JavaScript Prototype Chains, Scope Chains, and Performance: What You Need to Know
JavaScript is much more nuanced than most developers initially realize. Even for those with more experience, some of JavaScript’s most salient features continue to be misunderstood and lead to confusion. One such feature, described in this article, is the way that property and variable lookups are performed and the resulting performance ramifications to be aware of.

JavaScript is much more nuanced than most developers initially realize. Even for those with more experience, some of JavaScript’s most salient features continue to be misunderstood and lead to confusion. One such feature, described in this article, is the way that property and variable lookups are performed and the resulting performance ramifications to be aware of.

Diego has been a senior freelance engineer for the likes of Italian telecom powerhouse Italtel. He also cofounded a web-based CRM business.
Expertise
JavaScript: More than meets the eye
JavaScript can seem like a very easy language to learn at first. Perhaps it’s because of its flexible syntax. Or perhaps it’s because of its similarity to other well known languages like Java. Or perhaps it’s because it has so few data types in comparison to languages like Java, Ruby, or .NET.
But in truth, JavaScript is much less simplistic and more nuanced than most developers initially realize. Even for developers with more experience, some of JavaScript’s most salient features continue to be misunderstood and lead to confusion. One such feature is the way that data (property and variable) lookups are performed and the JavaScript performance ramifications to be aware of.
In JavaScript, data lookups are governed by two things: prototypal inheritance and scope chain. As a developer, clearly understanding these two mechanisms is essential, since doing so can improve the structure, and often the performance, of your code.
Property lookups through the prototype chain
When accessing a property in a prototype-based language like JavaScript, a dynamic lookup takes places that involves different layers within the object’s prototypal tree.
In JavaScript, every function is an object. When a function is invoked with the new operator, a new object is created. For example:
function Person(firstName, lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
var p1 = new Person('John', 'Doe');
var p2 = new Person('Robert', 'Doe');
In the above example, p1 and p2 are two different objects, each created using the Person function as a constructor. They are independent instances of Person, as demonstrated by this code snippet:
console.log(p1 instanceof Person); // prints 'true'
console.log(p2 instanceof Person); // prints 'true'
console.log(p1 === p2); // prints 'false'
Since JavaScript functions are objects, they can have properties. A particularly important property that each function has is called prototype.
prototype, which is itself an object, inherits from its parent’s prototype, which inherits from its parent’s prototype, and and so on. This is often referred to as the prototype chain. Object.prototype, which is always at the end of the prototype chain (i.e., at the top of the prototypal inheritance tree), contains methods like toString(), hasProperty(), isPrototypeOf(), and so on.
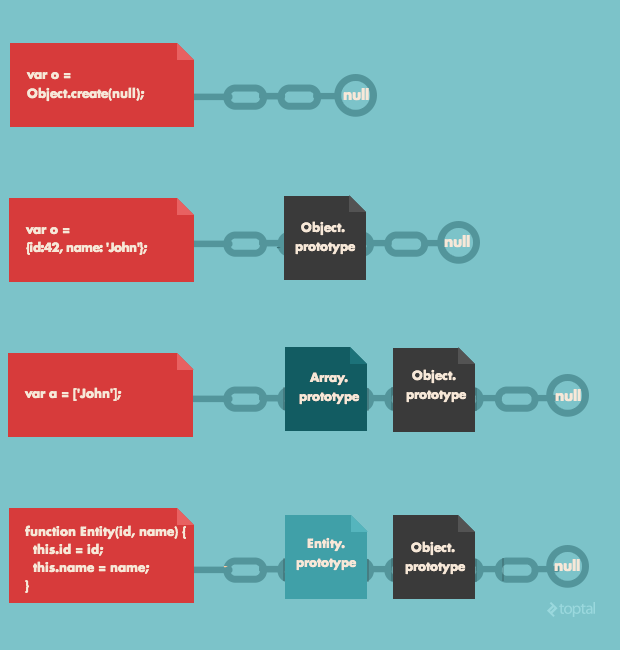
Each function’s prototype can be extended to define its own custom methods and properties.
