挑战网络审查:我是如何建立一个网站收集被审核微博的
众所周知,中国政府实施着世界上最严格的网络审查。互联网上的内容,几乎一切都在政府的审查和监视之下。为了符合和服从政府的网络审查,网络服务提供商以及网络内容提供商都有自己的内容过滤系统,这些系统会依据网络审查的制度和规定屏蔽或删除网络用户发布的内容,在某些情况下甚至会直接删除网络用户。

众所周知,中国政府实施着世界上最严格的网络审查。互联网上的内容,几乎一切都在政府的审查和监视之下。为了符合和服从政府的网络审查,网络服务提供商以及网络内容提供商都有自己的内容过滤系统,这些系统会依据网络审查的制度和规定屏蔽或删除网络用户发布的内容,在某些情况下甚至会直接删除网络用户。

Xiaolei is a JavaScript expert focusing on Node.js and AngularJS. He highly values building trust with colleagues and clients.
Expertise
PREVIOUSLY AT

众所周知,中国政府实施着世界上最严格的网络审查。这个审查系统,也有个臭名昭著的别名-防火长城,其雏型是金盾工程,从2003年建成后就在公安部的管理下运行。
一些国际知名新闻网站如纽约时报等因经常刊载政治敏感内容而被封锁。那些不遵循和服从中国网络审查的知名社交网站如脸谱和推特等也会遭到屏蔽。普通的中国因特网用户无法直接访问这些网站。在技术层面上,这个系统实施封锁和屏蔽的方式是多样而复杂的。
对于中国境内的网站,几乎所有一切都在政府的审查和监视之下。为了符合和服从政府的网络审查规定,网络服务提供商以及网络内容提供商都有自己的内容过滤系统,这些系统会依据网络审查的制度和规定屏蔽或删除网络用户发布的内容,在某些情况下甚至会直接删除网络用户。这些大型网络公司的服务器上都部署着审查软件,并且在公司内部有专门的团队或部门负责网络审查事务。这些团队和组织与公安部的地方部门进行合作,接受新的命令和政策。
对我们国内的开发人员而言,网络审查不仅限制了言论自由,还屏蔽了世界上很多有价值的网络资源。在我平时的工作中,我必须连接VPN(虚拟专用网络)才能使用Gmail,Dropbox等很多与工作相关的服务。到现在,我依然记得2010年的事情,当时谷歌公司因为拒绝继续服从遵循中国政府的网络审查而导致谷歌所有的服务在中国被屏蔽。这种事情在世界上大多数其他国家是不可想象的。
新浪微博的网络审查
新浪微博是中国国内最大的微博网站。因为推特已经被屏蔽,它在国内几乎没有竞争对手。比起传统的媒体,新闻和消息在微博上扩散的更及时迅速。像我这样的年轻一代人都喜欢用微博获取信息、讨论公共事件。但是,在网络审查制度下,很多热门有趣的微博发布后都会遭到屏蔽或删除。政治或公共事件相关的微博最有可能被删除,而娱乐相关的则最安全。计算机科学家Jed Crandall和Dan Wallach在2013的一项研究发现每天大约有12%的微博被屏蔽或删除。
