
Declarative vs. Imperative Programming: A Practical Guide for Choosing the Right Paradigm
Deep understanding of declarative versus imperative programming shapes how developers write, run, and maintain code. This guide explains the differences, challenges, and when to choose each approach.

Deep understanding of declarative versus imperative programming shapes how developers write, run, and maintain code. This guide explains the differences, challenges, and when to choose each approach.

Thomas is a full-stack developer and technology architect with experience in SaaS, fintech, and enterprise systems. Skilled in JavaScript, Java, Node.js, React, and AWS, he builds scalable web applications, trading engines, and declarative workflow platforms for clients worldwide, combining deep engineering expertise with cross-domain problem-solving.
Expertise
Previous Role
Senior Software DeveloperPreviously At

Programming paradigms determine how developers approach problem-solving, structure logic, and manage application state. They also influence how software developers think about performance and debugging and how teams collaborate as an application scales. A firm grasp of these paradigms allows for more deliberate code design and better architectural choices.
In 2026, programming paradigms matter more than ever. Modern software systems are layered and abstracted:
- Front-end frameworks abstract Document Object Model (DOM) updates. Developers define the interface state instead of manually changing DOM elements.
- Infrastructure tools abstract server provisioning. Engineers define the desired infrastructure in configuration files rather than configuring servers step-by-step.
- Data tools abstract transformation logic. Teams define data models and transformations instead of writing procedural data scripts.
- AI tools abstract algorithmic complexity. Developers use higher-level interfaces instead of implementing algorithms from scratch.
Central to these paradigms is a fundamental distinction: whether you tell the system exactly how to do something (imperative) or describe what you want it to achieve (declarative).
Modern development increasingly favors declarative systems because they scale better in collaborative environments, integrate more naturally with CI/CD pipelines, support automation, and align well with version-controlled infrastructure.
However, declarative programming is often misunderstood, and the underlying mechanisms can be complex. It hides details inside components, and although each piece is predictable (same input, same output), significant processing still occurs behind the abstraction.
In my two decades building systems across SaaS, fintech, and enterprise environments, I’ve seen how imperative and declarative approaches play out in real-world systems as they scale. This article examines how these paradigms differ in practice, where each is most effective, and how they shape modern software and data systems.
Why Programming Paradigms Matter
The programming paradigm you choose has architectural consequences. It affects readability, bug frequency, cognitive load, refactorability, and your application’s scalability. This means that, especially when it comes to large systems, poor paradigm choices can create structural issues.
One consequence of using an unsuitable programming paradigm might be state explosion, where state becomes widely distributed, duplicated, or implicitly shared, increasing the number of possible system configurations and making behavior harder to reason about.
Hidden side effects, such as functions or components that modify shared state or trigger implicit behavior, reduce locality and make outcomes less predictable. Another issue might be brittle sequencing, where correctness depends on a specific order of operations, so small changes in timing or control flow can introduce subtle bugs.
Additionally, architectural assumptions may become deeply embedded, making incremental evolution difficult and large-scale refactorings riskier.
For developers, data engineers, and students, paradigms provide a framework for abstraction control. For example, a data engineer designing transformations can either write imperative Python loops that mutate tables step-by-step or define declarative SQL models that describe the desired output. On the other hand, a front-end developer can manually update DOM nodes (imperative) or define UI state and let a framework reconcile changes (declarative).
Understanding paradigms means knowing when to prioritize explicit control or expressive intent. These decisions influence maintainability years later.
Declarative Dominance in Modern Development
Modern engineering increasingly defaults to declarative tools, such as SQL for querying data, React for building user interfaces (UIs), Terraform for defining infrastructure as code, and Kubernetes for managing containerized applications.
All of these systems share a pattern: They allow developers to describe a desired state or outcome rather than scripting the exact sequence of steps to achieve it. This shifts the development approach toward a goal-oriented and outcome-driven workflow.
For example, with SQL, developers can request a dataset. In React, they can describe a UI for a given state. With Terraform, developers can define infrastructure resources. And, with Kubernetes, they can declare the desired number of running containers.
These tools’ underlying systems use planners, reconciliation loops, and optimizers to translate intent into step-by-step execution. Although declarative paradigms have become the norm, they are not universally superior. There are some trade-offs to consider: less transparent execution, more complicated performance tuning, dependency on optimizer quality, and harder debugging, which needs to happen through layers of abstraction.
What Is Imperative Programming?
In a way, imperative programming mirrors how CPUs operate. It emphasizes how tasks are accomplished through a series of ordered steps that the machine executes sequentially.
Fundamentally, imperative programming answers the question: “How exactly should this happen?” It is distinguished by a number of essential traits:
- Ordered instructions: Execution proceeds step-by-step, with each statement determining what runs next.
-
Explicit loops: Iteration is expressed through constructs like
forandwhile, defining how repetition occurs precisely. - Conditionals: Control flow branches through if/else statements that determine which instructions execute under specific conditions.
- Mutable variables: Values are reassigned over time, so state can evolve throughout the program’s execution.
- Direct state manipulation: Functions and procedures read from and write to shared state, making changes immediately and explicitly within the program’s execution flow.
In imperative programming, execution tends to be sequential and deterministic, meaning that imperative code typically expresses computation as an explicit sequence of state changes. Developers manage control flow and state directly, defining each operation that changes the program’s condition or produces a result. This approach provides full transparency and control over execution, but it also increases cognitive burden. Developers must track every mutation, dependency, and state change. As systems grow, this manual control may lead to a lot of mental overhead.

