
The Definitive Guide to NoSQL Databases
Limited SQL scalability has prompted industry leaders like Google and Amazon to develop NoSQL database management systems that optimize for performance, reliability, and consistency. In this article, Senior Software Engineer Mohammad Altarade explores some of the most popular NoSQL database options on the market and explains why this paradigm for storing and retrieving data will be with us for years to come.

Limited SQL scalability has prompted industry leaders like Google and Amazon to develop NoSQL database management systems that optimize for performance, reliability, and consistency. In this article, Senior Software Engineer Mohammad Altarade explores some of the most popular NoSQL database options on the market and explains why this paradigm for storing and retrieving data will be with us for years to come.

Mohammad Altarade
Mohammad is an engineer and data scientist working at the intersection of software and hardware. As a senior .NET engineer at ProGineer Technologies, he wrote complex SQL queries to retrieve big data, and developed statistical analysis and interactive visualization reports. He has extensive experience with yield management systems and fault detection and classification in semiconductor manufacturing.
Previously At

There is no doubt that the way web applications deal with data has changed significantly over the past decade. More data is being collected and more users are accessing this data concurrently than ever before. This means that scalability and performance are more of a challenge than ever for relational databases that are schema-based and therefore can be harder to scale.
The Evolution of NoSQL
The SQL scalability issue was recognized by Web 2.0 companies with huge, growing data and infrastructure needs, such as Google, Amazon, and Facebook. They came up with their own solutions to the problem—technologies like BigTable, DynamoDB, and Cassandra.
This growing interest resulted in a number of NoSQL Database Management Systems (DBMS), with a focus on performance, reliability, and consistency. A number of existing indexing structures were reused and improved upon with the purpose of enhancing search and read performance.
First, there were proprietary (closed source) types of NoSQL databases developed by big companies to meet their specific needs, such as Google’s BigTable and Amazon’s DynamoDB. The success of these proprietary systems initiated development of a number of similar open-source and proprietary database systems, the most widely used being MongoDB, Cassandra, DynamoDB, Redis, and HBase.
What Makes NoSQL Different?
One key difference between NoSQL databases and traditional relational databases is the fact that NoSQL is a form of unstructured storage. This means that NoSQL databases do not have a fixed table structure like the ones found in relational databases.
Advantages and Disadvantages of NoSQL Databases
Advantages
NoSQL databases have many advantages compared to traditional, relational databases. One major, underlying difference is that NoSQL databases have a simple and flexible structure. They are schema-free. Unlike relational databases, NoSQL databases are based on key-value pairs. Some store types of NoSQL databases include column store, document store, key-value store, graph store, object store, XML store, and other data store modes. Usually, each value in the database has a key. Some NoSQL database stores also allow developers to store serialized objects into the database, not just simple string values.
Additionally, open-source NoSQL databases don’t require expensive licensing fees and can run on inexpensive hardware, rendering their deployment cost-effective. When working with NoSQL databases, whether they are open-source or proprietary, expansion is easier and cheaper than when working with relational databases. This is because it’s done by horizontally scaling and distributing the load on all nodes, rather than the type of vertical scaling that is usually done with relational database systems, which is replacing the main host with a more powerful one.
Disadvantages
Of course, NoSQL databases are not perfect, and they are not always the right choice. One challenge is that NoSQL systems often rely on proprietary interfaces and database-specific methods for storing and accessing data rather than standard SQL. While this flexibility can be beneficial, it may add complexity and require additional development effort. It can also make it more difficult to move applications between database systems, as tools and queries designed for one platform may not work with another.
NoSQL vs. Relational Databases
This table provides a brief feature comparison between NoSQL and relational databases:
| Feature | NoSQL Databases | Relational Databases |
|---|---|---|
| Performance | High for large-scale, unstructured data | High for structured, complex queries |
| Reliability | Varies by implementation | Good |
| Availability | Good | Good |
| Consistency | Varies by implementation | Strong for single-node, but varies in distributed deployments |
| Data Storage | Optimized for huge, unstructured data | Best for structured, medium-to-large datasets |
| Scalability | High via horizontal scaling | High via vertical scaling, though horizontal scaling is costly |
It should be noted that the table shows a comparison on the database level, not the various database management systems that implement both models. These systems provide their own proprietary techniques to overcome some of the problems and shortcomings in both systems, and in some cases, significantly improve performance and reliability.
