
A Deep Dive Into NgRx Advantages and Features
NgRx is a popular Angular state management library, but to unlock its full potential developers may require a few new skills.
In this article, Toptal Full-stack Developer Luka Onikadze explains why he became an NgRx admirer after starting off as a skeptic.

NgRx is a popular Angular state management library, but to unlock its full potential developers may require a few new skills.
In this article, Toptal Full-stack Developer Luka Onikadze explains why he became an NgRx admirer after starting off as a skeptic.

With solid full-stack experience, Luka is currently working as a front-end team lead and developer, specializing in Node.js, Angular, and JavaScript.
Expertise
If a team lead instructs a developer to write a lot of boilerplate code instead of writing a few methods to solve a certain problem, they need convincing arguments. Software engineers are problem solvers; they prefer to automate things and avoid unnecessary boilerplate.
Even though NgRx comes with some boilerplate code, it also provides powerful tools for development. This article demonstrates that spending a bit more time writing code will yield benefits that make it worth the effort.
Most developers started using state management when Dan Abramov released the Redux library. Some started using state management because it was a trend, not because they lacked it. Developers using a standard “Hello World” project for state management could quickly find themselves writing the same code over and over again, increasing complexity for no gain.
Eventually, some became frustrated and abandoned state management entirely.
My Initial Problem With NgRx
I think this boilerplate concern was a major issue with NgRx. At first, we weren’t able to see the big picture behind it. NgRx is a library, not a programming paradigm or a mindset. However, in order to fully grasp the functionality and usability of this library, we have to expand our knowledge a bit more and focus on functional programming. That’s when you might get to write boilerplate code and feel happy about it. (I mean it.) I was once an NgRx skeptic; now I’m an NgRx admirer.
A while ago, I started using state management. I went through the boilerplate experience described above, so I decided to stop using the library. Since I love JavaScript, I try to attain at least a fundamental knowledge about all popular frameworks in use today. Here’s what I learned while using React.
React has a feature called Hooks. Much like Components in Angular, Hooks are built on simple functions that accept arguments and return values. Hooks allow us to manage state and handle side effects within those functions. So, for example, a simple button in Angular could be translated into React like this:
@Component({
selector: 'simple-button',
template: ` <button>Hello {{ name }}</button> `,
})
export class SimpleButtonComponent {
@Input()
name!: string;
}
export default function SimpleButton(props: { name: string }) {
return <button>{props.name} </button>;
}
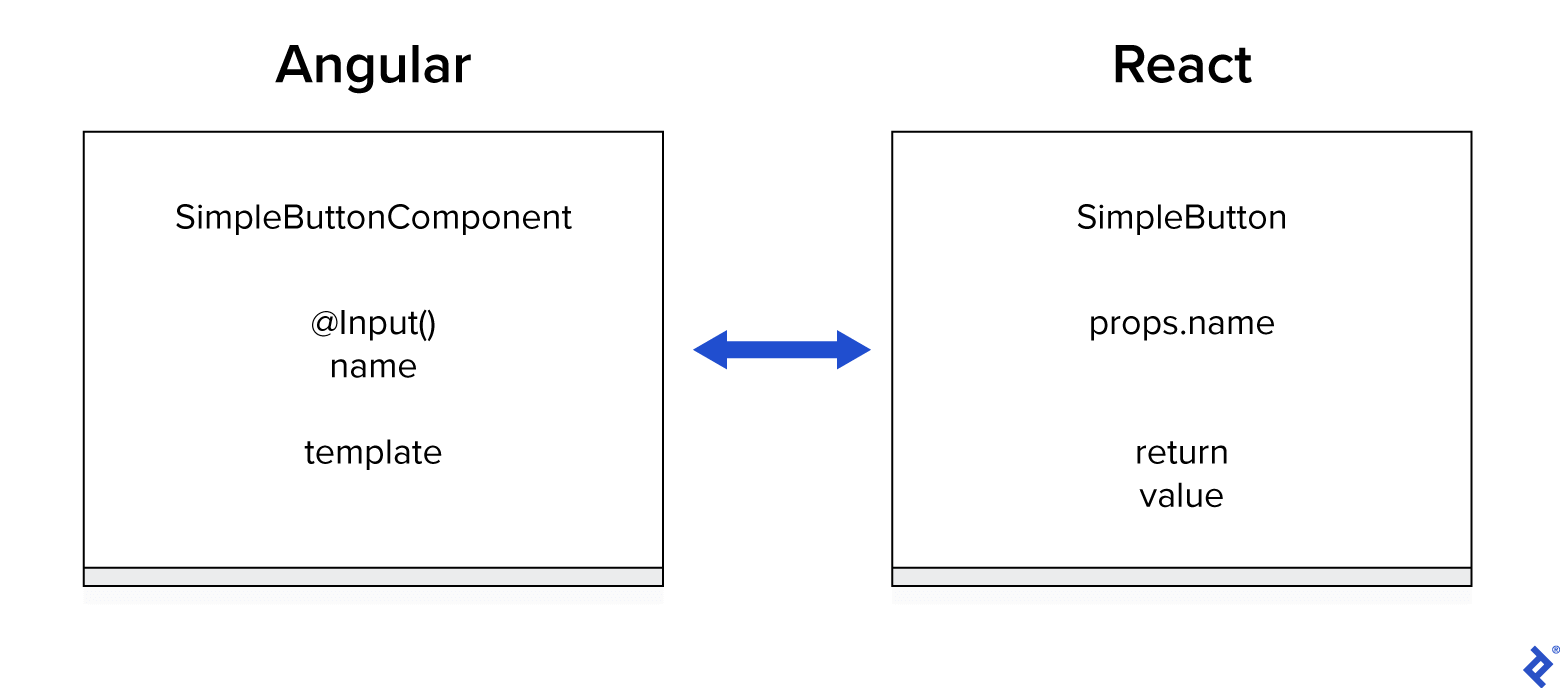
