Ultimate In-memory Data Collection Manipulation with Supergroup.js
In-memory data collection manipulation is something that we often need to do in data-centric reporting and visualization applications. When needed, we often tend to resort to complex loops, list comprehensions, and other suboptimal means, which can easily end up being a huge mess of hard-to-maintain spaghetti code. Supergroup.js is an in-memory data manipulation library that can be used to solve some common data manipulation challenges on limited datasets.

In-memory data collection manipulation is something that we often need to do in data-centric reporting and visualization applications. When needed, we often tend to resort to complex loops, list comprehensions, and other suboptimal means, which can easily end up being a huge mess of hard-to-maintain spaghetti code. Supergroup.js is an in-memory data manipulation library that can be used to solve some common data manipulation challenges on limited datasets.

Sigfried is a bright and articulate full-stack developer who creates browser-based visual analytics tools.
In-memory manipulation of data often results in a pile of spaghetti code. The manipulation itself might be simple enough: grouping, aggregating, creating hierarchies, and performing calculations; but once the data munging code is written and the results are sent off to the part of the application where they’re needed, related needs continue to arise. A similar transformation of the data may be required in another part of the application, or more details may be needed: metadata, context, parent or child data, etc. In visualization or complex reporting applications particularly, after shoehorning data into some structure for a given need, one realizes that tooltips or synchronized highlights or drilldowns put unexpected pressures on the transformed data. One might address these requirements by:
- Stuffing more details and more levels into the transformed data until it’s huge and ungainly but satisfies the needs of all the nooks and crannies of the application it eventually visits.
- Writing new transformation functions that have to join some already processed node to the global data source to bring in new details.
- Designing complex object classes that somehow know how to handle all the contexts they end up in..
After building data-centric software for 20 or 30 years like I have, one begins to suspect that they are solving the same set of problems over and over again. We bring in complex loops, list comprehensions, database analytical functions, map or groupBy functions, or even full-fledged reporting engines. As our skills develop, we get better at making any chunk of data munging code clever and concise, but spaghetti still seems to proliferate.

In this article, we will take a look at the JavaScript library Supergroup.js - equipped with some powerful in-memory data collection manipulation, grouping and aggregation functions - and how it can help you solve some common manipulation challenges on limited datasets.
The Problem
During my first Toptal engagement, I was convinced from the very first day that the API and data management routines of the codebase I was adding to had been hopelessly over-specified. It was a D3.js application for analyzing marketing data. The application already had an attractive grouped/stacked bar chart visualization and required a choropleth map visualization to be built. The bar chart allowed the user to display 2, 3, or 4 arbitrary dimensions internally called x0, x1, y0, and y1, with x1 and y1 being optional.

In the construction of legends, filters, tooltips, titles, and the calculation of totals or year-to-year differences, x0, x1, y0, and y1 were referred to throughout the code, and ubiquitously throughout the code was conditional logic to handle the presence or absence of optional dimensions.
It could have been worse though. The code might have referred directly to specific underlying data dimensions (e.g., year, budget, tier, product category, etc.) Rather, it was at least generalized to the display dimensions of this grouped/stacked bar chart. But when another chart type became a requirement, one where dimensions of x0, x1, y0, and y1 wouldn’t make sense, a significant portion of the code had to be rewritten entirely - code that deals with legends, filters, tooltips, titles, summary calculations, and chart construction and rendering.
No one wants to tell their client, “I know it’s just my first day here, but before I implement the thing you asked for, can I refactor all the code using a Javascript data manipulation library I wrote myself?” By a stroke of great luck, I was saved from this embarrassment when I was introduced to a client programmer who was just on the verge of refactoring the code anyway. With unusual open-mindedness and grace, the client invited me into the refactoring process through a series of pair programming sessions. He was willing to give Supergroup.js a try, and within minutes we were starting to replace big swaths of gnarly code with pithy little calls to Supergroup.
What we saw in the code was typical of the tangles that arise in dealing with hierarchical or grouped data structures, particularly in D3 applications once they get bigger than demos. These problems arise with reporting applications in general, in CRUD applications that involve filtering or drilling to specific screens or records, in analysis tools, visualization tools, practically any application where enough data is used to require a database.
In-memory Manipulation
Take a Rest API for faceted search and CRUD operations, for instance, you could end up with one or more API calls for getting the set of fields and values (maybe with record counts) for all the search parameters, another API call for getting a specific record, and other calls for getting groups of records for reporting or something. Then all of these are likely to be complicated by the need to impose temporary filters based on user selection or permissions.