NoSQL Data Store Types
Key-Value Store
In the key-value store type, a hash table is used in which a unique key points to an item. Keys can be organized into logical groups of keys, only requiring keys to be unique within their own group. This allows for identical keys in different logical groups. The following table shows an example of a key-value store, in which the key is the name of the city, and the value is the address for Ulster University in that city.
| Key | Value |
|---|---|
| "Belfast" | {“University of Ulster, Belfast campus, York Street, Belfast, BT15 1ED”} |
| “Coleraine" | {“University of Ulster, Coleraine campus, Cromore Road, Co. Londonderry, BT52 1SA”} |
Some implementations of the key-value store provide caching mechanisms, which greatly enhance their performance. All that is needed to deal with the items stored in the database is the key. Data is stored in a form of a string, JSON, or BLOB (Binary Large OBject).
One challenge with this form of database is maintaining consistency across distributed environments. Different database systems approach this problem in different ways, depending on their design goals and requirements.
Some of the most widely used key-value databases include Redis and Amazon DynamoDB.
Document Store
Document stores are similar to key-value stores in that they are schema-less and based on a key-value model. Both, therefore, share many of the same advantages and disadvantages. There are, however, key differences between the two. In document stores, the values (documents) provide encoding for the data stored. Those encodings can be XML, JSON, or BSON (Binary encoded JSON). Also, querying based on data can be done.
The most popular database application that relies on a document store is MongoDB.
Column Store
In a column store database, data is stored in columns, as opposed to being stored in rows as is done in most relational database management systems. A column store is comprised of one or more Column Families that logically group certain columns in the database. A key is used to identify and point to a number of columns in the database, with a keyspace attribute that defines the scope of this key. Each column contains tuples of names and values, ordered and comma separated.
Column stores have fast read/write access to the data stored. In a column store, rows that correspond to a single column are stored as a single disk entry. This makes for faster access during read/write operations.
The most popular databases that use the column store include Google’s BigTable, HBase, Cassandra, and ScyllaDB.
Graph Base
In a Graph Base NoSQL Database, a directed graph structure is used to represent the data. The graph is comprised of edges and nodes. Formally, a graph is a representation of a set of objects, where some pairs of the objects are connected by links. The interconnected objects are represented by mathematical abstractions, called vertices, and the links that connect some pairs of vertices are called edges. A set of vertices and the edges that connect them is said to be a graph.