As you can see, this is a straightforward transformation:
- SimpleButtonComponent => SimpleButton
- @Input() name => props.name
- template => return value
Our React function SimpleButton has one important characteristic in the functional programming world: It is a pure function. If you are reading this, I presume that you have heard that term at least once. NgRx.io cites pure functions twice in the Key Concepts:
- State changes are handled by pure functions called
reducersthat take the current state and the latest action to compute a new state. - Selectors are pure functions used to select, derive, and compose pieces of state.
In React, developers are encouraged to use Hooks as pure functions as much as possible. Angular also encourages developers to implement the same pattern using the Smart-Dumb Component paradigm.
That’s when I realized that I lacked some crucial functional programming skills. It did not take long to grasp NgRx, as after learning the key concepts of functional programming, I had an “Aha! moment”: I had improved my understanding of NgRx and wanted to use it more to better understand the benefits it offers.
This article shares my learning experience and the knowledge I gained about NgRx and functional programming. I do not explain the API for NgRx or how to call actions or use selectors. Instead, I share why I’ve come to appreciate that NgRx is a great library: It’s not just a relatively new trend, it provides a host of benefits.
Let’s start with functional programming.
Functional Programming
Functional programming is a paradigm that differs greatly from other paradigms. This is a very complex topic with many definitions and guidelines. However, functional programming contains some core concepts and knowing them is a prerequisite for mastering NgRx (and JavaScript in general).
These core concepts are:
- Pure Function
- Immutable State
- Side Effect
I repeat: It’s just a paradigm, nothing more. There is no library functional.js that we download and use to write functional software. It’s just a way of thinking about writing applications. Let’s start with the most important core concept: pure function.
Pure Function
A function is considered a pure function if it follows two simple rules:
- Passing the same arguments always returns the same value
- Lacking an observable side effect involved inside function execution (an external state change, calling I/O operation, etc.)
So a pure function is just a transparent function that accepts some arguments (or no arguments at all) and returns an expected value. You are assured that calling this function will not result in side effects, like networking or changing some global user state.
Let’s take a look at three simple examples:
//Pure function
function add(a,b){
return a + b;
}
//Impure function breaking rule 1
function random(){
return Math.random();
}
//Impure function breaking rule 2
function sayHello(name){
console.log("Hello " + name);
}
- The first function is pure because it will always return the same answer when passing the same arguments.