If your database is unlikely to exceed tens or hundreds of thousands of records, or if you have easy ways to limit the immediate universe of interest to a dataset of that size, you could probably toss out your entire complicated Rest API (except the permissions part), and have a single call that says “get me all the records”. We’re living in a world with fast compression, fast transfer speeds, plenty of memory at the front end, and speedy Javascript engines. Establishing complex query schemes that have to be understood and maintained by client and server is often unnecessary. People have written libraries to run SQL queries directly on collections of JSON records, because much of the time you don’t need all the optimization of an RDBMS. But even that is overkill. At the risk of sounding insanely grandiose, Supergroup is easier to use and more powerful than SQL most of the time.
Supergroup is basically d3.nest, underscore.groupBy, or underscore.nest on steroids. Under the hood it uses lodash’s groupBy for the grouping operation. The central strategy is to make every piece of original data into metadata, and links to the rest of the tree immediately accessible at every node; and every node or list of nodes is overloaded with a wedding cake of syntactic sugar so that most anything you’d want to know from any place on the tree is available in a short expression.
Supergroup in Action
To demonstrate some syntactic sweetness of Supergroup, I’ve highjacked a copy of Shan Carter’s Mister Nester. A simple two-level nesting using d3.nest looks like:
d3.nest()
.key(function(d) { return d.year; })
.key(function(d) { return d.fips; })
.map(data);
The equivalent with Supergroup would be:
_.supergroup(data,['year','fips']).d3NestMap();
The trailing call there to d3NestMap() just puts the Supergroup output into the same (but not very useful in my opinion) format as d3’s nest.map():
{
"1970": {
"6001": [
{
"fips": "6001",
"totalpop": "1073180",
"pctHispanic": "0.126",
"year": "1970"
}
],
"6003": [
{
"fips": "6003",
"totalpop": "510",
"pctHispanic": "NA",
"year": "1970"
}
],
...
}
}
I say “not very useful” because D3 selections need to be tied to arrays, not maps. What is a “node” in this map data structure? “1970” or “6001”, are just strings and keys into a top or second level map. So, a node would be what the keys point to. “1970” points to a second level map, “6001” points to an array of raw records. This map nesting is readable in the console and okay for looking up values, but for D3 calls you need array data, so you use nest.entries() instead of nest.map():
[
{
"key": "1970",
"values": [
{
"key": "6001",
"values": [
{
"fips": "6001",
"totalpop": "1073180",
"pctHispanic": "0.126",
"year": "1970"
}
]
},
{
"key": "6003",
"values": [
{
"fips": "6003",
"totalpop": "510",
"pctHispanic": "NA",
"year": "1970"
}
]
},
...
]
},
...
]
Now we have nested arrays of key/value pairs: the 1970 node has a key of “1970” and a value consisting of an array of second-level key/value pairs. 6001 is another key/value pair. Its key is also a string identifying it, but the value is an array of raw records. We have to treat these second-to-leaf-level nodes as well as leaf-level nodes differently from nodes higher up the tree. And the nodes themselves contain no evidence that “1970” is a year and “6001” is a fips code, or that 1970 is the parent of this particular 6001 node. I’ll demonstrate how Supergroup solves these problems, but first a look at the immediate return value of a Supergroup call. At first glance it’s just an array of top-level “keys”:
_.supergroup(data,['year','fips']); // [ 1970, 1980, 1990, 2000, 2010 ]
“Ok, that’s nice,” you say. “But where’s the rest of the data?” The strings or numbers in the Supergroup list are actually String or Number objects, overloaded with more properties and methods. For nodes above the leaf level, there’s a children property (“children” is the default name, you could call it something else) holding another Supergroup list of second-level nodes:
_.supergroup(data,['year','fips'])[0].children; // [ 6001, 6003, 6005, 6007, 6009, 6011, ... ]
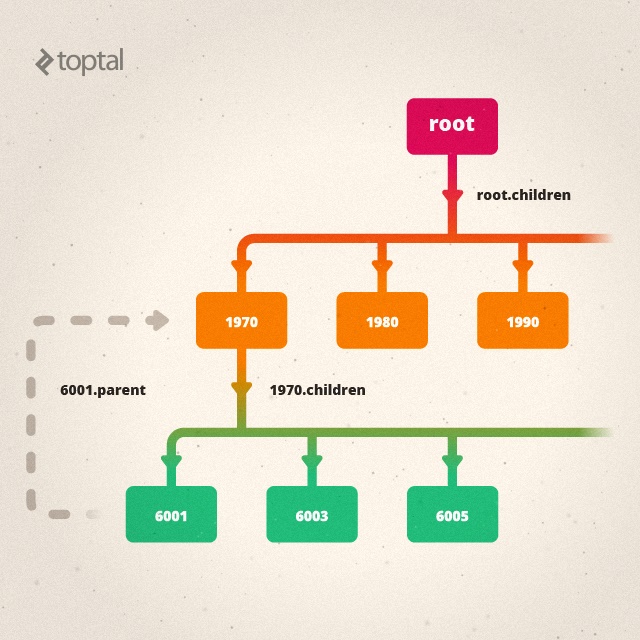
Tooltip Function That Works
In order to demonstrate other features and how this whole thing works, let’s make a simple nested list using D3, and see how we make a useful tooltip function that can work on any node in the list.