像每年六四这样的发生过政治事件的日子,一天有很多微博被删除,微博用户甚至都无法输入一些敏感的词汇。一个微博被审查屏蔽或删除后,是什么样子的?当你刷新微博时,你会发现这样无法查看的微博:
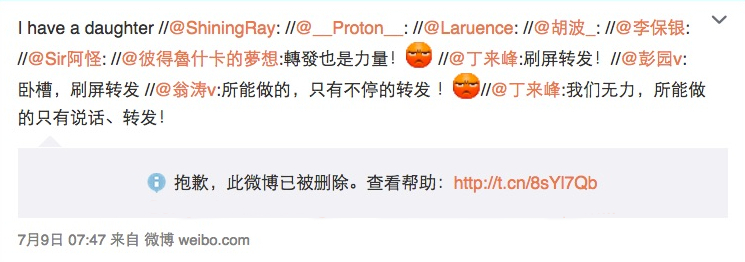
上面是一张转发的微博截图。灰色方框里面的微博原始内容已被删除,替换成了提示语“对不起,微博已被删除,请查看。。。”。这个原始微博的内容是2013年一个母亲为其被绑架、强奸和被迫卖淫的11岁女儿申述公正的事情。
2013年,在微博上爆料了很多与政治和官员有关的丑闻。新浪微博的影响力也迅速扩大。而于此同时,政府也开始紧张起来,并开始加强在微博上的内容审查。
在微博出现之前,像我这样对政治感兴趣的年轻人会借助代理服务器或隧道技术从国外网站获取敏感的政治新闻。现在,我们有了这样一个相对开放的平台,政府又迅速介入加强审查,使得微博就像昙花一现,很快就恢复了平静。这让我很愤慨。跟朋友聊起此事,大家都对此很气愤。”为什么我们不能做些什么呢?“朋友们说。于是我决定尝试下,看看到底是哪些微博内容被屏蔽或删除了。
技术细节
原则上,我需要搭建一个服务器来不停的获取屏蔽或删除的微博,并且以网站的方式显示这些内容。我原本打算用国内的云服务如阿里云,但是当时在这个云平台上有很多限制,如域名重定向的配置就很麻烦,并且他们的收费也不低。另外,我还担心服务器在国内的安全性问题,于是我最后在Linode上买了一个服务器,并且买下了域名freeweibo.me。
下面是整个系统架构的例图:Mongo数据库,Web服务程序以及爬虫程序。我选择了Node.js作为开发环境,因为它的效率和可扩展性,同时我自己也对此更有经验。Web服务器用Express.js框架开发,使用了微博API接口。最开始,我打算把爬虫程序作为一个独立的进程运行,但之后我发现把它作为一个模块整合到Web服务进程上已经足够了。
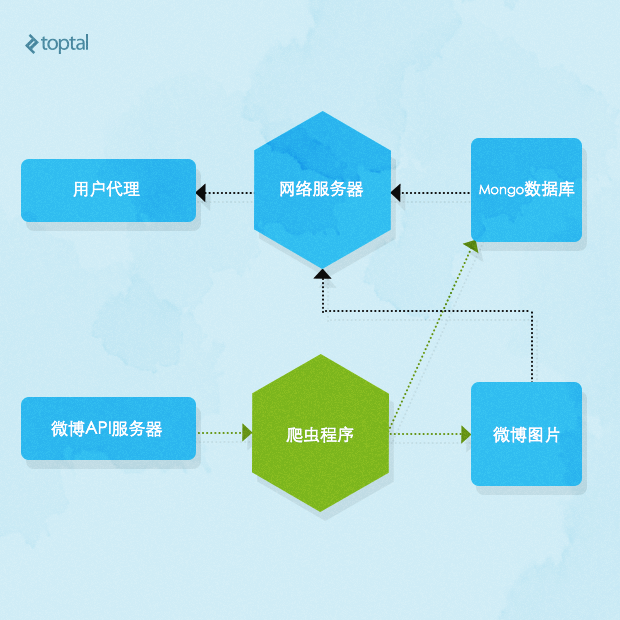
一个微博的内容主要分为两个部分。一是内容文本和相关的属性如时间等,二是微博附带的图片。这些附带的图片非常重要。在中国,用图片的形式发表文字内容非常流行,因为图片难以被网络服务器上基于文本的过滤和审查软件解析审查。
爬虫程序的主要算法是从已知的用户组中获取他们新的微博,并且在稍后检查这些微博是否被屏蔽了。一个微博可能在从5分钟到几天的时间内被审查屏蔽或删除。这样爬虫程序主要有两个任务:一是获取任务,不停的获取新的微博,二是检测任务,检测哪些微博被审查了。
一开始,我把爬虫程序配置成从微博平台上最有名的前100个微博用户那里获取微博。但是,结果是每天几乎没有检测到任何被审查的微博。分析后,我发现原因是这些用户对政治敏感或公共社会话题没有兴趣,他们很少发布或转发这类被屏蔽概率高的微博。例如,这个用户,她是一个女演员,拥有多达1000万个粉丝,但她从不发表内容敏感的微博。
在经过一番试验和思考后,我找到了一个可以自动发现经常发表被审核微博用户的方法。社交网络是主题相关联的,用户倾向于兴趣聚集。如果一个用户对公共或政治话题感兴趣,那么他就很有可能发布或转发其他有类似兴趣用户的微博。通过这些转发的微博,就可以找到新的用户。