Definition and Core Principles
At its root, imperative programming is built around manual state and sequence management. This means that state changes are explicit in nature: Through the use of mutable variables, loops, and conditional statements, a developer describes exactly how a program should perform each operation in order.
The machine performs the given instructions in a predictable and deterministic way, and developers must handle variable updates, dependencies, and transitions between program states themselves. If something happens to break, they’re in charge of tracing mutation history, identifying sequencing errors, and reconstructing state transitions to understand what has gone wrong.
This level of control allows for fine-grained optimization, for example:
- Micro-optimizing loops, such as restructuring iteration to reduce repeated work, exiting early when conditions are met, or simplifying nested loops in sections that happen to be performance-sensitive, like real-time rendering pipelines in game engines.
- Controlling memory allocation, such as presizing collections (arrays, vectors, or hash maps) before inserting large numbers of elements, reusing existing objects, or reducing allocations in frequently executed paths.
- Managing concurrency manually, such as defining critical sections of the codebase, coordinating access to shared data, and explicitly handling synchronization between threads.
At the same time, this approach may introduce risk as the program grows or when different parts of state interact unpredictably. For instance, a shared configuration object might be updated by multiple modules, producing subtle bugs when one component changes values that another component assumes are constant.
The imperative programming paradigm aligns closely with how computers actually operate, and remains popular in systems programming due to its precision and predictability at the expense of verbosity and higher potential for human error.
Common Imperative Languages and Examples
Several programming languages are commonly used in the imperative style, even if they support other paradigms.
C is a classic example: a go-to choice for systems programming, focusing on functions, loops, and direct memory manipulation. Its design is largely procedural and imperative.
C++ builds on C with support for object-oriented as well as generic programming, but much of its code in practice is written imperatively, particularly when it comes to performance-critical systems.
While Java is a primarily object-oriented programming language, much of its everyday code relies on loops, mutable state, and sequential control flow, making it imperative in practice.
Similarly, Python and JavaScript, while being fully multiparadigm languages, can easily support imperative, object-oriented, and functional styles. Most scripts and application logic tend to follow imperative patterns.
Even in multiparadigm languages, imperative patterns dominate projects that handle step-by-step computations and straightforward procedural logic, as well as stateful operations.
Everyday analogies illustrate the imperative mindset: take, for example, making a sandwich by listing every step in sequence (spread the peanut butter, then jelly, then add the last slice of bread, in this specific order), or giving turn-by-turn directions to a passerby asking for help. Each set of instructions follows a specific sequence, where each step depends on the previous one, and the final outcome emerges from those explicit actions.
What Is Declarative Programming?
Declarative programming emphasizes describing the expected output rather than the specific steps required to achieve it.
In contrast with imperative programming, which explicitly articulates how a given outcome should happen, declarative programming asks this question: “What outcome do I want?” Instead of controlling execution, developers describe the desired outcome (what needs to happen), while the systems determine how it happens.
Its essential traits are:
- Minimal control flow description: Developers rarely specify loops or the exact order of operations. Instead, the system determines the sequence needed to produce the intended result.
- Reduced mutation: Values are often immutable or updated indirectly, so programs rely less on changing shared state.
- Reduced side effects: Functions tend to produce outputs without altering unrelated parts of the system, which means behavior is more predictable.
- High abstraction level: Developers work with concepts, rules, or queries instead of low-level operations, focusing on what should happen rather than how it happens.
Declarative code expresses relationships and generally avoids specifying the precise order of execution. It’s up to the engine to determine order, optimization, and execution strategy. This paradigm reduces the need for manual control flow and state tracking. Rather than explicit instruction, code relies on abstraction.

Definition and Core Principles
Rather than describing a step-by-step process, declarative programming describes what the program should do or achieve. As opposed to imperative programming, where engineers control execution order or manually update state, here their role involves defining relationships, constraints, or transformations, as well as letting the system determine how to produce the desired result.
With this paradigm, code often relies on immutable data and referential transparency, which means that an expression can be replaced with its resulting value without changing the program’s behavior. Functions and expressions are designed to produce the same output given the same input, with no other parts of the program being altered throughout the workflow. This style expresses logic without specifying control activity.
The principles of declarative programming naturally create systems that tend to be less error-prone and easier to parallelize or scale than imperative programming, because independent computations can run without unintended interactions.
For example, declarative approaches let programmers:
- Define data transformations: Developers can write queries or map/filter operations that describe the desired result set, rather than looping through arrays and updating elements manually.
- Describe UI state: Libraries like React let programmers declare what the interface should look like for a given state without specifying DOM operations or event handling order.
- Express constraints or rules: In SQL or logic programming, which allow developers to declare relationships between entities and conditions that must hold true, leaving the engine to determine how to evaluate them.
At the same time, this abstraction can obscure how computations happen under the hood, making performance tuning and debugging less straightforward. For instance, understanding exactly how a complex SQL query executes or how a reactive UI updates in response to multiple state changes can require inspecting the underlying runtime behavior or engine, adding extra steps in case of breakage.
Declarative programming is increasingly popular for specific areas like data processing, UI design, and configuration management. This is largely because it simplifies how developers reason about programs, reduces reliance on mutable state, and emphasizes outcomes over mechanics.