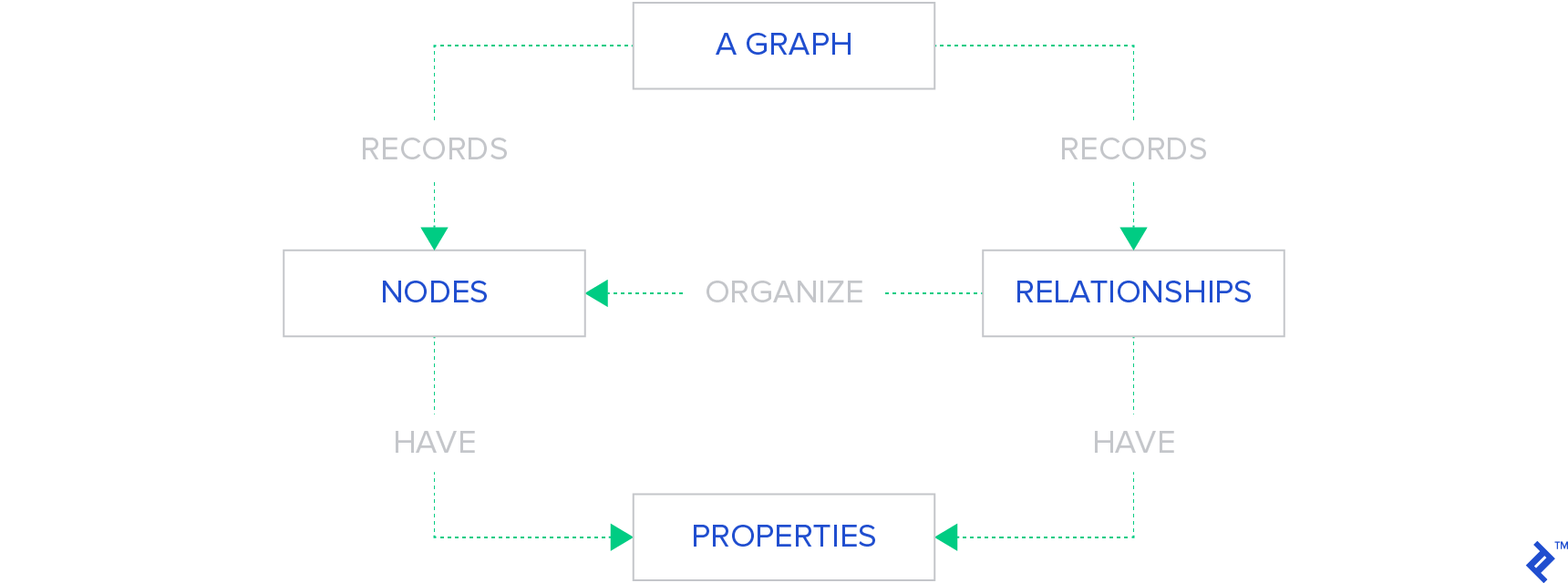
This illustrates the structure of a graph base database that uses edges and nodes to represent and store data. These nodes are organized by some relationships with one another, which is represented by edges between the nodes. Both the nodes and the relationships have some defined properties.
Graph databases were originally used most often in social networking applications, but they are now also common in recommendation engines, fraud detection systems, knowledge graphs, and other applications that rely on complex relationships between data. Graph databases allow developers to focus more on relationships between objects rather than on the objects themselves. In this context, they indeed allow for a scalable and easy-to-use environment.
Currently, Neo4j is one of the most widely adopted graph databases. Other popular graph database platforms include Amazon Neptune and TigerGraph.
NoSQL Database Management Systems
For a brief comparison of the databases, the following table provides a brief comparison between different NoSQL database management systems.
| Storage Type | Query Method | Interface | Programming Language | Open Source | Replication | |
|---|---|---|---|---|---|---|
| Cassandra | Column Store | CQL | Native Protocol | Java | Yes | Configurable |
| MongoDB | Document Store | Mongo Query | TCP/IP | C++ | Yes | Async |
| ScyllaDB | Column Store | CQL | Native Protocol | C++ | Yes | Configurable |
| CouchDB | Document Store | Mango Query | REST | Erlang | Yes | Async |
| BigTable | Column Store | API | TCP/IP | C++ | No | Async |
| HBase | Column Store | API | REST | Java | Yes | Async |
MongoDB has a flexible schema storage, which means stored objects are not necessarily required to have the same structure or fields. MongoDB also has some optimization features, which distributes the data collections across, resulting in overall performance improvement and a more balanced system.
Other NoSQL database systems, such as Apache CouchDB, are also document store databases and share many features with MongoDB. One notable difference is that CouchDB provides a RESTful API for interacting with the database.
REST is an architectural style consisting of a coordinated set of architectural constraints applied to components, connectors, and data elements, within the World Wide Web. It relies on a stateless, client-server, cacheable communications protocol (e.g., the HTTP protocol). RESTful applications use HTTP requests to post, read data, and delete data.
One of the most widely used NoSQL databases is Cassandra, a column store database that includes a lot of features aimed at reliability and fault tolerance.
Rather than providing an in-depth look at each NoSQL DBMS, Cassandra and MongoDB, two of the most widely used NoSQL database management systems, will be explored in the next subsections.