- The second function is not pure because it is nondeterministic and returns different answers every time it is called.
- The third function is not pure because it uses a side effect (calling
console.log).
It is easy to discern if the function is pure or not. Why is a pure function better than impure one? Because it is simpler to think about. Imagine you are reading some source code and see a function call that you know is pure. If the function name is right, you don’t need to explore it; you know that it doesn’t change anything, it returns what you expect. It’s crucial for debugging when you have a huge enterprise application with a lot of business logic, as it can be a huge timesaver.
Also, it’s simple to test. You don’t have to inject anything or mock some functions inside it, you just pass arguments and test if the result is a match. There is a strong connection between the test and logic: If a component is easy to test, it is easy to understand how and why it works.
Pure functions come with a very handy and performance-friendly functionality called memoization. If we know that calling the same arguments will return the same value then we can simply cache the results and not waste time calling it again. NgRx definitely sits on top of memoization; that’s one of the main reasons why it is fast.

You may ask yourself, “What about side effects? Where do they go?” In his GOTO talk, Russ Olsen jokes that our clients don’t pay us for pure functions, they pay us for side effects. That’s true: Nobody cares about the Calculator pure function if it doesn’t get printed somewhere. Side effects have their place in the functional programming universe. We will see that shortly.
For now, let’s move to the next step in maintaining complex application architectures, the next core concept: immutable state.
Immutable State
There is a simple definition for an immutable state:
- You can only create or delete a state. You can’t update it.
In simple terms, to update a User object’s age … :
let user = { username:"admin", age:28 }
… you should write it like this:
// Not like this
newUser.age = 30;
// But like this
let newUser = {...user, age:29 }
Every change is a new object that has copied properties from the old ones. As such, we are already in a form of immutable state.
String, Boolean, and Number all are immutable states: You can’t append or modify existing values. In contrast, a Date is a mutable object: You always manipulate the same date object.
Immutability applies across the application: If you pass a user object inside the function that changes its age, it should not change a user object, it should create a new user object with an updated age and return it:
function updateAge(user, age) {
return { ...user, age: age };
}
let user = { username: 'admin', age: 29 };
let newUser = updateAge(user, 32);
Why should we devote time and attention to this? There are a couple of benefits worth underscoring.
One benefit for back-end programming languages involves parallel processing. If a state change doesn’t depend on a reference and every update is a new object, you can split the process into chunks and work on the same task with countless threads without sharing the same memory. You can even parallelize tasks across servers.
For frameworks such as Angular and React, parallel processing is one of the more beneficial ways of improving application performance. For example, Angular has to check every object’s properties that you pass via Input bindings to discern if a component has to be rerendered or not. But if we set ChangeDetectionStrategy.OnPush instead of the default, it will check by reference and not by each property. In a large application, this definitely saves time. If we update our state immutably, we get this performance boost for free.
The other benefit for an immutable state that all programming languages and frameworks share is similar to the benefits of pure functions: It’s easier to think about and test. When a change is a new state born from an old one, you know exactly what you are working on and you can track exactly how and where the state changed. You don’t lose the update history and you can undo/redo changes for the state (React DevTools is one example).
However, if a single state gets updated, you won’t know the history of those changes. Think of an immutable state like the transaction history for a bank account. It’s practically a must-have.
Now that we’ve reviewed immutability and pureness, let’s tackle the remaining core concept: side effect.
Side Effect
We can generalize the definition of a side effect:
- In computer science, an operation, function, or expression is said to have a side effect if it modifies some state variable value(s) outside its local environment. That is to say it has an observable effect besides returning a value (the main effect) to the invoker of the operation.
Simply put, everything that changes a state outside the function scope—all the I/O operations and some work that is not directly connected to the function—can be considered a side effect. However, we have to avoid using side effects inside pure functions because side effects contradict functional programming philosophy. If you use an I/O operation inside a pure function, then it ceases to be a pure function.
Nevertheless, we need to have side effects somewhere, as an application without them would be pointless. In Angular, not only do pure functions need to be protected against side effects, we have to avoid using them in Components and Directives as well.