Declarative Languages and Environments
Some programming languages are designed specifically for declarative programming, or strongly support declarative patterns, even if they also allow imperative code.
Haskell, for example, is a pure functional language. Computations are expressed as transformations on immutable data, and functions return the same output for the same input without modifying the shared state.
Prolog operates on facts and rules: Rather than writing step-by-step instructions, developers describe the relationship between components (like family relations, graph paths, logical dependencies) and let the system figure out how to satisfy the given queries.
HTML is declarative in structure too. This is visible in how it lists attributes and elements to define the content of a page without specifying how the browser should render them.
Declarative patterns also appear inside multiparadigm languages like JavaScript and Python. When working with these languages, engineers may use certain constructs (like map, reduce, filter, and list comprehension) to describe transformations over collections, rather than manually iterate through and update state.
When it comes to environments, libraries and frameworks have the power to extend declarative design into higher levels. For example, React supports this by describing UI states as components, updating the DOM automatically when state changes. Terraform lets infrastructure be described as the end state of resources. Engines are in charge of determining how to reach that state.
The main idea is expressing what outcome is wanted. Going back to the earlier sandwich example, with declarative programming, someone might describe the combination of ingredients and let the order be handled implicitly.
Abstraction and Compilation Under the Hood
What is particularly important to understand is that, ultimately, declarative instructions are always compiled into imperative code that the system executes behind the scenes. The point is that declarative programming allows developers to operate at a higher level or, in other words, further away from machine-level code, creating an extra layer of abstraction.
An example of this workflow could be:
- React reconciling the Virtual DOM in memory, then applying minimal updates to the real DOM.
- SQL building an execution plan with operators (joins, filters, scans) and running them step-by-step.
- Terraform converting resource definitions into API calls to create or update cloud infrastructure.
- Kubernetes running a continuous reconciliation loop, comparing desired versus actual state, and applying changes.
The abstraction hides procedural detail. For a real-world analogy, imagine this process as entering a destination into a GPS app to drive to a preferred destination. You describe the goal (destination), and the system takes care of calculating the route. The same happens in declarative programming, with a developer specifying the “destination” and the systems managing every underlying step to reach it.
Declarative vs. Imperative: Key Differences
The core distinction between the two paradigms lies in how versus what. I see declarative and imperative code as layers. Declarative code gives the 40,000-foot view of what should happen while imperative code handles the details to make it happen.
Imperative and declarative styles differ sharply in how they handle mutability, state, and side effects such as writing to shared variables or triggering external operations like file writes or network requests.
Imperative Programming
- Explains how to perform a task step-by-step
- Relies on explicit control flow
- Requires manual optimization, meaning the developer decides how to improve performance and manage mutable state
Imperative programs tend to be stateful: Variables are updated as the program runs, and each step depends on the state produced by the previous one. Loops, counters, and conditionals progressively change program state as execution moves forward.
Declarative Programming
- Defines what the desired outcome should look like
- Relies on system optimization and lets compilers or engines handle efficiency
- Expresses the logical relationships between components as well as outcomes, without detailing any execution sequence
- Prefers immutability, with expressions typically evaluated based on the input data rather than step-by-step program state
Declarative programs tend to be state-minimizing: They focus on expressing results from inputs rather than updating shared variables step-by-step.
Control Flow vs. Logic
A clear conceptual distinction between imperative and declarative programming lies in how control flow is handled.
Imperative programming defines control flow explicitly. The engineer specifies the sequence of operations that the machine has to perform. This can be done using constructs such as the following:
- Loops (
for,while) - Conditional branches (
if,switch) - Explicit function calls
- Step-by-step variable mutations
In this paradigm, the developer is responsible for determining the exact order of execution, as well as the conditions under which each step occurs. Consequently, the code reads like a set of instructions given to the computer, not unlike a procedural checklist.
Declarative programming, on the other hand, moves away from procedural sequencing and focuses on logical description. Rather than telling the system how to perform a specific task, the programmer describes the desired outcome or relationship between data elements (such as selecting records that match a condition or defining the final state of a system). It is the runtime system, compiler, or engine that determines the execution strategy (the how).
In declarative programming, constructs are less like procedural instructions and more like definitions of results, like:
- Queries.
- Rules.
- Expressions.
- Configuration blocks.
For example, in a declarative query written in SQL, the engineer tells the system which records should be returned. It is the database engine that decides whether to use indexes, parallel execution, join reordering, or other strategies to retrieve the desired data.
The difference lies in control: Imperative logic instructs, while declarative logic describes.
State Management and Side Effects
On a technical level, state management is one of the most significant differences between the two paradigms.
Imperative code typically relies on mutable state, meaning that variables can change value throughout the execution of a program. As the program runs, it updates these variables in place. For example, a loop that increments a counter or updates elements in an array step-by-step directly modifies the program’s internal state. Algorithms following this paradigm are flexible, but they may also introduce complexity as each operation depends on previous state mutation, such as updating a shared configuration object or maintaining a running total across multiple steps.
And when multiple parts of a system modify a shared state (like a shared configuration object), developers must pay attention to meticulously manage:
-
Sequencing dependencies (e.g, ensuring that
initialize()runs beforeprocess()accesses the same variables). - Synchronization (e.g, wrapping access to a shared counter in a mutex to prevent concurrent updates from corrupting the value).
