
SQL Indexes Explained, Pt. 2
Sorting a table can make some queries faster—but the maintenance cost is untenable. Enter real database indexes and their most common implementation structure: the B-tree.

Sorting a table can make some queries faster—but the maintenance cost is untenable. Enter real database indexes and their most common implementation structure: the B-tree.

Mirko designs and develops massive, extreme-workload databases. He also trains software developers on databases and SQL.
Expertise
In the first lesson of SQL Indexes Explained, we learned to use sorting to speed up data retrieval. While our query execution is faster after rows are sorted, the sorting involves reading every row at least once and moving them around. That makes the method slower and less efficient than simply reading the entire table sequentially.
The logical conclusion seems to be that we should maintain sorted copies—which we’ll officially call SQL indexes, prefixed with IX_—of a given table. The retrieval algorithms from the first article would then be applicable, and we would not need to sort the table before starting.
The Index as a Sorted Copy of the Table
Let’s take a look at the literal implementation of that idea, again using Google Sheets. Our Reservation spreadsheet becomes a collection of five sheets containing the same data. Each sheet is sorted according to different sets of columns.
The exercises here are intended to be less exacting than in the previous SQL index tutorial article—they can be done more by feel than by timer and row count. Some exercises will seem very similar, but this time, we’re exploring:
- How to more efficiently retrieve data when using separate indexes rather than sorted primary tables
- How to maintain order in each index and table when modifying data
The previous tutorial focused on reads, but in many common real-world data dynamics—our hotel reservations included—we have to take into account the effects of indexing on write performance, both for inserting new data and updating existing data.
Preliminary Exercise: Cancel a Reservation
To get a feel for SQL index performance using the sorted table strategy, your task is to delete a reservation for Client 12, from the 22nd of August 2020, in Hotel 4. Keep in mind that you have to remove a row from all copies of the table and maintain the correct sorting.
Done? It should be clear that the idea of keeping multiple sorted copies of the table is not as good as it seemed. If you still have any doubts, you can also try to re-insert the reservation you just deleted or change the date of an existing reservation.
While sorted copies of the table allow for faster retrieval, as we learned just now, data modification is a nightmare. Whenever we need to add, delete, or update an existing row, we will have to retrieve all copies of the table, find a row and/or the place where it should be added or moved, and finally move blocks of data.
SQL Indexes Using Row Addresses
This spreadsheet contains indexes that use a different approach. Index rows are still sorted according to specific criteria, but we don’t keep all the other information in the index row. Instead, we keep just the “row address,” the address of the row in the Reservations sheet—representing the table itself—in column H.
All RDBMS implementations use an operating system–level capability to quickly find the block on the disk using a physical address. Row addresses typically consist of a block address plus the row’s position within the block.
Let’s do a few exercises to learn how this index design works.
Exercise 1: All of a Client’s Reservations
As in the first article, you are going to simulate the execution of the following SQL query:
SELECT *
FROM Reservations
WHERE ClientID = 12;
Again, there are two reasonable approaches. The first one is simply reading all rows from the Reservations table and fetching only rows matching the criteria:
For each row from Reservations
If Reservations.ClientID = 12 then write down Reservations.*
The second approach involves reading data from the IX_ClientID sheet, and for any item matching the criteria, finding a row in the Reservation table based on the rowAddress value:
Get first row from IX_ClientID where ClientID = 12
While IX_ClientID.ClientID = 12
Fetch Reservations.* where rowAddress = IX_ClientID.rowAddress
Write down Reservations.*
Get next row from IX_ClientID
Here, the expression Get first row from is implemented by a loop similar to those seen in the previous article:
Repeat
Fetch next row from IX_ClientID
Until ClientID >= 12
You can find a row with a given rowAddress by sliding down until you find a row, or using a filter on the rowAddress column.
If there were just a handful of reservations to be returned, the approach using the index would be better. However, with hundreds—or sometimes even just tens—of rows to be returned, merely using the Reservations table directly can be faster.
The volume of reads depends on the value of ClientID. For the largest value, you have to read the entire index, while for the lowest value, it is at the beginning of the index. The average value is half of the number of rows.
We’ll return to that part later and present an efficient solution. For now, let’s focus on the part after you find the first row matching our criteria.
Exercise 2: The Number of Reservations Starting on a Given Date
The task is to count the number of check-ins on the 16th of August 2020, using the new index design.