When you instantiate an object (by invoking the function using the new operator), it inherits all the properties in the prototype of that function. Keep in mind, though, that those instances will not have direct access to the prototype object but only to its properties. For example:
// Extending the Person prototype from our earlier example to
// also include a 'getFullName' method:
Person.prototype.getFullName = function() {
return this.firstName + ' ' + this.lastName;
}
// Referencing the p1 object from our earlier example
console.log(p1.getFullName()); // prints 'John Doe'
// but p1 can’t directly access the 'prototype' object...
console.log(p1.prototype); // prints 'undefined'
console.log(p1.prototype.getFullName()); // generates an error
There’s an important and somewhat subtle point here: Even if p1 was created before the getFullName method was defined, it will still have access to it because its prototype is the Person prototype.
(It is worth noting that browsers also store a reference to the prototype of any object in a __proto__ property, but it’s really bad practice to directly access the prototype via the __proto__ property, since it’s not part of the standard ECMAScript Language Specification, so don’t do it!)
Since the p1 instance of the Person object doesn’t itself have direct access to the prototype object, if we want overwrite getFullName in p1, we would do so as follows:
// We reference p1.getFullName, *NOT* p1.prototype.getFullName,
// since p1.prototype does not exist:
p1.getFullName = function(){
return 'I am anonymous';
}
Now p1 has its own getFullName property. But the p2 instance (created in our earlier example) does not have any such property of its own. Therefore, invoking p1.getFullName() accesses the getFullName method of the p1 instance itself, while invoking p2.getFullName() goes up the prototype chain to the Person prototype object to resolve getFullName:
console.log(p1.getFullName()); // prints 'I am anonymous'
console.log(p2.getFullName()); // prints 'Robert Doe'
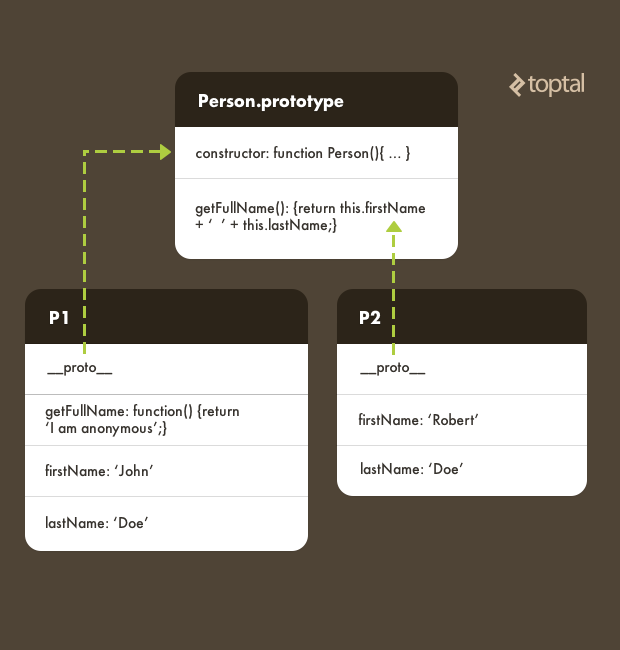
Another important thing to be aware of is that it’s also possible to dynamically change an object’s prototype. For example:
function Parent() {
this.someVar = 'someValue';
};
// extend Parent’s prototype to define a 'sayHello' method
Parent.prototype.sayHello = function(){
console.log('Hello');
};
function Child(){
// this makes sure that the parent's constructor is called and that
// any state is initialized correctly.
Parent.call(this);
};
// extend Child's prototype to define an 'otherVar' property...
Child.prototype.otherVar = 'otherValue';
// ... but then set the Child's prototype to the Parent prototype
// (whose prototype doesn’t have any 'otherVar' property defined,
// so the Child prototype no longer has ‘otherVar’ defined!)