- Race conditions (e.g, two threads writing to a file at the same time).
- Unintended side effects (e.g, updating a configuration object that other modules rely on, triggering unexpected behavior elsewhere).
Declarative programming takes a different approach: It minimizes mutable state whenever possible. Rather than repeatedly modifying variables, it relies on immutable data structures and expressions that describe transitions from input to output. For instance, using a map or filter operation over a list produces a new collection without changing the original.
In this model, outputs depend only on inputs, functions often avoid modifying external state, and computation is at a higher level, meaning it is easier to reason about.
Declarative paradigms, therefore, constrain mutation and isolate side effects. When these side effects occur (such as writing to a database or updating the DOM, both of which modify something outside the function’s local scope), they are typically isolated within system boundaries. This separation supports developers in reasoning about behavior and data flow through the system transparently. Imperative systems, by contrast, require developers to constantly manage the risks associated with mutable and interdependent state.
Readability, Maintainability, and Optimization
The way code evolves as systems grow in complexity is another major difference between paradigms.
Imperative programs can become difficult to maintain as logic expands and grows. Over time, codebases often accumulate deeply nested loops, branching condition trees, shared mutable state, and tightly coupled procedural logic. These may make it harder for engineers to follow how data flows through the system, and the codebase itself may become hard to refactor.
Emphasizing intent over procedure, declarative programs tend to be better for readability overall. Programmers don’t have to trace multiple control paths, but can maintain control over ideally concise expressions that describe the desired output. For instance, developers can express complex operations in a compact and intention-focused way by using declarative constructs like SQL queries, functional pipelines, or component declarations in UI frameworks.
Still, there are challenges introduced by abstractions. Declarative systems rely heavily on optimizers, planners, and compilers. Both correctness and overall performance depend on how these underlying components translate high-level intent into operations.
Real-world Examples and Analogies
Programming paradigms can feel abstract. Everyday analogies can help illustrate the differences between declarative and imperative programming in a more concrete way.
Imperative programming resembles giving detailed instructions for every action required to complete a specific task. On the other hand, declarative programming is akin to describing the desired result and letting an expert (the system) handle the whole process.
Several common scenarios illustrate this contrast.
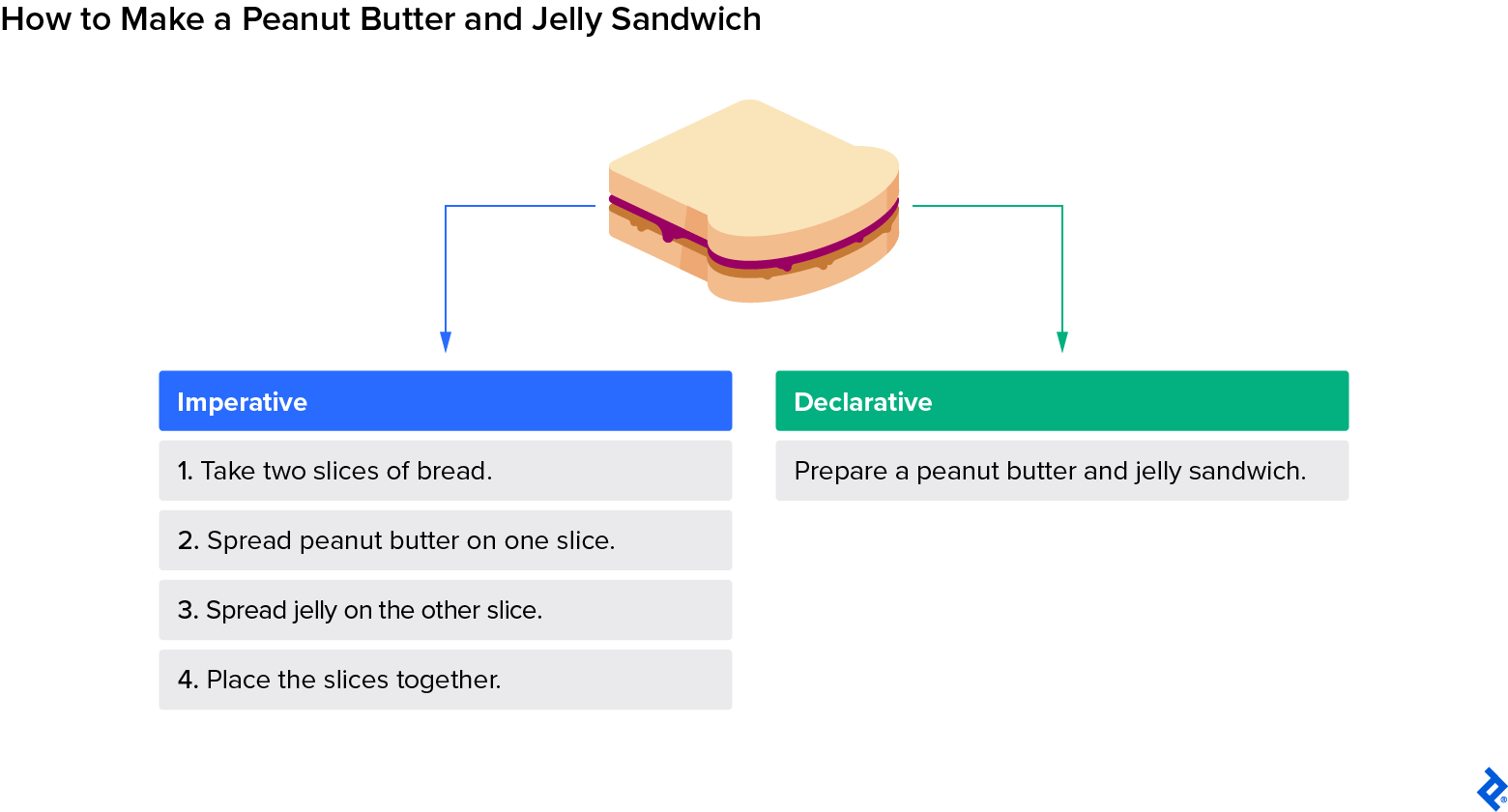
Making a peanut butter and jelly sandwich is, as previously seen, a classic imperative example. If someone were to follow instructions exactly, they might note every step as follows:
- Take two slices of bread.