SELECT COUNT (*)
FROM Reservations
WHERE DateFrom = TO_DATE('2020-08-16','YYYY-MM-DD');
The approach of using the appropriate index for counting is superior to a table scan, no matter the number of rows involved. The reason is that we do not have to access the Reservations table at all—we have all information we need in the index itself:
Count := 0
Get first row from IX_DateFrom where DateFrom >= '2020-08-16'
While found and DateFrom < '2020-08-17'
Count := Count + 1
Get next row from IX_DateFrom
Write down Count
The algorithm is basically the same as one using sorted tables. However, the index row is much shorter than the table row, so our RDBMS would have to read fewer data blocks from the disk.
Exercise 3: Criminal Investigation (Guest List Given Hotel and Date Range)
Let’s prepare a list of guests that arrived at Hotel 3 on the 13th and 14th of August 2020.
SELECT ClientID
FROM Reservations
WHERE DateFrom BETWEEN (
TO_DATE('2020-08-13','YYYY-MM-DD') AND
TO_DATE('2020-08-14','YYYY-MM-DD')
) AND
HotelID = 3;
We can read all the rows from the Reservations table or use one of the available indexes. After doing the same exercise with a table sorted according to specific criteria, we found out that the index IX_HotelID_DateFrom is the most efficient.
Get first row from IX_HotelID_DateFrom where
HotelID = 3 and
DateFrom between '2020-08-13' and '2020-08-14'
While found and DateFrom < '2020-08-15' and IX_HotelID_DateFrom.HotelID = 3
Fetch Reservations.* where rowAddress = IX_HotelID_DateFrom.rowAddress
Write down Reservations.ClientID
Get next row from IX_HotelID_DateFrom
Can We Design an Even More Efficient Index?
We access the table because of the ClientID value, the only information we need for the list of guests we’re reporting. If we include that value in the SQL index, we don’t have to access the table at all. Try to prepare a list reading only from just such an index, IX_HotelID_DateFrom_ClientID:
Get first row from IX_HotelID_DateFrom_ClientID where
HotelID = 3 and
DateFrom between '2020-08-13' and '2020-08-14'
While found and HotelID = 3 and DateFrom < '2020-08-15'
Write down ClientID
Get next row from IX_HotelID_DateFrom_ClientID
When the index contains all the necessary information for query execution, we say that the index covers the query.
Exercise 4: List of Guests’ Names Instead of IDs
A list of guest IDs would be useless for a police officer investigating a crime. We need to provide names:
SELECT c.ClientName
FROM Reservations r
JOIN Clients c ON r.ClientID = c.ClientID
WHERE r.DateFrom BETWEEN (
TO_DATE('2020-08-13', 'YYYY-MM-DD') AND
TO_DATE('2020-08-14', 'YYYY-MM-DD')
) AND
r.HotelID = 3;
To provide a list, besides data from the Reservations table, we also need a Clients table containing guest information, which can be found in this Google sheet.
This exercise is similar to the previous one, and so is the approach.
Get first row from IX_HotelID_DateFrom_ClientID where
HotelID = 3 and
DateFrom between '2020-08-13' and '2020-08-14'
While found and HotelID = 3 and DateFrom < '2020-08-15'
Fetch Clients.* where ClientID = IX_HotelID_DateFrom_ClientID.ClientID
Write down Clients.ClientName
Get next row from IX_HotelID_DateFrom_ClientID
The expression Fetch Clients.* where ClientID = IX_HotelID_DateFrom_ClientID.ClientID can be implemented by table scan or using our index. If we use a table scan, for each ClientID from the While loop, we would have to read on average the half of rows from the Clients table:
-- Get row from Clients using table scan
Repeat
Fetch next row from Clients
Until ClientID = IX_HotelID_DateFrom_ClientID.ClientID or not found
If found
Write down ClientName
The index implementation we’ve considered so far—let’s call it a “flat” index implementation—would not be too helpful. We would have to read the same number of rows (although smaller rows) from the index, then jump to the row in Clients using RowAddress:
-- Get row from Clients using flat index
Repeat
Fetch next row from Clients_PK_Flat
Until ClientID >= IX_HotelID_DateFrom_ClientID.ClientID
If found
Fetch Clients.* where rowAddress = Clients_PK_Flat.rowAddress
Write down ClientName
Note: Here, PK refers to “primary key,” a term we’ll explore later in the series.
Is there a way to accomplish this without having to read so many rows? Yes—this is exactly what B-tree indexes are for.
