
Twitter Data Mining: A Guide to Big Data Analytics Using Python
Twitter is a goldmine of data. Unlike other social platforms, almost every user’s tweets are completely public and pullable.
In this tutorial, Toptal Freelance Software Engineer Anthony Sistilli will be exploring how you can use Python, the Twitter API, and data mining techniques to gather useful data.

Twitter is a goldmine of data. Unlike other social platforms, almost every user’s tweets are completely public and pullable.
In this tutorial, Toptal Freelance Software Engineer Anthony Sistilli will be exploring how you can use Python, the Twitter API, and data mining techniques to gather useful data.

With four years of experience, Anthony specializes in machine learning and artificial intelligence as an engineer and a researcher.
Previously At

Big data is everywhere. Period. In the process of running a successful business in today’s day and age, you’re likely going to run into it whether you like it or not.
Whether you’re a businessman trying to catch up to the times or a coding prodigy looking for their next project, this tutorial will give you a brief overview of what big data is. You will learn how it’s applicable to you, and how you can get started quickly through the Twitter API and Python.

What Is Big Data?
Big data is exactly what it sounds like—a lot of data. Alone, a single point of data can’t give you much insight. But terabytes of data, combined together with complex mathematical models and boisterous computing power, can create insights human beings aren’t capable of producing. The value that big data Analytics provides to a business is intangible and surpassing human capabilities each and every day.
The first step to big data analytics is gathering the data itself. This is known as “data mining.” Data can come from anywhere. Most businesses deal with gigabytes of user, product, and location data. In this tutorial, we’ll be exploring how we can use data mining techniques to gather Twitter data, which can be more useful than you might think.
For example, let’s say you run Facebook, and want to use Messenger data to provide insights on how you can advertise to your audience better. Messenger has 1.2 billion monthly active users. In this case, the big data are conversations between users. If you were to individually read the conversations of each user, you would be able to get a good sense of what they like, and be able to recommend products to them accordingly. Using a machine learning technique known as Natural Language Processing (NLP), you can do this on a large scale with the entire process automated and left up to machines.
This is just one of the countless examples of how machine learning and big data analytics can add value to your company.
Why Twitter data?
Twitter is a gold mine of data. Unlike other social platforms, almost every user’s tweets are completely public and pullable. This is a huge plus if you’re trying to get a large amount of data to run analytics on. Twitter data is also pretty specific. Twitter’s API allows you to do complex queries like pulling every tweet about a certain topic within the last twenty minutes, or pull a certain user’s non-retweeted tweets.
A simple application of this could be analyzing how your company is received in the general public. You could collect the last 2,000 tweets that mention your company (or any term you like), and run a sentiment analysis algorithm over it.
We can also target users that specifically live in a certain location, which is known as spatial data. Another application of this could be to map the areas on the globe where your company has been mentioned the most.
As you can see, Twitter data can be a large door into the insights of the general public, and how they receive a topic. That, combined with the openness and the generous rate limiting of Twitter’s API, can produce powerful results.
Tools Overview
We’ll be using Python 2.7 for these examples. Ideally, you should have an IDE to write this code in. I will be using PyCharm - Community Edition.
To connect to Twitter’s API, we will be using a Python library called Tweepy, which we’ll install in a bit.
Getting Started
Twitter Developer Account
In order to use Twitter’s API, we have to create a developer account on the Twitter apps site.
- Log in or make a Twitter account at https://apps.twitter.com/.
- Create a new app (button on the top right)