- Spread peanut butter on one slice.
- Spread jelly on the other slice.
- Place the slices together.
Each action here has to be explicitly defined.
A declarative version of the same task might be simply saying:
“Prepare a peanut butter and jelly sandwich.”
Here, the instructions are implicit: It is the system (or person, in this case) performing the task that is in charge of the steps.
Another analogy can be drawn from driving. Driving a manual transmission vehicle requires constant step-by-step control: shifting gears, handling the clutch timing, manually adjusting speed, and so on. In contrast, an automatic transmission lets the driver focus on the destination while the vehicle handles all those steps automatically.
These analogies easily demonstrate how imperative systems need the “user” (the programmer) to manage every individual operation, while declarative systems rely on an underlying “expert engine” that interprets intent.
Code Comparisons
In terms of code, data in a list is a common example that demonstrates paradigm differences.
In an imperative approach, the programmer typically writes a loop iterating through each element of the list and manually applies the transformation. The developer has to manage iteration index, track state, and update values one by one.
numbers = [1, 2, 3, 4]
doubled = []
for i in range(len(numbers)):
doubled.append(numbers[i] * 2)
print(doubled)In a declarative approach, the developer describes the transformation as a whole. Many modern programming languages provide higher-order functions (such as map) that express the intent of applying a function to every element in a collection. However, the iteration itself is handled by the runtime system.
numbers = [1, 2, 3, 4]
doubled = list(map(lambda x: x * 2, numbers))
print(doubled)Data processing provides another comparison. In imperative data pipelines, such as custom Python ETL scripts or manual data processing jobs built with loops and conditional logic, engineers might construct queries programmatically and define control flow managing iteration over rows and defining single steps. In declarative systems, such as SQL, developers specify the dataset they want and leave query optimization to the database engine.
UI frameworks and libraries also show this difference. With React, for example, developers describe how the interface should appear given a particular application state. React’s reconciliation algorithm updates the DOM as needed. Internally it works imperatively, but developers write declaratively.
Everyday Scenarios
When someone enters a destination into a GPS system, they provide the endpoint. The navigation software calculates the route while adjusting for traffic conditions, and provides directions in a dynamic way. This mirrors declarative programming: The user describes the goal and the machine determines the process.
Providing detailed step-by-step directions to a lost passerby asking for help, on the other hand, mirrors imperative programming. In this case, the person giving directions specifies every turn, intersection, and landmark required to reach the destination.
Another everyday analogy involves a restaurant setting. When entering a restaurant, a customer may tell a host: “We need a table for two.” This is a declarative request. The host (the system) determines where to seat them, considering table availability and room layout. However, if the customer navigates the room themselves to locate a free seat, this would be an exemplification of the imperative method, where the customer manages each decision manually.
These scenarios reinforce the core idea: Declarative thinking emphasizes what outcome, while imperative thinking emphasizes how the outcome is achieved.
Pros and Cons of Each Paradigm
When talking about declarative versus imperative programming, it’s important to note that one is not universally better than the other. Both paradigms coexist in modern software engineering and are, in fact, often combined within the same system.
Each paradigm reflects a different compromise between control and abstraction.
Imperative programming provides fine-grained control over program behavior. Developers can define every system operation. This type of control can be essential, especially in performance-sensitive contexts or when interacting with memory, hardware, or other system resources.
Declarative programming increases the level of abstraction. Developers define the intended outcome rather than the steps required to achieve it. A runtime engineer, compiler, or framework is then in charge of determining how the result will be reached.
The advantages and limitations of each of these paradigms emerge from these differing priorities. Modern software stacks frequently blend the two, applying declarative paradigms at higher architectural levels and utilizing imperative logic within lower-level implementation layers.
Imperative Advantages and Limitations
Advantages
Fine-grained Control
Advantages of imperative paradigms have to do with providing control over how exactly a program runs, with explicit instructions regarding:
- The order of execution.
- When variables change.
- How memory is accessed.
- How loops and conditions operate.
For real-time applications, embedded systems, graphics engines, performance-critical algorithms, and systems programming, this degree of control is especially important. Examples are game engines, operating systems, and embedded firmware.
Predictable Performance Behavior
Because imperative code explicitly defines execution steps, reasoning about performance is more direct for engineers.
Take, for instance, writing a loop that processes a collection of items. The engineer knows exactly how many iterations occur, how memory is accessed, and when data is modified. Such predictability can be very helpful for applications like financial systems and game engines.