Child.prototype = Object.create(Parent.prototype);
var child = new Child();
child.sayHello(); // prints 'Hello'
console.log(child.someVar); // prints 'someValue'
console.log(child.otherVar); // prints 'undefined'
When using prototypal inheritance, remember to define properties in the prototype after having either inherited from the parent class or specified an alternate prototype.
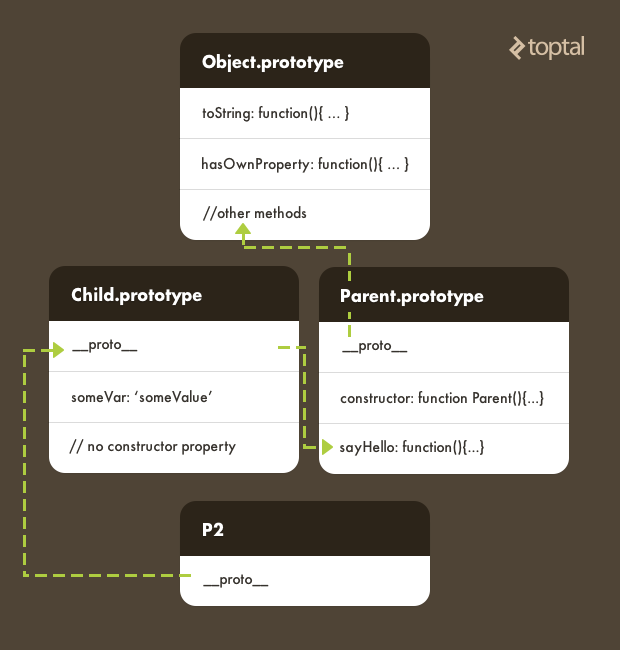
To summarize, property lookups through the JavaScript prototype chain work as follows:
- If the object has a property with the given name, that value is returned. (The
hasOwnPropertymethod can be used to check if an object has a particular named property.) - If the object does not have the named property, the object’s prototype is checked
- Since the prototype is an object as well, if it does not contain the property either, its parent’s prototype is checked.
- This process continues up the prototype chain until the property is found.
- If
Object.prototypeis reached and it does not have the property either, the property is consideredundefined.
Understanding how prototypal inheritance and property lookups work is important in general for developers but is also essential because of its (sometimes significant) JavaScript performance ramifications. As mentioned in the documentation for V8 (Google’s open source, high performance JavaScript engine), most JavaScript engines use a dictionary-like data structure to store object properties. Each property access therefore requires a dynamic look-up in that data structure to resolve the property. This approach makes accessing properties in JavaScript typically much slower than accessing instance variables in programming languages like Java and Smalltalk.
Variable lookups through the scope chain
Another lookup mechanism in JavaScript is based on scope.
To understand how this works, it’s necessary to introduce the concept of execution context.
In JavaScript, there are two types of execution contexts:
- Global context, created when a JavaScript process is launched
- Local context, created when a function is invoked
Execution contexts are organized into a stack. At the bottom of the stack, there is always the global context, that is unique for each JavaScript program. Each time a function is encountered, a new execution context is created and pushed onto the top of the stack. Once the function has finished executing, its context is popped off the stack.