- Fill in the app creation page with a unique name, a website name (use a placeholder website if you don’t have one), and a project description. Accept the terms and conditions and proceed to the next page.
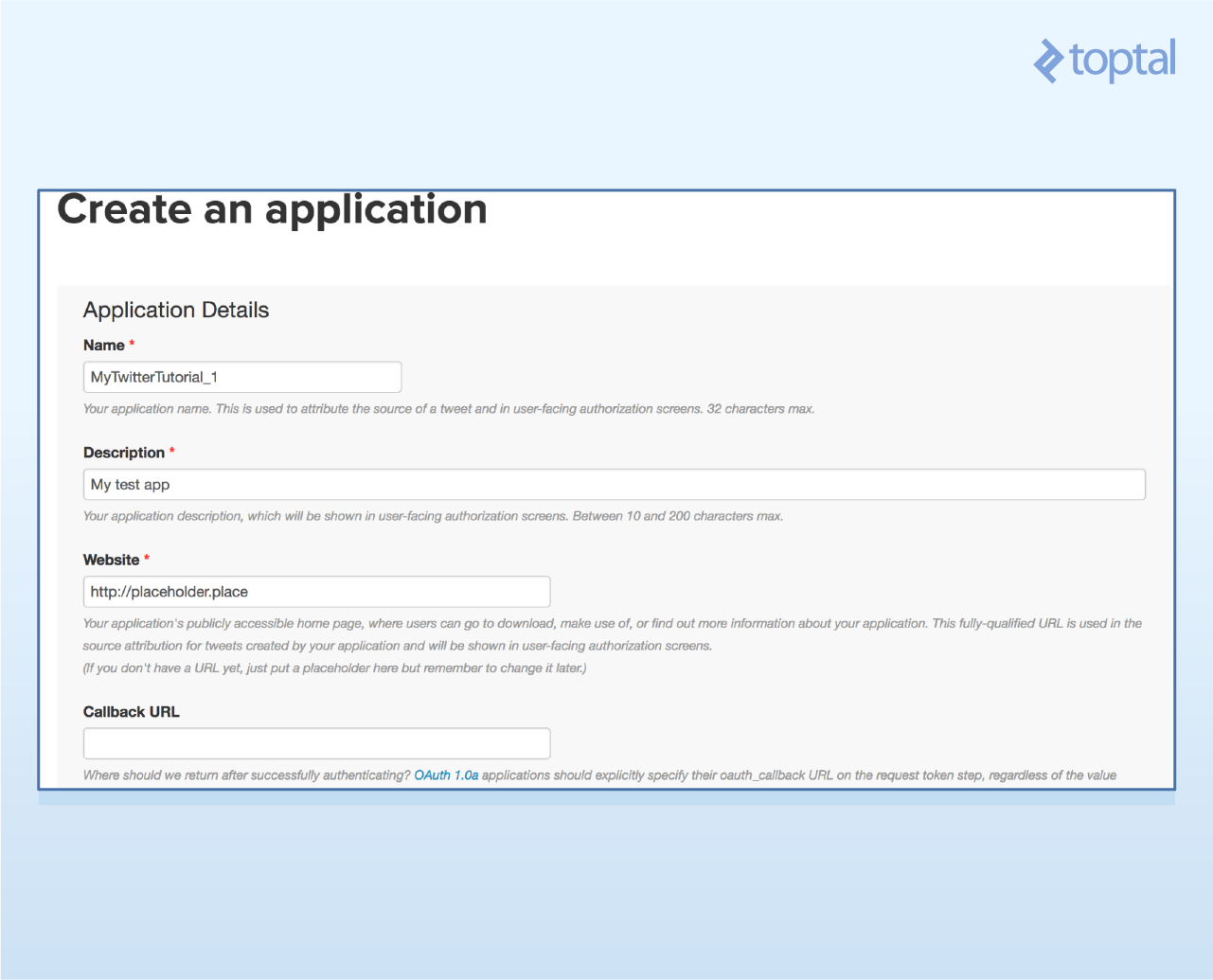
- Once your project has been created, click on the “Keys and Access Tokens” tab. You should now be able to see your consumer secret and consumer key.
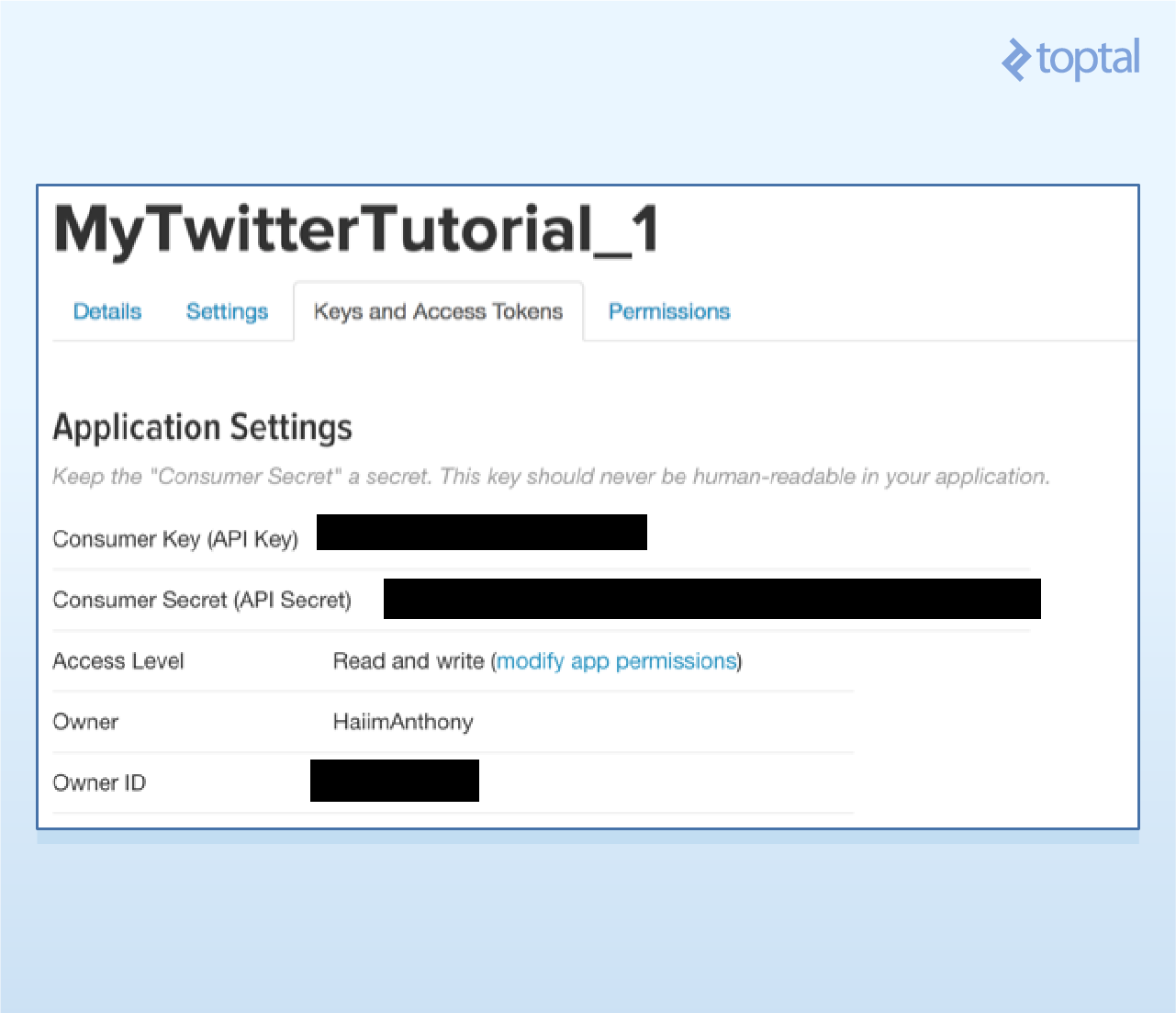
- You’ll also need a pair of access tokens. Scroll down and request those tokens. The page should refresh, and you should now have an access token and access token secret.