Transparency During Debugging
Debugging imperative code may be easier due to execution following an explicit sequence of instructions. Debugging tools can step through each line of code so that engineers can inspect:
- Variable values.
- Branches and their control flow.
- Function calls.
- Any state change.
Thanks to this transparency, it’s easier to diagnose logic issues or other bottlenecks.
Limitations
Complexity Growth During Scaling
When applications grow and become more complex, imperative code may be difficult to maintain. Because logic is defined step-by-step, complex programs run the risk of accumulating a series of elements (nested loops, conditional branches, mutable shared state, etc.) that may produce “spaghetti code,” where understanding the system requires tracing a large number of interdependent operations.
Here, careful architectural design is required for imperative code to be successful even with multifaceted applications.
Risks of Mutable State
Imperative systems rely heavily on mutable variables, which can introduce subtle bugs, such as race conditions in concurrent systems (two threads attempting to update the same counter simultaneously), unexpected side effects from shared state (a function modifying a global variable that other modules rely on), and order-dependent bugs.
When multiple parts of the same program modify the same state variables, engineers must be careful: Coordination of updates and dependencies needs to be done tactfully to avoid bottlenecks of this kind.
Database and Migration Risks
In database environments, imperative logic may be at its most fragile. Traditional migration flows tend to rely on sequential scripts that assume the database begins in a specific state. If that assumption happens to be incorrect (for example, because a migration was skipped), the script might fail or even produce unintended results.
Schema mismatches, inconsistent data, duplicated migrations, and accidental data loss are all possible consequences of dealing with database migrations with imperative setups without strict version control and migration management practices.
Declarative Advantages and Limitations
Advantages
Improved Readability and Expressiveness
Declarative code is generally easier to read and understand because it is high level, and it emphasizes intent rather than procedure.
Instead of writing many lines of control-flow logic, programmers can describe the result they want to obtain from the system.
A SQL query, for example, can express complex filtering and aggregation in a single statement. The database engine then handles indexing, ordering, and execution to pull the desired data.
Readability is one of the main reasons declarative code is easier to plan, review, discuss, and ultimately maintain.
Better Alignment With Modern Automation Workflows
Declarative programming reflects modern development practices that focus on reproducibility.
Declarative configuration files describe the desired state of infrastructure or services. Tools at hand (such as Kubernetes or Terraform) then take this description and compare the desired state with the current system state and reconcile the differences.
These systems use state reconciliation loops: Automated controllers monitor the system continuously and adjust needed resources until they match the declared configuration. The consequence is reliable infrastructure management.
Strong Compatibility With CI/CD and Version Control
Declarative configurations describe the final state of a system. This is why they can be stored easily in version-controlled repositories.
In this sense, they reflect modern engineering practices like:
- GitOps workflows.
- Continuous integration pipelines.
- Automated deployments.
- Environment replication.
Through pull requests, engineers can review configuration changes, track their history, and apply updates across environments such as development and production.
Limitations
Reduced Control Over Execution Details
Due to declarative paradigms being high-level and further away from strict machine logic, programmers have to relinquish some control over how tasks are executed.
Because it is the runtime system that determines the execution strategy, developers might not be able to directly control the execution order, memory usage patterns, and optimization and concurrency techniques.
This is not always a drawback, but it can become limiting when precise performance tuning is required.
Dependency on Optimizers and Runtime Engines
Declarative systems rely heavily on compilers, query planners, or runtime frameworks to translate high-level intent into operations that can be executed freely.
If these systems perform poorly, programmers may need to restructure their declarative definitions. For example, database query planners determine how queries are executed, which means developers must sometimes understand indexing strategies and query plans to fully understand how to achieve good performance.
Debugging Abstraction Layers
Debugging declarative programs can be more difficult because execution takes place behind a number of abstraction layers.
Instead of tracing explicit instructions, programmers often need to investigate:
- Generated execution plans.
- Framework life-cycle hooks.
- Reconciliation logs.
- Compiler outputs.
When diagnosing issues, developers must understand how the underlying system interprets declarative definitions.
Applications in Data and Software Engineering
Modern software systems are typically made up of different layers. This setup naturally favors using different paradigms within a single application.
Imperative programming is often used in contexts that involve procedural execution, or where the sequence of operations holds the most importance.
Declarative programming, on the other hand, dominates the configuration and orchestration layers. Here, systems benefit from their inherent capacity to describe the desired outcome.
It is common to see modern technology stacks mixing both paradigms across the different architectural layers. Back-end services, for example, often implement business logic imperatively while counting on declarative configuration for routing, security policies, and deployment. Infrastructure management systems do something similar: Tools like Terraform use declarative configuration files while executing imperative API calls under the hood. Data engineering pipelines often define transformations declaratively through SQL models while executing them as procedural query plans inside the database engine, and front-end UIs describe component state declaratively while frameworks handle DOM updates imperatively.
It is easier for engineers who understand both paradigms to select the right level of abstraction for each part of their application.
Databases and Schema Management
Database environments are an example of a system with layers that may be distributed across imperative and declarative paradigms. While this separation is not strict, it reflects differences in approach: Certain components naturally lend themselves to one or the other.