Consider the following code:
// global context
var message = 'Hello World';
var sayHello = function(n){
// local context 1 created and pushed onto context stack
var i = 0;
var innerSayHello = function() {
// local context 2 created and pushed onto context stack
console.log((i + 1) + ': ' + message);
// local context 2 popped off of context stack
}
for (i = 0; i < n; i++) {
innerSayHello();
}
// local context 1 popped off of context stack
};
sayHello(3);
// Prints:
// 1: Hello World
// 2: Hello World
// 3: Hello World
Within each execution context is a special object called a scope chain which is used to resolve variables. A scope chain is essentially a stack of currently accessible scopes, from the most immediate context to the global context. (To be a bit more precise, the object at the top of the stack is called an Activation Object which contains references to the local variables for the function being executed, the named function arguments, and two “special” objects: this and arguments.) For example:
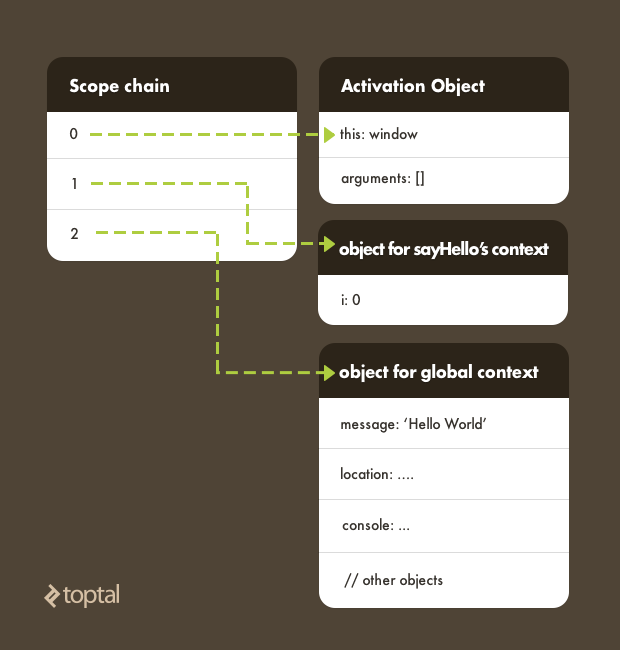
Note in the above diagram how this points to the window object by default and also how the global context contains examples of other objects such as console and location.
When attempting to resolve variables via the scope chain, the immediate context is first checked for a matching variable. If no match is found, the next context object in the scope chain is checked, and so on, until a match is found. If no match is found, a ReferenceError is thrown.
It is important to also note that a new scope is added to the scope chain when a try-catch block or a with block is encountered. In either of these cases, a new object is created and placed at top of the scope chain:
function Person(firstName, lastName) {
this.firstName = firstName;
this.lastName = lastName;
};
function persist(person) {
with (person) {
// The 'person' object was pushed onto the scope chain when we
// entered this "with" block, so we can simply reference
// 'firstName' and 'lastName', rather than person.firstName and
// person.lastName
if (!firstName) {
throw new Error('FirstName is mandatory');
}
if (!lastName) {
throw new Error('LastName is mandatory');
}
}
try {
person.save();
} catch(error) {
// A new scope containing the 'error' object is accessible here
console.log('Impossible to store ' + person + ', Reason: ' + error);
}
}
var p1 = new Person('John', 'Doe');
persist(p1);
To fully understand how scope-based variable lookups occur, it is important to keep in mind that in JavaScript there are currently no block-level scopes. For example:
for (var i = 0; i < 10; i++) {
/* ... */
}
// 'i' is still in scope!
console.log(i); // prints '10'
In most other languages, the code above would lead to an error because the “life” (i.e., scope) of the variable i would be restricted to the for block. In JavaScript, though, this is not the case. Rather, i is added to the activation object at the top of the scope chain and it will stay there until that object is removed from the scope, which happens when the corresponding execution context is removed from the stack. This behavior is known as variable hoisting.
It is worth noting, though, that support for block-level scopes is making its way into JavaScript through the new let keyword. The let keyword is already available in JavaScript 1.7 and is slated to become an officially supported JavaScript keyword as of ECMAScript 6.
JavaScript Performance Ramifications
The way that property and variable lookups, using prototype chain and scope chain respectively, work in JavaScript is one of the language’s key features, yet it is one of the trickiest and most subtle to understand.
The lookup operations we’ve described in this example, whether based on the prototype chain or the scope chain, are repeated every time a property or variable is accessed. When this lookup occurs within loops or other intensive operations, it can have significant JavaScript performance ramifications, especially in light of the single-threaded nature of the language which prevents multiple operations from happening concurrently.