Let’s examine how we can implement the beauty of this technique inside the Angular framework.
Functional Angular Programming
One of the first things to understand about Angular is the need to decouple components into smaller components as often as possible to enable easier maintenance and testing. This is necessary, as we need to divide our business logic. Also, Angular developers are encouraged to leave components only for rendering purposes and move all the business logic inside the services.
To expand on these concepts, Angular users added the “Dumb-Smart Component” pattern to their vocabulary. This pattern requires that service calls do not exist inside the small components. Because business logic resides in services, we still have to call these service methods, wait for their response, and only then make any state changes. So, components have some behavioral logic inside them.
To avoid that, we can create one Smart Component (Root Component), which contains business and behavior logic, pass the states via Input Properties, and call actions listening to Output parameters. This way, the small components are truly only for rendering purposes. Of course, our Root Component has to have some service calls inside it and we can’t just remove them but its utility would be limited to business logic only, not rendering.
Let’s look at a Counter Component example. A counter is a component that has two buttons that increase or decrease value, and one displayField that displays the currentValue. So we end up with four components:
- CounterContainer
- IncreaseButton
- DecreaseButton
- CurrentValue
All the logic lives inside the CounterContainer, so all three are just renderers. Here’s the code for the three of them:
@Component({
selector: 'decrease-button',
template: `<button (click)="decrease.emit()" [disabled]="disabled">
Decrease
</button>`,
})
export class DecreaseButtonComponent {
@Input()
disabled!: boolean;
@Output()
decrease = new EventEmitter();
}
@Component({
selector: 'current-value',
template: `<button>
{{ currentValue }}
</button>`,
})
export class CurrentValueComponent {
@Input()
currentValue!: string;
}
@Component({
selector: 'increase-button',
template: `<button (click)="increase.emit()" [disabled]="disabled">
Increase
</button>`,
})
export class IncreaseButtonComponent {
@Input()
disabled!: boolean;
@Output()
increase = new EventEmitter();
}
Look how simple and pure they are. They have no state or side effects, they just depend on input properties and emitting events. Imagine how easy it is to test them. We can call them pure components as that’s what they truly are. They depend only on input parameters, have no side effects, and always return the same value (template string) by passing the same parameters.
So pure functions in functional programming are transferred into the pure components in Angular. But where does all the logic go? The logic is still there but in a slightly different place, namely the CounterComponent.
@Component({
selector: 'counter-container',
template: `
<decrease-button [disabled]="decreaseIsDisabled" (decrease)="decrease()">
</decrease-button>
<current-value [currentValue]="currentValue"> </current-value>
<increase-button (increase)="increase()" [disabled]="increaseIsDisabled">
</increase-button>
`,
})
export class CounterContainerComponent implements OnInit {
@Input()
disabled!: boolean;
currentValue = 0;
get decreaseIsDisabled() {
return this.currentValue === 0;
}
get increaseIsDisabled() {
return this.currentValue === 100;
}
constructor() {}
ngOnInit(): void {}
decrease() {
this.currentValue -= 1;
}
increase() {
this.currentValue += 1;
}
}
As you can see, the behavior logic lives in CounterContainer but the rendering part is missing (it declares components inside the template) because the rendering part is for pure components.
We could inject as much service as we want because we handle all data manipulations and state changes here. One thing worth mentioning is that if we have a deep nested component, we must not create only one root-level component. We can divide it into smaller smart components and use the same pattern. Ultimately, it depends on the complexity and nested level for each component.
We can easily jump from that pattern into the NgRx library itself, which is just one layer above it.