Balanced Tree (B-tree) Indexes
Let’s divide the rows from Clients_PK_Flat into four-row blocks and create a list containing the value of the last ClientID from the block and address of the block start (column IndexRowAddress). The resulting database index data structure—you can find in the Clients_PK_2Levels sheet. Try out how the new structure helps you find a client having a ClientID of 28. The algorithm should look like this:
Fetch Level2.*
Loop
Leaf_address := Level3Address
Exit when ClientID >= 28
Fetch next row from Level2
Fetch Level3.* where Level3Address = Leaf_address -- 3-21
Loop
Client_address := RowAddress
Exit when ClientID >= 28
Fetch next row from Level 3
Fetch Clients.* where rowAddress = Client_address -- 42
Write down Clients.*
You probably figured out that we can add another level. Level 1 consists of four rows, as you can see in IX_Clients_PK tab. To find the name of the guest with a ClientID of 28, you have to read three blocks (nodes) of data—one per level—from the primary key structure and finally jump to the Clients row with address 42.
The structure of this SQL index is called a balanced tree. The tree is balanced when the path from the root node to each leaf-level node has the same length, its so-called B-tree depth. In our case, the depth is three.
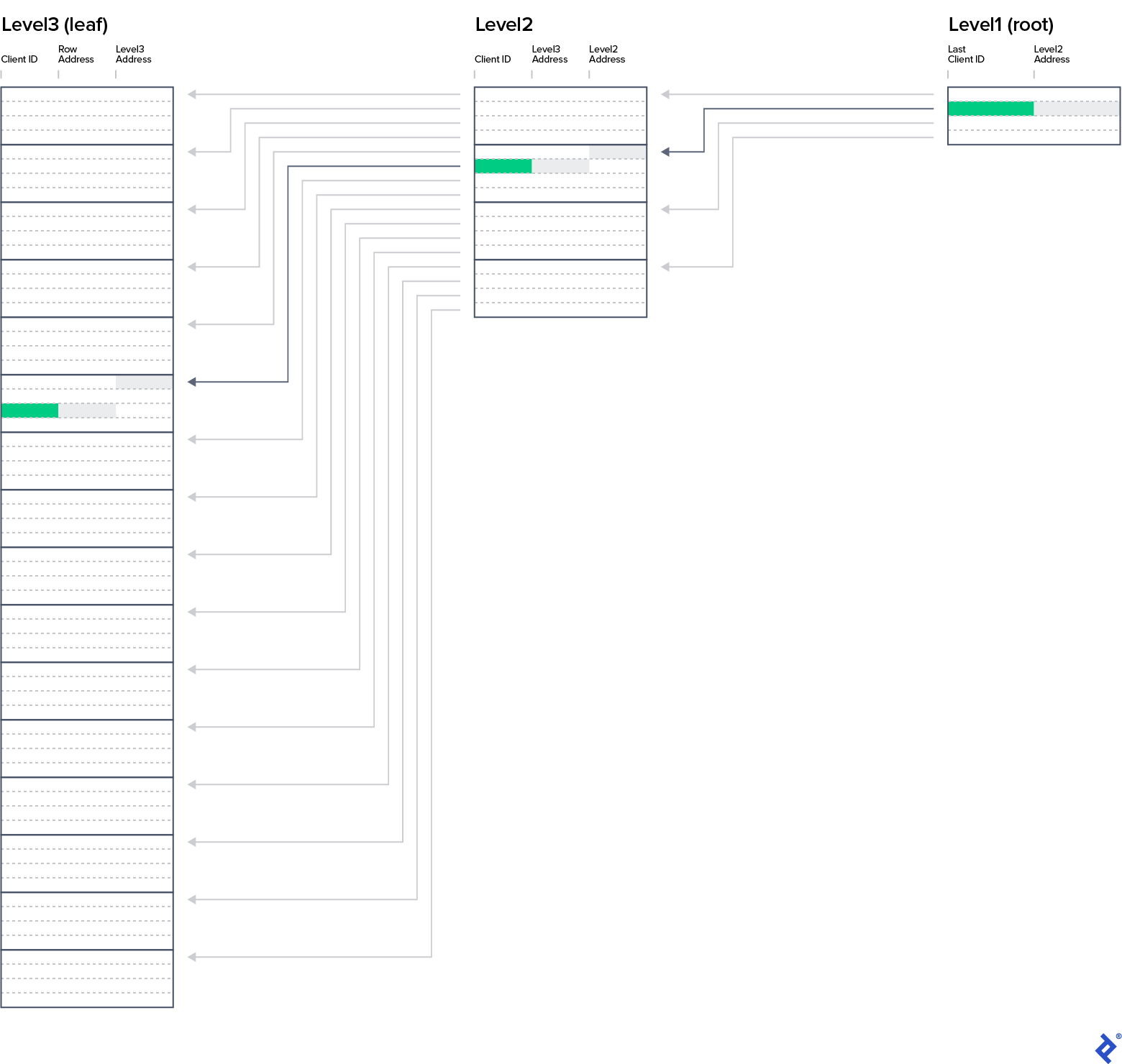
From now on, we’ll consider each index to have B-tree structure, even though our spreadsheets contain only leaf-level entries. The most important facts to know about B-tree are:
- The B-tree index structure is the most commonly used index by all major RDBMSs on the market.