Consider the following example:
var start = new Date().getTime();
function Parent() { this.delta = 10; };
function ChildA(){};
ChildA.prototype = new Parent();
function ChildB(){}
ChildB.prototype = new ChildA();
function ChildC(){}
ChildC.prototype = new ChildB();
function ChildD(){};
ChildD.prototype = new ChildC();
function ChildE(){};
ChildE.prototype = new ChildD();
function nestedFn() {
var child = new ChildE();
var counter = 0;
for(var i = 0; i < 1000; i++) {
for(var j = 0; j < 1000; j++) {
for(var k = 0; k < 1000; k++) {
counter += child.delta;
}
}
}
console.log('Final result: ' + counter);
}
nestedFn();
var end = new Date().getTime();
var diff = end - start;
console.log('Total time: ' + diff + ' milliseconds');
In this example, we have a long inheritance tree and three nested loops. Inside the deepest loop, the counter variable is incremented with the value of delta. But delta is located almost at the top of the inheritance tree! This means that each time child.delta is accessed, the full tree needs to be navigated from bottom to top. This can have a really negative impact on performance.
Understanding this, we can easily improve performance of the above nestedFn function by using a local delta variable to cache the value in child.delta (and thereby avoid the need for repetitive traversal of the entire inheritance tree) as follows:
function nestedFn() {
var child = new ChildE();
var counter = 0;
var delta = child.delta; // cache child.delta value in current scope
for(var i = 0; i < 1000; i++) {
for(var j = 0; j < 1000; j++) {
for(var k = 0; k < 1000; k++) {
counter += delta; // no inheritance tree traversal needed!
}
}
}
console.log('Final result: ' + counter);
}
nestedFn();
var end = new Date().getTime();
var diff = end - start;
console.log('Total time: ' + diff + ' milliseconds');
Of course, this particular technique is only viable in a scenario where it is known that the value of child.delta won’t change while the for loops are executing; otherwise, the local copy would need to be updated with the current value.
OK, let’s run both versions of the nestedFn method and see if there is any appreciable performance difference between the two.
We’ll start by running the first example in a node.js REPL:
diego@alkadia:~$ node test.js
Final result: 10000000000
Total time: 8270 milliseconds
So that takes about 8 seconds to run. That’s a long time.
Now let’s see what happens when we run the optimized version:
diego@alkadia:~$ node test2.js
Final result: 10000000000
Total time: 1143 milliseconds
This time it took just one second. Much faster!
Note that use of local variables to avoid expensive lookups is a technique that can be applied both for property lookup (via the prototype chain) and for variable lookups (via the scope chain).
Moreover, this type of “caching” of values (i.e., in variables in the local scope) can also be beneficial when using some of the most common JavaScript libraries. Take jQuery, for example. jQuery supports the notion of “selectors”, which are basically a mechanism for retrieving one or more matching elements in the DOM. The ease with which one can specify selectors in jQuery can cause one to forget how costly (from a performance standpoint) each selector lookup can be. Accordingly, storing selector lookup results in a local variable can be extremely beneficial to performance. For example:
// this does the DOM search for $('.container') "n" times
for (var i = 0; i < n; i++) {
$('.container').append(“Line “+i+”<br />”);
}
// this accomplishes the same thing...
// but only does the DOM search for $('.container') once,
// although it does still modify the DOM "n" times
var $container = $('.container');
for (var i = 0; i < n; i++) {
$container.append("Line "+i+"<br />");
}
// or even better yet...
// this version only does the DOM search for $('.container') once
// AND only modifies the DOM once
var $html = '';
for (var i = 0; i < n; i++) {
$html += 'Line ' + i + '<br />';
}
$('.container').append($html);
Especially on a web page with a large number of elements, the second approach in the code sample above can potentially result in significantly better performance than the first.
Wrap-up
Data lookup in JavaScript is quite different than it is in most other languages, and it is highly nuanced. It is therefore essential to fully and properly understand these concepts in order to truly master the language. Data lookup and other common JavaScript mistakes should be avoided whenever possible. This understanding is likely to yield cleaner, more robust code that achieves improved JavaScript performance.
Further Reading on the Toptal Blog:
Prague, Czech Republic
Member since March 5, 2014
About the author
Diego has been a senior freelance engineer for the likes of Italian telecom powerhouse Italtel. He also cofounded a web-based CRM business.