We’ll need all of these later, so make sure you keep this tab open.
Installing Tweepy
Tweepy is an excellently supported tool for accessing the Twitter API. It supports Python 2.6, 2.7, 3.3, 3.4, 3.5, and 3.6. There are a couple of different ways to install Tweepy. The easiest way is using pip.
Using Pip
Simply type pip install tweepy into your terminal.
Using GitHub
You can follow the instructions on Tweepy’s GitHub repository. The basic steps are as follows:
git clone https://github.com/tweepy/tweepy.git
cd tweepy
python setup.py install
You can troubleshoot any installation issues there as well.
Authenticating
Now that we have the necessary tools ready, we can start coding! The baseline of each application we’ll build today requires using Tweepy to create an API object which we can call functions with. In order create the API object, however, we must first authenticate ourselves with our developer information.
First, let’s import Tweepy and add our own authentication information.
import tweepy
consumer_key = "wXXXXXXXXXXXXXXXXXXXXXXX1"
consumer_secret = "qXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXh"
access_token = "9XXXXXXXX-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXi"
access_token_secret = "kXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXT"
Now it’s time to create our API object.
# Creating the authentication object
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
# Setting your access token and secret
auth.set_access_token(access_token, access_token_secret)
# Creating the API object while passing in auth information
api = tweepy.API(auth)
This will be the basis of every application we build, so make sure you don’t delete it.
Example 1: Your Timeline
In this example, we’ll be pulling the ten most recent tweets from your Twitter feed. We’ll do this by using the API object’s home_timeline() function. We can then store the result in a variable, and loop through it to print the results.
# Using the API object to get tweets from your timeline, and storing it in a variable called public_tweets
public_tweets = api.home_timeline()
# foreach through all tweets pulled
for tweet in public_tweets:
# printing the text stored inside the tweet object
print tweet.text
The result should look like a bunch of random tweets, followed by the URL to the tweet itself.

Following the link to the tweet will often bring you to the tweet itself. Following the link from the first tweet would give us the following result:

Note that if you’re running this through terminal and not an IDE like PyCharm, you might have some formatting issues when attempting to print the tweet’s text.
The JSON behind the Results
In the example above, we printed the text from each tweet using tweet.text. To refer to specific attributes of each tweet object, we have to look at the JSON returned by the Twitter API.
The result you receive from the Twitter API is in a JSON format, and has quite an amount of information attached. For simplicity, this tutorial mainly focuses on the “text” attribute of each tweet, and information about the tweeter (the user that created the tweet). For the above sample, you can see the entire returned JSON object here.
Here’s a quick look at some attributes a tweet has to offer.