d3.select('body')
.selectAll('div.year')
.data(_.supergroup(data,['year','fips']))
.enter()
.append('div').attr('class','year')
.on('mouseover', tooltip)
.selectAll('div.fips')
.data(function(d) { return d.children; })
.enter()
.append('div').attr('class','fips')
.on('mouseover', tooltip);
function tooltip(node) { // comments show values for a second-level node
var typeOfNode = node.dim; // fips
var nodeValue = node.toString(); // 6001
var totalPopulation = node.aggregate(d3.sum, 'totalpop'); // 1073180
var pathToRoot = node.namePath(); // 1970/6001
var fieldPath = node.dimPath(); // year/fips
var rawRecordCount = node.records.length;
var parentPop = node.parent.aggregate(d3.sum, 'totalpop');
var percentOfGroup = 100 * totalPopulation / parentPop;
var percentOfAll = 100 * totalPopulation / node.path()[0].aggregate(d3.sum,'totalPop');
...
};
This tooltip function will work for almost any node at any depth. Since nodes at the top level do not have parents, we can do this to workaround it:
var byYearFips = _.supergroup(data,['year','fips']);
var root = byYearFips.asRootVal();
Now we have a root node that is parent to all the Year nodes. We don’t have to do anything with it, but now our tooltip will work because node.parent has something to point to. And node.path()[0] which was supposed to point to a node that represents the entire dataset actually does.
In case it wasn’t obvious from the examples above, namePath, dimPath, and path give a path from the root to the current node:
var byYearFips = _.supergroup(data,['year','fips']);
// BTW, you can give a delimiter string to namePath or dimPath otherwise it defaults to '/':
byYearFips[0].children[0].namePath(' --> '); // ==> "1970 --> 6001"
byYearFips[0].children[0].dimPath(); // ==> "year/fips"
byYearFips[0].children[0].path(); // ==> [1970,6001]
// after calling asRootVal, paths go up one more level:
var root = byYearFips.asRootVal('Population by Year/Fips'); // you can give the root node a name or it defaults to 'Root'
byYearFips[0].children[0].namePath(' --> '); // ==> undefined
byYearFips[0].children[0].dimPath(); // ==> "root/year/fips"
byYearFips[0].children[0].path(); // ==> ["Population by Year/Fips",1970,6001]
// from any node, .path()[0] will point to the root:
byYearFips[0].children[0].path()[0] === root; // ==> true
Aggregate In-place When You Need To
The tooltip code above also used the “aggregate” method. “aggregate” is called upon a single node, and it takes two parameters:
- An aggregating function that expects an array (usually of numbers).
- Either a field name of the field to be plucked from the records grouped under that node or a function to be applied to each of those records.
There is also an “aggregates” convenience method on lists (the top-level list of groups, or the child groups of any node). It can return a list or a map.
_.supergroup(data,'year').aggregates(d3.sum,'totalpop');
// ==> [19957304,23667902,29760021,33871648,37253956]
_.supergroup(data,'year').aggregates(d3.sum,'totalpop','dict');
// ==> {"1970":19957304,"1980":23667902,"1990":29760021,"2000":33871648,"2010":37253956}
Arrays That Act like Maps
With d3.nest we tend to use .entries() rather than .map(), as I said earlier, because “maps” don’t let you use all the D3 (or Underscore) functionality that depends on arrays. But when you use .entries() to generate arrays, you can’t do a simple lookup by key value. Of course, Supergroup provides the syntactic sugar you want so you don’t have to trudge through a whole array every time you want a single value:
_.supergroup(data,['year','fips']).lookup(1980); // ==> 1980
_.supergroup(data,['year','fips']).lookup([1980,6011]).namePath(); // ==> "1980/6011"
Comparing Nodes Across Time
A .previous() method on nodes lets you access the previous node in a Supergroup list. You can use .sort(
_.chain(data)
.supergroup(['fips','year'])
.map(function(fips) {
return [fips,
_.chain(fips.children.slice(1))
.map(function(year) {
return [year,
year.aggregate(d3.sum,'totalpop') + ' (' +
Math.round(
(year.aggregate(d3.sum, 'totalpop') /
year.previous().aggregate(d3.sum,'totalpop')
- 1) * 100) +
'% change from ' + year.previous() + ')'
];
}).object().value() ]
}).object().value();
==> {
"6001": {
"1980": "1105379 (3% change from 1970)",
"1990": "1279182 (16% change from 1980)",
"2000": "1443741 (13% change from 1990)",
"2010": "1510271 (5% change from 2000)"
},
"6003": {
"1980": "1097 (115% change from 1970)",
"1990": "1113 (1% change from 1980)",
"2000": "1208 (9% change from 1990)",
"2010": "1175 (-3% change from 2000)"
},
...