NgRx Library
We can divide any web application into three core parts:
- Business Logic
- Application State
- Rendering Logic
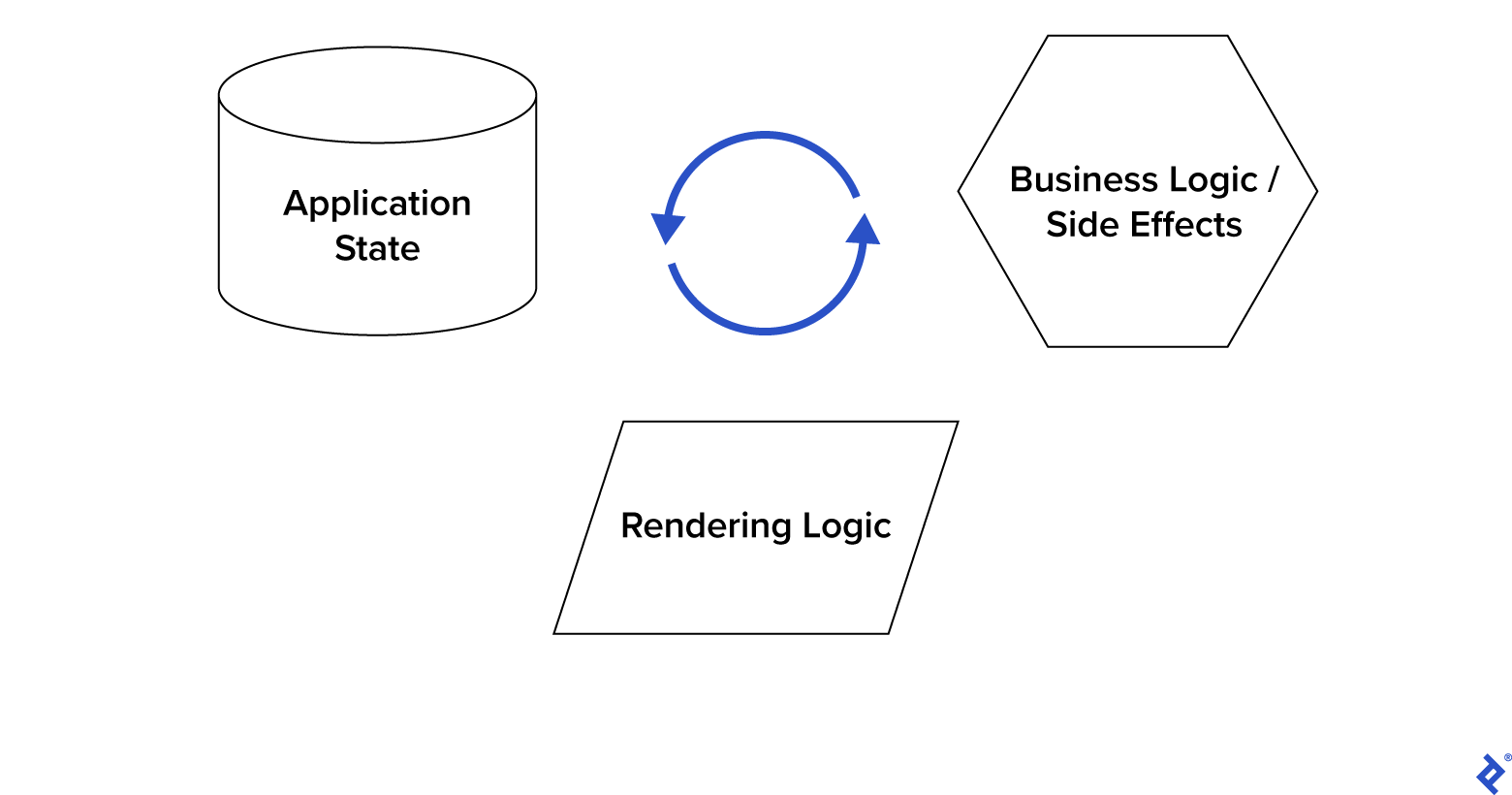
Business Logic is all the behavior that is happening to the application, such as networking, input, output, API, etc.
Application State is the state of the application. It can be global, as the currently authorized user, and also local, as the current Counter Component value.
Rendering Logic encompasses rendering, like displaying data using DOM, creating or removing elements, and so on.
By using the Dumb-Smart pattern we decoupled Rendering Logic from Business Logic and Application State but we can divide them too because they are both conceptually different from each other. Application State is like a snapshot of your app in current time. Business Logic is like a static functionality that’s always present in your app. The most important reason to divide them is that Business Logic is mostly a side effect that we want to avoid in application code as much as possible. This is when the NgRx library, with its functional paradigm, shines.