If you wanted to find the date the the tweet was created, you would query it with print tweet.created_at.
You can also see that each tweet object comes with information about the tweeter.

To get the “name” and “location” attribute of the tweeter, you could run print tweet.user.screen_name and print tweet.user.location.
Note that these attributes can be extremely useful if your application depends on spatial data.
Example 2: Tweets from a Specific User
In this example, we’ll simply pull the latest twenty tweets from a user of our choice.
First, we’ll examine the Tweepy documentation to see if a function like that exists. With a bit of research, we find that the user_timeline() function is what we’re looking for.

We can see that the user_timeline() function has some useful parameters we can use, specifically id (the ID of the user) and count (the amount of tweets we want to pull). Note that we can only pull a limited number of tweets per query due to Twitter’s rate limits.
Let’s try pulling the latest twenty tweets from twitter account @NyTimes.

We can create variables to store the amount of tweets we want to pull (count), and the user we want to pull them from (name). We can then call the user_timeline function with those two parameters. Below is the updated code (note that you should have kept the authentication and API object creation at the top of your code).
# Creating the API object while passing in auth information
api = tweepy.API(auth)
# The Twitter user who we want to get tweets from
name = "nytimes"
# Number of tweets to pull
tweetCount = 20
# Calling the user_timeline function with our parameters
results = api.user_timeline(id=name, count=tweetCount)
# foreach through all tweets pulled
for tweet in results:
# printing the text stored inside the tweet object
print tweet.text
Our results should look something like this:

Popular applications of this type of data can include:
- Running analysis on specific users, and how they interact with the world
- Finding Twitter influencers and analyzing their follower trends and interactions
- Monitoring the changes in the followers of a user
Example 3: Finding Tweets Using a Keyword
Let’s do one last example: Getting the most recent tweets that contain a keyword. This can be extremely useful if you want to monitor specifically mentioned topics in the Twitter world, or even to see how your business is getting mentioned. Let’s say we want to see how Twitter’s been mentioning Toptal.
After looking through the Tweepy documentation, the search() function seems to be the best tool to accomplish our goal.

The most important parameter here is q—the query parameter, which is the keyword we’re searching for.
We can also set the language parameter so we don’t get any tweets from an unwanted language. Let’s only return English (“en”) tweets.
We can now modify our code to reflect the changes we want to make. We first create variables to store our parameters (query and language), and then call the function via the API object. Let’s also print the screen name, of the user that created the tweet, in our loop.
# Creating the API object while passing in auth information
api = tweepy.API(auth)
# The search term you want to find
query = "Toptal"
# Language code (follows ISO 639-1 standards)
language = "en"
# Calling the user_timeline function with our parameters
results = api.search(q=query, lang=language)
# foreach through all tweets pulled
for tweet in results:
# printing the text stored inside the tweet object
print tweet.user.screen_name,"Tweeted:",tweet.text
Our results should look something like this:

Here are some practical ways you can use this information:
- Create a spatial graph on where your company is mentioned the most around the world
- Run sentiment analysis on tweets to see if the overall opinion of your company is positive or negative
- Create a social graphs of the most popular users that tweet about your company or product
We can cover some of these topics in future articles.
Conclusion
Twitter’s API is immensely useful in data mining applications, and can provide vast insights into the public opinion. If the Twitter API and big data analytics is something you have further interest in, I encourage you to read more about the Twitter API, Tweepy, and Twitter’s Rate Limiting guidelines.
We covered only the basics of accessing and pulling. Twitter’s API can be leveraged in very complex big data problems, involving people, trends, and social graphs too complicated for the human mind to grasp alone.
Further Reading on the Toptal Blog:
Understanding the basics
Data mining is the task of pulling a huge amount of data from a source and storing it. The result of this is “big data,” which is just a large amount of data in one place.
Twitter data is open, personal, and extensive. You can extract quite a bit from a user by analyzing their tweets and trends. You can also see how people are talking specific topics using keywords and business names.
For an organization, big data analytics can provide insights that surpass human capability. Being able to run large amounts of data through computation-heavy analysis is something mathematical models and machines thrive at.
Anthony Sistilli
Toronto, ON, Canada
Member since April 22, 2017
About the author
With four years of experience, Anthony specializes in machine learning and artificial intelligence as an engineer and a researcher.
PREVIOUSLY AT