Cassandra
Cassandra is a database management system designed to have no single point of failure and to provide maximum availability.
Cassandra is mostly a column store database. Some studies referred to Cassandra as a hybrid system, inspired by Google’s BigTable, which is a column store database, and Amazon’s DynamoDB, which is a key-value database. This is achieved by providing a key-value system, but the keys in Cassandra point to a set of column families, with reliance on Google’s BigTable distributed file system and Dynamo’s availability features (distributed hash table).
Cassandra is designed to store huge amounts of data distributed across different nodes. Cassandra is a DBMS designed to handle massive amounts of data, spread out across many servers, while providing a highly available service with no single point of failure, which is essential for large-scale web services.
The main features of Cassandra include:
- No single point of failure. For this to be achieved, Cassandra must run on a cluster of nodes, rather than a single machine. That doesn’t mean that the data on each cluster is the same, but the management software is. When a failure in one of the nodes happens, the data on that node will be inaccessible. However, other nodes (and data) will still be accessible.
- Distributed Hashing is a scheme that provides hash table functionality in a way that the addition or removal of one slot does not significantly change the mapping of keys to slots. This provides the ability to distribute the load to servers or nodes according to their capacity, and in turn, minimize downtime.
- Relatively easy to use Client Interface. Cassandra uses Cassandra Query Language (CQL) for its client interface. CQL is a SQL-like query language that simplifies querying and managing data.
- Other availability features. One of Cassandra’s features is data replication. Basically, it mirrors data to other nodes in the cluster. Replication can be random, or specific to maximize data protection by placing in a node in a different data center, for example. Another feature found in Cassandra is the partitioning policy. The partitioning policy decides where on which node to place the key. This can also be random or in order. When using both types of partitioning policies, Cassandra can strike a balance between load balancing and query performance optimization.
- Consistency. Features like replication make consistency challenging. Cassandra addresses this by allowing developers to choose different consistency levels for read and write operations. This gives developers more control over how data is replicated and retrieved across the cluster.
- Read/Write Actions. The client sends a request to a single Cassandra node. The node, according to the replication policy, stores the data to the cluster. Each node first performs the data change in the commit log, and then updates the table structure with the change, both done synchronously. The read operation is also very similar, a read request is sent to a single node, and that single node is the one that determines which node holds the data, according to the partitioning/placement policy.
MongoDB
MongoDB is a schema-free, document-oriented database written in C++. The database is document store based, which means it stores values (referred to as documents) in the form of encoded data. The choice of encoded format in MongoDB is JSON. This is powerful, because even if the data is nested inside JSON documents, it will still be queryable and indexable.
The subsections that follow describe some of the key features available in MongoDB.
Shards
Sharding is the partitioning and distributing of data across multiple machines (nodes). A shard is a collection of MongoDB nodes, in contrast to Cassandra where nodes are symmetrically distributed. Using shards also means the ability to horizontally scale across multiple nodes. In the case that there is an application using a single database server, it can be converted to sharded cluster with very few changes to the original application code because the way sharding is done by MongoDB software is almost completely decoupled from the public APIs exposed to the client side.
Mongo Query Language
MongoDB uses a document-based query language. To retrieve certain documents from a collection, a query document is created containing the fields that the desired documents should match.
Actions
In MongoDB, there is a group of servers called routers. Each one acts as a server for one or more clients. Similarly, the cluster contains a group of servers called configuration servers. Each one holds a copy of the metadata indicating which shard contains what data. Read or write actions are sent from the clients to one of the router servers in the cluster, and are automatically routed by that server to the appropriate shards that contain the data with the help of the configuration servers.
Similar to Cassandra, a shard in MongoDB uses replication to improve availability and fault tolerance. Data is typically replicated through Replica Sets, in which one node acts as the primary node and the remaining nodes act as secondary replicas. Write operations are directed to the primary node and then replicated to the secondary nodes, helping ensure data availability in the event of node failures.
In the graphic below, we see the MongoDB architecture explained above, showing the router servers in green, the configuration servers in blue, and the shards that contain the MongoDB nodes.