}
Tabular Data to D3.js Hierarchy Layouts
Supergroup does a good deal more than what I’ve shown here so far. For D3 visualizations based on d3.layout.hierarchy, example code on the D3 gallery generally starts with the data in a tree format (this Treemap example for instance). Supergroup lets you easily get tabular data ready for d3.layout.hierarchy visualizations (example). All you need is the root node returned by .asRootVal(), and then to run root.addRecordsAsChildrenToLeafNodes(). d3.layout.hierarchy expects the bottom level of child nodes to be an array of raw records. addRecordsAsChildrenToLeafNodes takes leaf nodes of a Supergroup tree and copies the .records array to a .children property. It’s not the way Supergroup usually likes things, but it will work fine for Treemaps, Clusters, Partitions, etc. (d3.layout.hierarchy docs).
Like the d3.layout.hierarchy.nodes method that returns all the nodes in a tree as a single array, Supergroup provides .descendants() to get all the nodes starting from some specific node, .flattenTree() to get all the nodes starting from a regular Supergroup list, and .leafNodes() to get just an array of the leaf nodes.
Grouping and Aggregating by Multi-Valued Fields
Without going into exhaustive detail, I’ll mention that Supergroup has some features for handling situations that occur less commonly but commonly enough to merit special treatment.
Sometimes you want to group by a field that can have more than one value. In relational or tabular, multivalued fields shouldn’t generally occur (they break first normal form), but they can be useful. Here’s how Supergroup handles such a case:
var bloggers = [
{ name:"Ridwan", profession:["Programmer"], articlesPublished:73 },
{ name:"Sigfried", profession:["Programmer","Spiritualist"], articlesPublished:2 },
];
// the regular way
_.supergroup(bloggers, 'profession').aggregates(_.sum, 'articlesPublished','dict');
// ==> {"Programmer":73,"Programmer,Spiritualist":2}
// with multiValuedGroups
_.supergroup(bloggers, 'profession',{multiValuedGroups:true}).aggregates(_.sum, 'articlesPublished','dict');
// ==> {"Programmer":75,"Spiritualist":2}
As you can see, with multiValuedGroup, the sum of all the articlesPublished in the group list is higher than the actual total number of articlesPublished because the Sigfried record is counted twice. Sometimes this is the desired behavior.
Turning Hierarchical Tables Into Trees
Another thing that can come up occasionally is a tabular structure that represents a tree through explicit parent/child relationships between records. Here’s an example of a tiny taxonomy:
| p | c |
|---|---|
| animal | mammal |
| animal | reptile |
| animal | fish |
| animal | bird |
| plant | tree |
| plant | grass |
| tree | oak |
| tree | maple |
| oak | pin oak |
| mammal | primate |
| mammal | bovine |
| bovine | cow |
| bovine | ox |
| primate | monkey |
| primate | ape |
| ape | chimpanzee |
| ape | gorilla |
| ape | me |
tree = _.hierarchicalTableToTree(taxonomy, 'p', 'c'); // top-level nodes ==> ["animal","plant"]
_.invoke(tree.flattenTree(), 'namePath'); // call namePath on every node ==>
["animal",
"animal/mammal",
"animal/mammal/primate",
"animal/mammal/primate/monkey",
"animal/mammal/primate/ape",
"animal/mammal/primate/ape/chimpanzee",
"animal/mammal/primate/ape/gorilla",
"animal/mammal/primate/ape/me",
"animal/mammal/bovine",
"animal/mammal/bovine/cow",
"animal/mammal/bovine/ox",
"animal/reptile",
"animal/fish",
"animal/bird",
"plant",
"plant/tree",
"plant/tree/oak",
"plant/tree/oak/pin oak",
"plant/tree/maple",
"plant/grass"]
Conclusion
So, there we have it. I’ve been using Supergroup on every Javascript project I’ve worked on for the last three years. I know it solves a lot of problems that come up constantly in data-centric programming. The API and implementation are not at all perfect, and I’d be delighted to find collaborators interested in working on it with me.
After a couple days of refactoring on that client project, I got a message from Dave, the programmer I was working with:
Dave: I must say Im a pretty big fan of supergroups. It’s cleaning up a ton.
Sigfried: Yay. I’m going to ask for a testimonial at some point :).
Dave: Hah absolutely.
If you give it a spin and any questions or issues arise, drop a line in the comments section or post an issue on the GitHub repository.
About the author
Sigfried is a bright and articulate full-stack developer who creates browser-based visual analytics tools.