Imperative SQL scripts are inherently imperative. Traditional database migrations are often scripted as such. These specify every action required to modify the database structure (creating tables, altering columns, adding indexes, managing data). As each step must be executed sequentially, these scripts assume that the database already exists in a specific state. If that is not the case (for example, due to missing migration), the script may fail, leading to issues like duplicated schema changes or conflicting migrations.
Modern database workflows tend to add an extra layer of abstraction by adopting declarative schema definitions. In this model, programmers describe the database structure through configuration files in YAML or similar formats. A compiler or management tool then compares the desired schema with the existing database state and generates the SQL statements necessary to sync them. This approach helps with version control and environment replication, making them easier and more intuitive. Migrations and schema enforcement also become more manageable, and developers don’t need to manually write migration scripts for each and every structural change.
However, hybrid database migration systems exist. They combine declarative and imperative approaches. There are several ways to do this, but two common strategies are log-based systems and check-based systems.
Log-based systems record every schema change as a sequential migration script that is applied in chronological order. Check-based systems validate the current schema state before applying changes, ensuring migrations only run when specific conditions are met.
It’s important to note that the DataOps movement, which advocates for quality, speed, and reliability of data analytics, has promoted fully declarative infrastructure and data management practices. In this model, environments are defined through version-controlled configuration files, and automated tools validate schema consistency.
Additional reconciliation processes ensure that systems match their declared definitions. This highlights that database systems tend toward declarative interfaces, even though they rely on imperative mechanisms internally.
Front-end Frameworks
The shift from imperative to declarative programming is possibly most visible in front-end systems development.
Earlier libraries (such as jQuery) required engineers to manipulate the browser’s DOM directly by selecting elements, modifying attributes, updating styles, etc. In other words, programmers had to implement a rather imperative approach. The risk in this style was a UI logic that was particularly complex and therefore more fragile.
More modern libraries such as React have introduced a declarative model. Instead of manipulating the DOM directly, it is now possible for engineers to define interface characteristics based on application state. The framework or library then calculated the minimal changes needed to update the actual DOM.
Similar to database systems, React enables this through a reconciliation algorithm that compares virtual representations of the UI and determines the changes that are needed.
Functional Programming as a Declarative Subset
Functional programming is one of the most prominent forms of declarative programming. With this approach, developers write code using pure functions, immutable data, and higher-order functions.
While pure functions and immutable data minimize unintended side effects and make program behavior easier to reason about, higher-order functions (like map, reduce, and filter) support the expression of transformations on collections without the need to manage iterations explicitly. For instance, instead of writing loops, developers describe the transformation that should be applied to each element.
Functional programming also highlights referential transparency, which means that functions will always produce the same output for the same input. This property makes thinking about program behavior easier. Using stateless, pure functions like map, reduce, or filter leads programmers to think in a more declarative way: They begin to focus on transforming data rather than step-by-step processes.
Overall, functional programming is well suited to modern distributed and parallel computing environments thanks to its particularly high-level characteristics.
Choosing the Right Approach
Choosing between declarative and imperative programming is rarely an either-or decision, as most modern systems combine both paradigms and apply both depending on where each provides the greatest benefit.
The decision mostly revolves around abstraction level and control requirements. Declarative styles, by definition, increase abstraction. Engineers can describe the intended result while delegating execution details to frameworks, compilers, or runtime engines. Imperative programming goes the opposite way, reducing abstraction by exposing execution to the engineer directly.
A principle in software architecture says that developers generally begin with the highest level of abstraction that solves the problem at hand, before moving on to lower-level control only when system limitations or other blockers require it. In practice, this means starting with a declarative approach and only dropping to imperative code when necessary.
When to Use Imperative Programming
Imperative programming is most appropriate when developers have to manage granular execution behavior:
- Performance-critical algorithms: Games, trading systems, or real-time analytics need speed. Imperative code lets developers control memory, loops, and execution precisely, which is why an imperative approach is better suited.
- System-level programming: Operating systems, embedded firmware, and device drivers directly interact with hardware components. In these environments, programmers need precise control, which declarative abstractions generally cannot provide.
- Low-level concurrency management: Handling multiple threads or asynchronous events safely requires managing locks and coordination. Imperative gives that control. With it, developers can manage synchronization mechanisms without intermediaries.
- Deterministic execution environments: Some systems must behave in strictly predictable ways, such as robotics control software or safety-critical systems. Imperative programming lets developers define the exact sequence of operations.
- Debugging and optimization: Imperative logic also becomes valuable when debugging or optimizing systems. In declarative frameworks, the transparency provided by a step-by-step method is helpful in diagnosing complex problems that might be concealed behind abstraction layers.
Today, with AI generating code from prompts, outputs tend to default to imperative styles. If developers want a more structured declarative solution, they must explicitly guide the model toward that approach.
When to Use Declarative Programming
Declarative programming excels when the main goal is expressing system configuration or specific expected outcomes. This approach works particularly well in areas where reproducibility and automation are more important than manual control.
- High-level system design and orchestration: Many modern tools use declarative models to describe infrastructure, application behavior, or data transformations. Think Kubernetes, Terraform, or React, which rely on declarative definitions to manage environments.
- Database querying and data transformation: With query languages (such as SQL), programmers are able to describe datasets and relationships without specifying how the database engine should retrieve the data. Database query planners then generate optimized execution strategies.
- Infrastructure as code (IaC): Teams use infrastructure tools to define servers and cloud resources through configuration files. Instead of manually provisioning resources, developers declare the infrastructure structure and let automated systems create or update resources accordingly.