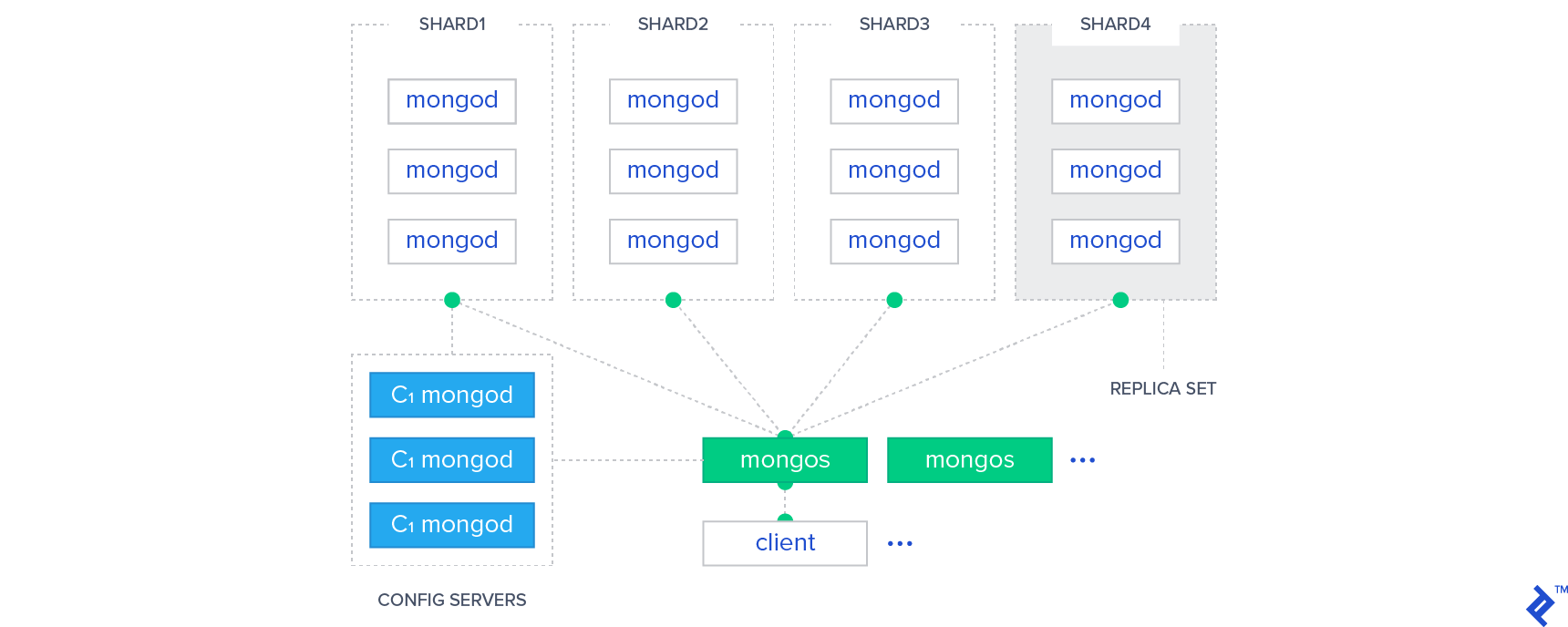
It should be noted that sharding (or sharing the data between shards) in MongoDB is completely automatic, which reduces the failure rate and makes MongoDB a highly scalable database management system.
Indexing Structures for NoSQL Databases
Indexing is the process of associating a key with the location of a corresponding data record in a DBMS. There are many indexing data structures used in NoSQL databases. The following sections will briefly discuss some of the more common indexing methods used in database systems, including LSM-tree, B-Tree, T-Tree, and O2-Tree indexing.
LSM-Tree Indexing
Log-structured merge trees (LSM trees) are among the most widely used indexing and storage structures in modern NoSQL databases. Rather than updating records directly on disk, LSM trees buffer writes in memory and periodically merge them into persistent storage. This design improves write performance and scalability, making LSM trees particularly well-suited to large distributed systems. Databases such as Cassandra, ScyllaDB, RocksDB, and LevelDB rely on LSM-tree architectures.
