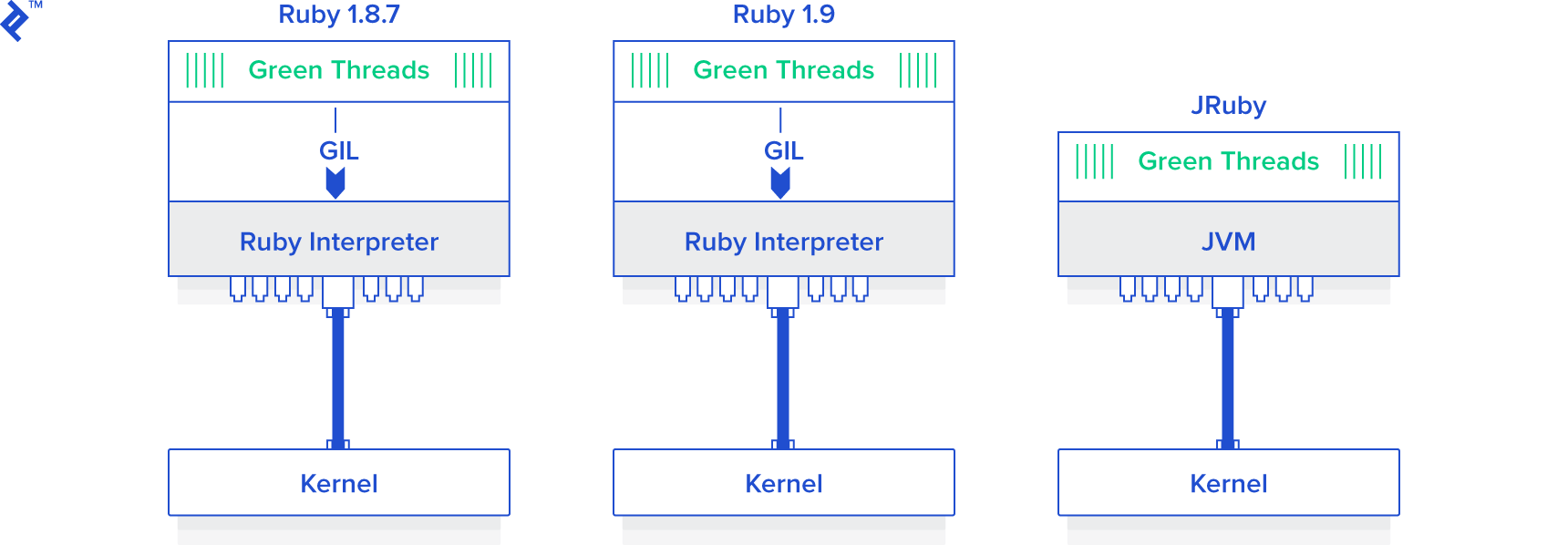
To prove the point, here are the results we get when we run the exact same threaded version of the code as before, but this time run it on JRuby (instead of CRuby):
43.240000 0.140000 43.380000 ( 5.655000)
Now we’re talkin’!
But…
Threads Ain’t Free
The improved performance with multiple threads might lead one to believe that we can just keep adding more threads – basically infinitely – to keep making our code run faster and faster. That would indeed be nice if it were true, but the reality is that threads are not free and so, sooner or later, you will run out of resources.
Let’s say, for example, that we want to run our sample mailer not 100 times, but 10,000 times. Let’s see what happens:
threads = []
puts Benchmark.measure{
10_000.times do |i|
threads << Thread.new do
Mailer.deliver do
from "eki_#{i}@eqbalq.com"
to "jill_#{i}@example.com"
subject "Threading and Forking (#{i})"
body "Some content"
end
end
end
threads.map(&:join)
}
Boom! I got an error with my OS X 10.8 after spawning around 2,000 threads:
can't create Thread: Resource temporarily unavailable (ThreadError)
As expected, sooner or later we start thrashing or run out of resources entirely. So the scalability of this approach is clearly limited.
Thread Pooling
Fortunately, there is a better way; namely, thread pooling.
A thread pool is a group of pre-instantiated, reusable threads that are available to perform work as needed. Thread pools are particularly useful when there are a large number of short tasks to be performed rather than a small number of longer tasks. This prevents having to incur the overhead of creating a thread a large number of times.
A key configuration parameter for a thread pool is typically the number of threads in the pool. These threads can either be instantiated all at once (i.e., when the pool is created) or lazily (i.e., as needed until the maximum number of threads in the pool has been created).