例如,用户A已在数据库的用户表中,爬虫程序检测到了一个被审核的微博,这个微博为用户A所转发。这个微博的原作者用户B是个新用户,不在数据库的用户表里,这时程序就会将用户B加入数据库。下次当爬虫程序重新开始抓取用户的微博时,用户B的微博也会被抓取到。这样,数据库用户数和微博数就会自动增长。
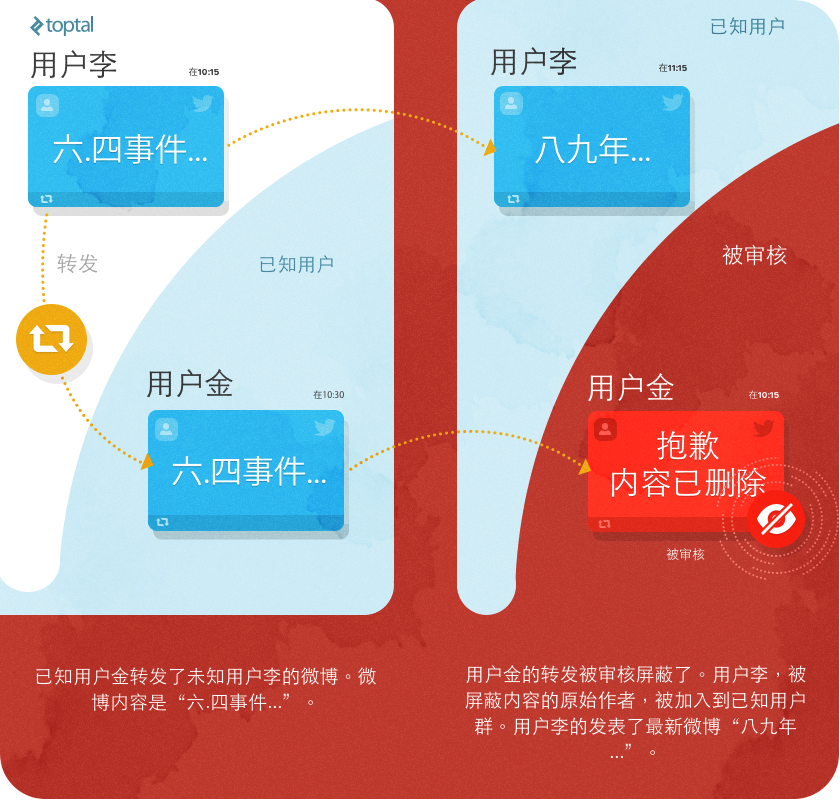
在利用上面的方法调整爬虫程序的算法后,我只在数据库中配置了几个初始的关键用户,这些用户对内容敏感的微博有着强烈兴趣。这样,每天检测到的被审查微博数开始稳步增长。下面是一个我邮箱归档的被审查微博的截图:

波折与结果
在经过两周的编程和调试后,我把系统部署到了freeweibo.me上。但是,几个星期后,系统就没有检测到新的被审查微博了。我调查后发现有两个原因。一是微博平台更新了他们的API接口,二是由于用户数和微博数的增加,爬虫程序的API访问请求超过了阈值(1000次每分钟)。于是我又修改接口,并且控制了API访问的频率。之后,爬虫程序就稳定了。
在是否让更多的人知道这个网站的问题上,我面临着很尴尬的境地。我自己很清楚,如果访问网站的人越多,它就会越快地被政府审查发现和屏蔽。所以,我只把这个网站告诉了一些朋友。最开始,一天只有10到20次访问。但几个月之后,每天就有八十甚至更多的访问量了,并且还有十多个邮件订阅用户。
后来,正如我已经料到的,有天早上我发现网站被屏蔽了。用户必须使用VPN服务才能翻墙访问。而绝大多数因特网用户都没有VPN。这时它已经运行大概三个多月了。
然而,就在同一天,我惊喜的发现有个网站freeweibo.com做的是跟我类似的东西,并且它的内容更丰富。这个网站的项目资源很庞大,在社交网站上很活跃,提供不同的内容服务,如RSS,邮件订阅和国内镜像站点等。它甚至还有手机应用。我不清楚谁做的这个项目,但是我很高兴他们和我有相同的理念。
基于当时的情况,我的网站很明显已经没有多大的意义了。几个月后,我就关闭了这个网站。
尽管结果如此,但是我并不觉得这是徒劳的。恰好相反,这是很刻骨铭心的经历,虽然网站只运行了几个月。它帮助我更深刻地认识到了我们国家的现实。
在中国,要经营互联网业务,你必须对网络审查十分谨慎,不然迟早会惹上麻烦。在这里,经营互联网业务,如果不服从网络审查,并且牺牲用户的隐私,基本上没有成功之路。
更新
freeweibo.me的代码现已开源到Github这里 再次声明,该源代码跟另一个网站freeweibo.com没有任何关系。
Xiaolei Liu
Nanjing, Jiangsu, China
Member since July 28, 2014
About the author
Xiaolei is a JavaScript expert focusing on Node.js and AngularJS. He highly values building trust with colleagues and clients.
Expertise
PREVIOUSLY AT