- All levels of a balanced tree are ordered by key column values.
- Data are read from the disk in blocks.
- One B-tree node contains one or more blocks.
- The most important factor affecting query performance is the number of blocks read from the disk.
- The number of items in each new B-tree level, starting by root, ending on leaf level, increases exponentially.
Exercise 5: Criminal Investigation, Part II
Now, the police inspector is looking for a list of corresponding guests’ names, dates of arrival, and hotel names from all of the hotels in city A.
SELECT
h.HotelName,
r.DateFrom as CheckInDate,
c.ClientName
FROM Reservations r
JOIN Clients c ON r.ClientID = c.ClientID
JOIN Hotels h ON r.HotelID = h.HotelID
WHERE r.DateFrom BETWEEN (
TO_DATE('2020-08-13', 'YYYY-MM-DD') AND
TO_DATE('2020-08-14', 'YYYY-MM-DD')
) AND
h.City = 'A';
Approach 1
If we use the index IX_DateFrom_HotelID_ClientID, then for each row from the dates range, we would have to access the Hotels table and check if the hotel is from city A. If it is, we would have to access the Clients table, too, to read the client’s name.
For each row from IX_DateFrom_HotelID_ClientID where
DateFrom between '2020-08-13' and '2020-08-14'
For each row from Hotels where
HotelID = IX_DateFrom_HotelID_ClientID.HotelID
If Hotels.City = 'A' then
Fetch Clients.* where ClientID = IX_HotelID_DateFrom_ClientID.ClientID
Write down
Hotels.HotelName,
IX_HotelID_DateFrom_ClientID.DateFrom,
Clients.ClientName
Approach 2
Using IX_HotelID_DateFrom_ClientID gives us a more efficient execution plan.
For each row from Hotels where City = 'A'
For each row from IX_HotelID_DateFrom_ClientID where
HotelID = Hotels.HotelID and
DateFrom between '2020-08-13' and '2020-08-14'
Fetch Clients.* where ClientID = IX_HotelID_DateFrom_ClientID.ClientID
Write down
Hotels.HotelName,
IX_HotelID_DateFrom_ClientID.DateFrom,
Clients.ClientName
From the Hotels table, we find all the hotels from city A. Knowing the ID of these hotels, we can read subsequent items from the IX_HotelID_DateFrom_ClientID index. This way, after finding the first row in the B-tree leaf level for each hotel and date, we don’t read the reservations from hotels outside city A.

Here, we can see that when we have a database index that’s appropriate for our goals, an additional join can actually make a query faster.
The B-tree structure and how it is updated whenever a row is inserted, updated, or deleted will be addressed in more detail when I explain the motivation for partitioning and its impact. The point is that we can consider this operation quick whenever we use an index.
The Index Query in SQL: Details Make All the Difference
When it comes to indexes and databases, working at the SQL language level hides implementation details to some extent. These exercises are meant to help you get a feel for how execution plans work when using different SQL indexes. After reading the article, I hope you will be able to guess the best execution plan given available indexes and design indexes that would make a query as fast and efficient as possible.
In the next part of this series, we will use and expand newly acquired skills to investigate and understand the most common best practices and anti-patterns in the use of indexes in SQL. I have a list of good and best practices I want to address in the next part, but to make the next article more relevant to your needs and experience, please feel free to post your own questions you would like to see answered.
In the final part of SQL Indexes Explained, we will also learn about table and index partitioning, the right and wrong motivations for using it, and its impact on query performance and database maintenance.
Further Reading on the Toptal Blog:
Understanding the basics
A table in SQL is a database object that contains data organized in rows and columns. It is similar to a spreadsheet in that regard. Each row represents a record consisting of column values. The table definition includes the name and data type of each column and constraints applicable to table data.
SQL tables can have indexes associated with them. The role of indexes is to support fast data retrieval. In addition to that, indexes are also used to enforce unique key constraints and to speed up foreign key constraint evaluation.
Prague, Czech Republic
Member since March 2, 2020
About the author
Mirko designs and develops massive, extreme-workload databases. He also trains software developers on databases and SQL.