B-Tree Indexing
B-Tree is one of the most common index structures in a DBMS. In B-trees, internal nodes can have a variable number of child nodes within some predefined range.
One major difference from other tree structures, such as AVL, is that B-Tree allows nodes to have a variable number of child nodes, meaning less tree balancing but more wasted space.
The B+-Tree is one of the most popular variants of B-Trees. The B+-Tree is an improvement over B-Tree that requires all keys to reside in the leaves.
T-Tree Indexing
The data structure of T-Trees was designed by combining features from AVL-Trees and B-Trees. AVL-Trees are a type of self-balancing binary search trees, while B-Trees are unbalanced, and each node can have a different number of children.
In a T-Tree, the structure is very similar to the AVL-Tree and the B-Tree. Each node stores more than one {key-value, pointer} tuple. Also, binary search is utilized in combination with the multiple-tuple nodes to produce better storage and performance. A T-Tree has three types of nodes: A T-Node that has a right and left child, a leaf node with no children, and a half-leaf node with only one child.
It is believed that T-Trees have better overall performance than AVL-Trees.
O2-Tree Indexing
While LSM-trees and B-tree variants are widely used in production database systems, researchers continue to explore alternative indexing structures designed to improve performance under specific workloads. The O2-Tree is one such research structure that has shown promising results in benchmark testing. O2-Tree is basically an improvement over Red-Black trees, a form of a Binary-Search tree, in which the leaf nodes contain the {key value, pointer} tuples.
O2-Tree was proposed to enhance the performance of current indexing methods. An O2-Tree of order m (m ≥ 2), where m is the minimum degree of the tree, satisfies the following properties:
- Every node is either red or black. The root is black.
- Every leaf node is colored black and consists of a block or page that holds “key value, record-pointer” pairs.
- If a node is red, then both its children are black.
- For each internal node, all simple paths from the node to descendant leaf-nodes contain the same number of black nodes. Each internal node holds a single key value.
- Leaf-nodes are blocks that have between ⌈m/2⌉ and m “key-value, record-pointer” pairs.
- If a tree has a single node, then it must be a leaf, which is the root of the tree, and it can have between 1 to m key data items.
- Leaf nodes are double-linked in forward and backward directions.
Here, we see a straightforward performance comparison between O2-Tree, T-Tree, B+-Tree, AVL-Tree, and Red-Black Tree:
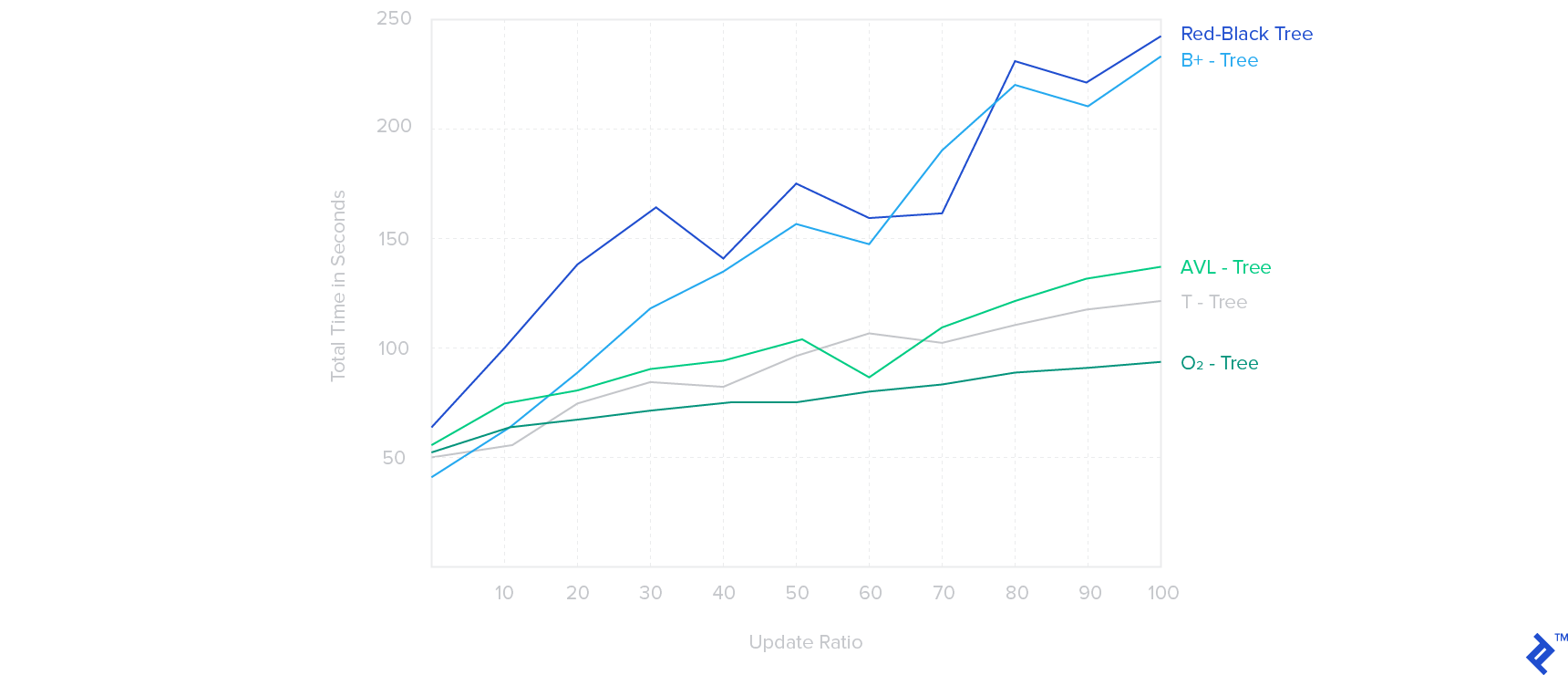
The order of the T-Tree, B+-Tree, and the O2-Tree used was m = 512.
Time was recorded for search, insert, and delete operations with update ratios varying between 0% and 100% for an index of 50M records, with the operations adding another 50M records to the index.
Based on these benchmark results, it is clear that B-Tree and T-Tree structures performed better than O2-Tree at update ratios of 0%-10%. However, as the update ratio increased, the O2-Tree generally performed better than most of the other indexing structures tested, with the B-Tree and Red-Black Tree structures showing the largest performance declines.
The Case for NoSQL
A quick introduction to NoSQL databases, highlighting the key areas where traditional relational databases fall short, leads to the first takeaway:
While relational databases offer consistency, they are not always optimized for applications that require storing and processing massive amounts of data across distributed systems.
NoSQL databases gained a lot of popularity due to high performance, high scalability, and ease of access. While consistency and reliability have historically been challenges for some NoSQL systems, a number of modern NoSQL DBMSs address these concerns by offering new features to enhance consistency and reliability.
Not all NoSQL database systems perform better than relational databases. MongoDB and Cassandra have similar, and in most cases better, performance than relational databases in write and delete operations. There is no direct correlation between the store type and the performance of a NoSQL DBMS. NoSQL implementations undergo changes, so performance may vary. Therefore, performance measurements across database types in different studies should always be updated with the latest versions of database software in order for those numbers to be accurate.
While I can’t offer a definitive verdict on performance, here are a few points to keep in mind:
- Traditional B-Tree and T-Tree indexing structures remain important foundations of database design.
- Modern NoSQL databases increasingly rely on LSM-tree architectures to support large-scale, write-intensive workloads.
- The benchmark results discussed in this article suggest that the O2-Tree can provide performance advantages for large datasets and workloads with high update ratios, though it remains an experimental choice.
- According to the same benchmark analysis, the B-Tree structure performed worse than the other indexing structures evaluated.
Further work continues to improve NoSQL DBMSs and expand the range of applications they can support. The integration of NoSQL and relational databases remains an important area of development and research.