- UI development: Modern UI frameworks use declarative component definitions that describe how the interface should appear given a specific state. The framework determines the most efficient way to update the interface when the state changes.
- Configuration-driven systems: Many large-scale platforms rely on configuration files to define application behavior. These configurations can be validated, version controlled, and automatically applied across multiple environments.
- Collaboration within engineering teams: Because declarative code describes a desired system state, it is often easier for multiple contributors to understand and review changes. Configuration files and specifications can be inspected in pull requests.
Hybrid and Contextual Decisions
In modern software engineering, purely declarative or purely imperative systems are quite rare. Engineers tend to combine both within layers of a system.
A common pattern looks like this:
Declarative Layers
- Infrastructure definitions
- Deployment configurations
- UI component structures
- Database queries
Imperative Layers
- Application logic
- Data processing algorithms
- System utilities
- Performance optimizations
Declarative layers give this structure its high-level organization, while imperative code manages the specific operational behavior.
At the same time, many declarative frameworks provide “escape hatches” that let developers easily fall back to imperative logic if needed. For instance, UI frameworks allow custom event handlers, and infrastructure tools allow procedural scripts for edge cases where granular control might be necessary.
The best systems tend to follow a pattern in which each paradigm follows its nature: Declarative structures define intent, and imperative code implements specialized, precise behavior.
Balancing Declarative and Imperative Approaches
Programming paradigms are best understood as points along a spectrum rather than rigid categories. Imperative and declarative approaches reflect different ways of thinking about problems: One focuses on controlling the exact sequence of operations, while the other describes intention and lets the system determine how to get there.
Successful engineers are familiar with both paradigms and are able to switch between them based on the needs of a particular problem, the limitations of the environment, and the appropriate degree of abstraction.
Still, across modern software engineering, the broader trend has been a gradual shift toward declarative development models. From infrastructure orchestration and database querying to front-end frameworks, declarative approaches help teams express intent more clearly while delegating repetitive procedural logic to the underlying system. This shift often improves readability, scalability, and development speed, especially in collaborative environments.
At the same time, imperative programming remains indispensable. Performance-critical algorithms, system-level programming, and debugging workflows often require the explicit control that imperative code provides, even within declarative-first systems. The most innovative software architectures, therefore, combine both paradigms: Declarative layers define the structure and desired state of a system, while imperative code serves as a precise implementation tool for lower-level control.
Developers looking to strengthen their programming skills should experiment with declarative and functional techniques: Immutability, higher-order functions, and descriptive configuration patterns are a few examples. These techniques promote more manageable codebases over time and lessen unexpected side effects. Using these concepts can enhance code quality and architectural clarity even when working with multiparadigm languages.
Top FAQs About Declarative vs. Imperative Programming
Is SQL declarative or imperative?
SQL is declarative because it describes the desired dataset rather than the step-by-step retrieval process, though procedural extensions like PL/SQL can add imperative control.
Is React declarative or imperative?
React is declarative in how it defines UI state and structure but operates through imperative DOM manipulation under the hood.
Can a language be both declarative and imperative?
Yes, many modern languages, including Python, JavaScript, and C#, are multiparadigm, enabling developers to combine both styles as needed.
When should I use declarative programming over imperative?
Use declarative logic for configuration, automation, and state-driven UIs, and reserve imperative control for low-level performance or tightly sequenced tasks.
What are the advantages of declarative programming?
Declarative code improves readability, maintainability, and parallelism by focusing on intent rather than execution details.
What are the advantages of imperative programming?
Imperative approaches offer explicit control, predictable performance, and fine-grained management of system resources at the cost of higher complexity.
Additional Resources
For readers interested in exploring related programming concepts, consider reading this article about declarative development FSM programming for a deeper technical examination of declarative design patterns and their applications in layered systems. Additionally, several well-known educational platforms provide complementary discussions of declarative and imperative paradigms, including Dataops.live, ui.dev, and GeeksforGeeks.
Further Reading on the Toptal Blog:
Understanding the basics
Declarative programming focuses on what the system should do, letting the platform handle execution. Imperative programming focuses on how tasks are executed step-by-step, giving developers full control over state and flow.
Use declarative approaches for UI state, database queries, cloud infrastructure, or workflows. It reduces boilerplate, enforces reproducibility, and simplifies collaboration by expressing intent rather than manual execution steps.
Imperative code is better for performance-critical algorithms, embedded systems, low-level concurrency, robotics, or real-time processing, where developers need explicit control over memory, execution order, and synchronization.
Yes. Modern software often combines both: Declarative layers define intent (UI, configs, queries), while imperative code handles detailed execution, performance tuning, or edge-case logic that abstractions can’t efficiently manage.
Declarative workflows define the desired state, track changes via version control, and allow automated reconciliation. This reduces human error, ensures auditability, and makes reproducing environments or pipeline runs straightforward.

Kochi, Kerala, India
Member since October 15, 2020
About the author
Thomas is a full-stack developer and technology architect with experience in SaaS, fintech, and enterprise systems. Skilled in JavaScript, Java, Node.js, React, and AWS, he builds scalable web applications, trading engines, and declarative workflow platforms for clients worldwide, combining deep engineering expertise with cross-domain problem-solving.
Expertise
Previous Role
Senior Software DeveloperPREVIOUSLY AT