When the pool is handed a task to perform, it assigns the task to one of the currently idle threads. If no threads are idle (and the maximum number of threads have already been created) it waits for a thread to complete its work and become idle and then assigns the task to that thread.
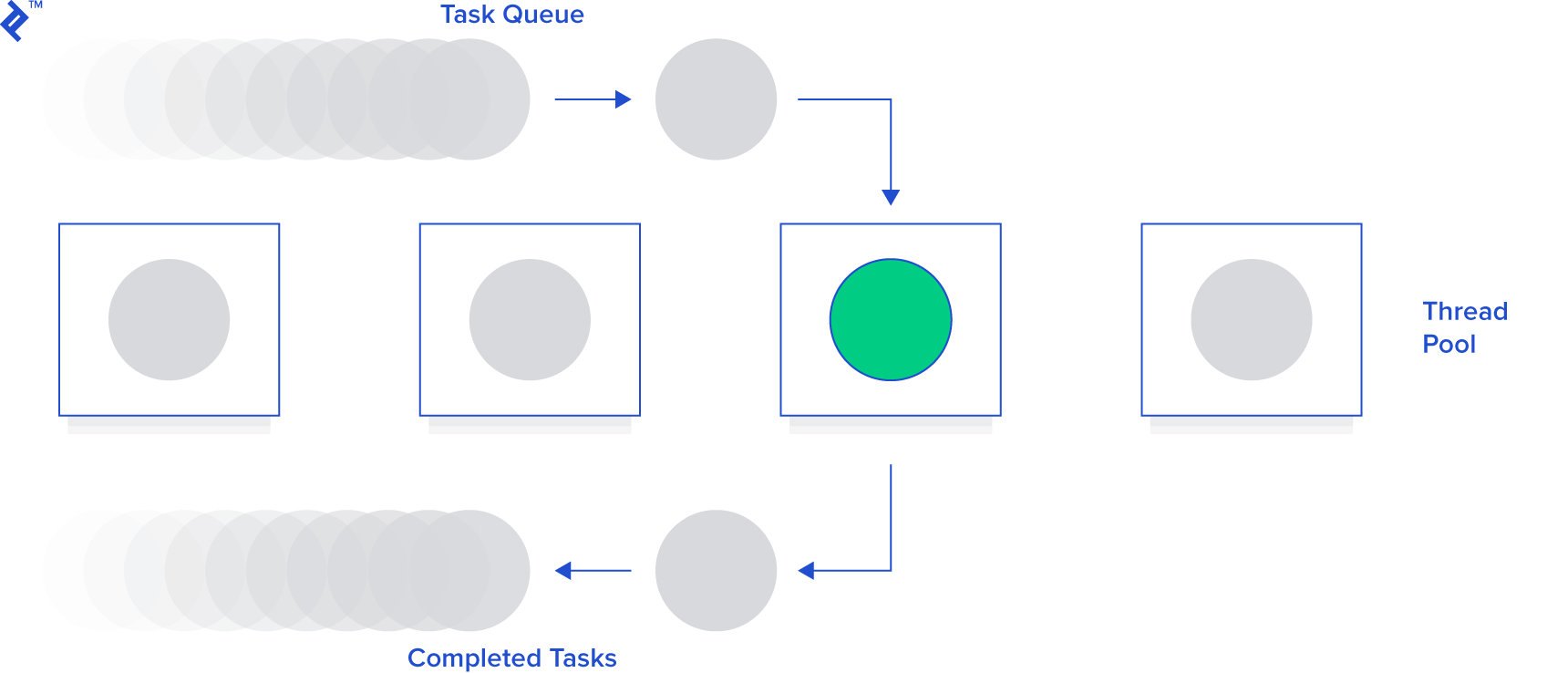
So, returning to our example, we’ll start by using Queue (since it’s a thread safe data type) and employ a simple implementation of the thread pool:
require “./lib/mailer” require “benchmark” require ‘thread’
POOL_SIZE = 10
jobs = Queue.new
10_0000.times{|i| jobs.push i}
workers = (POOL_SIZE).times.map do
Thread.new do
begin
while x = jobs.pop(true)
Mailer.deliver do
from "eki_#{x}@eqbalq.com"
to "jill_#{x}@example.com"
subject "Threading and Forking (#{x})"
body "Some content"
end
end
rescue ThreadError
end
end
end
workers.map(&:join)
In the above code, we started by creating a jobs queue for the jobs that need to be performed. We used Queue for this purpose since it’s thread-safe (so if multiple threads access it at the same time, it will maintain consistency) which avoids the need for a more complicated implementation requiring the use of a mutex.
We then pushed the IDs of the mailers to the job queue and created our pool of 10 worker threads.
Within each worker thread, we pop items from the jobs queue.
Thus, the life-cycle of a worker thread is to continuously wait for tasks to be put into the job Queue and execute them.
So the good news is that this works and scales without any problems. Unfortunately, though, this is fairly complicated even for our simple tutorial.
Celluloid
Thanks to the Ruby Gem ecosystem, much of the complexity of multithreading is neatly encapsulated in a number of easy-to-use Ruby Gems out-of-the-box.
A great example is Celluloid, one of my favorite ruby gems. Celluloid framework is a simple and clean way to implement actor-based concurrent systems in Ruby. Celluloid enables people to build concurrent programs out of concurrent objects just as easily as they build sequential programs out of sequential objects.
In the context of our discussion in this post, I’m specifically focusing on the Pools feature, but do yourself a favor and check it out in more detail. Using Celluloid you’ll be able to build multithreaded Ruby programs without worrying about nasty problems like deadlocks, and you’ll find it trivial to use other more sophisticated features like Futures and Promises.
Here’s how simple a multithreaded version of our mailer program is using Celluloid:
require "./lib/mailer"
require "benchmark"
require "celluloid"
class MailWorker
include Celluloid
def send_email(id)
Mailer.deliver do
from "eki_#{id}@eqbalq.com"
to "jill_#{id}@example.com"
subject "Threading and Forking (#{id})"
body "Some content"
end
end
end
mailer_pool = MailWorker.pool(size: 10)
10_000.times do |i|
mailer_pool.async.send_email(i)
end
Clean, easy, scalable, and robust. What more can you ask for?
Background Jobs
Of course, another potentially viable alternative, depending on your operational requirements and constraints would be to employ background jobs. A number of Ruby Gems exist to support background processing (i.e., saving jobs in a queue and processing them later without blocking the current thread). Notable examples include Sidekiq, Resque, Delayed Job, and Beanstalkd.
For this post, I’ll use Sidekiq and Redis (an open source key-value cache and store).
First, let’s install Redis and run it locally:
brew install redis
redis-server /usr/local/etc/redis.conf
With our local Redis instance running, let’s take a look at a version of our sample mailer program (mail_worker.rb) using Sidekiq:
require_relative "../lib/mailer"
require "sidekiq"
class MailWorker
include Sidekiq::Worker
def perform(id)
Mailer.deliver do
from "eki_#{id}@eqbalq.com"
to "jill_#{id}@example.com"
subject "Threading and Forking (#{id})"
body "Some content"
end
end
end
We can trigger Sidekiq with the mail_worker.rb file:
sidekiq -r ./mail_worker.rb
And then from IRB:
⇒ irb
>> require_relative "mail_worker"
=> true
>> 100.times{|i| MailWorker.perform_async(i)}
2014-12-20T02:42:30Z 46549 TID-ouh10w8gw INFO: Sidekiq client with redis options {}
=> 100
Awesomely simple. And it can scale easily by just changing the number of workers.
Another option is to use Sucker Punch, one of my favorite asynchronous RoR processing libraries. The implementation using Sucker Punch will be very similar. We’ll just need to include SuckerPunch::Job rather than Sidekiq::Worker, and MailWorker.new.async.perform() rather MailWorker.perform_async().
Conclusion
High concurrency is not only achievable in Ruby, but is also simpler than you might think.
One viable approach is simply to fork a running process to multiply its processing power. Another technique is to take advantage of multithreading. Although threads are lighter than processes, requiring less overhead, you can still run out of resources if you start too many threads concurrently. At some point, you may find it necessary to use a thread pool. Fortunately, many of the complexities of multithreading are made easier by leveraging any of a number of available gems, such as Celluloid and its Actor model.
Another way to handle time consuming processes is by using background processing. There are many libraries and services that allow you to implement background jobs in your applications. Some popular tools include database-backed job frameworks and message queues.
Forking, threading, and background processing are all viable alternatives. The decision as to which one to use depends on the nature of your application, your operational environment, and requirements. Hopefully this tutorial has provided a useful introduction to the options available.
Further Reading on the Toptal Blog:
Eqbal Quran
Amman, Amman Governorate, Jordan
Member since June 13, 2014
About the author
Eqbal is a senior full-stack developer with more than a decade of experience working in web and mobile development.
Expertise
PREVIOUSLY AT