With NgRx you decouple all these parts. There are three main parts:
- Reducers
- Actions
- Selectors
Combined with functional programming, all three combine to give us a powerful tool to handle applications of any size. Let’s examine each of them.
Reducers
A reducer is a pure function, which has a simple signature. It takes an old state as a parameter and returns a new state, either derived from the old one or a new one. The state itself is a single object, which lives with your application’s lifecycle. It’s like an HTML tag, a single root object.
You cannot directly modify a state object, you need to modify it with reducers. That has a number of benefits:
- The change state logic lives in a single place, and you know where and how the state changes.
- The reducer functions are pure functions, which are easy to test and manage.
- Because reducers are pure functions, they can be memoized, making it possible to cache them and avoid extra computation.
- State changes are immutable. You never update the same instance. Instead, you always return a new one. This enables a “time travel” debugging experience.
This is a trivial example of a reducer:
function usernameReducer(oldState, username) {
return {...oldState, username}
}
Even though it’s a very simple dummy reducer, it is the skeleton for all long and complex reducers. They all share the same benefits. We could have hundreds of reducers in our application and we can make as many as we want.
For our Counter Component, our state and reducers could look like this:
interface CounterState {
decreaseDisabled: boolean;
increaseDisabled: boolean;
currentValue: number;
}
const MIN_VALUE=0;
const MAX_VALUE =100;
function decreaseReducer(oldState: CounterState): CounterState {
const newValue = oldState.currentValue - 1;
return { ...oldState, currentValue: newValue, decreaseDisabled: newValue === MIN_VALUE };
}
function increaseReducer(oldState: CounterState): CounterState {
const newValue = oldState.currentValue + 1;
return { ...oldState, currentValue: newValue, increaseDisabled: newValue === MAX_VALUE };
}
We removed the state from the component. Now we need a way to update our state and call the appropriate reducer. That’s when actions come into play.
Actions
An action is a way to notify NgRx to call a reducer and update the state. Without that, it would be meaningless to use NgRx. An action is a simple object that we attach to the current reducer. After calling it, the appropriate reducer will be called, so in our example then we could have the following actions:
enum CounterActions {
IncreaseValue = '[Counter Component] Increase Value',
DecreaseValue = '[Counter Component] Decrease Value',
}
on(CounterActions.IncreaseValue,increaseReducer);
on(CounterActions.DecreaseValue,decreaseReducer);
Our actions are attached to the reducers. Now we can modify our Container Component further and call appropriate actions when necessary:
@Component({
selector: 'counter-container',
template: `
<decrease-button [disabled]="decreaseIsDisabled" (decrease)="decrease()">
</decrease-button>
<current-value [currentValue]="currentValue"> </current-value>
<increase-button (increase)="increase()" [disabled]="increaseIsDisabled">
</increase-button>
`,
})
export class CounterContainerComponent implements OnInit {
Note: We removed the state and we will add back shortly.
Now our CounterContainer doesn’t have any state change logic. It just knows what to dispatch. Now we need some way of displaying this data to the view. That’s the utility of selectors.
Selectors
A selector is also a very simple pure function, but unlike a reducer, it doesn’t update the state. As the name implies, the selector merely selects it. In our example, we could have three simple selectors:
function selectCurrentValue(state: CounterState): number {
return state.currentValue;
}
function selectDecreaseIsDisabled(state: CounterState): boolean {
return state.decreaseDisabled;
}
function selectIncreaseIsDisabled(state: CounterState): boolean {
return state.increaseDisabled;
}
Using these selectors, we could select each slice of a state inside our smart CounterContainer component.
@Component({
selector: 'counter-container',
template: `
<decrease-button
[disabled]="decreaseIsDisabled$ | async"
(decrease)="decrease()"
>
</decrease-button>
<current-value [currentValue]="currentValue$ | async"> </current-value>
<increase-button
(increase)="increase()"
[disabled]="increaseIsDisabled$ | async"
>
</increase-button>
`,
})
export class CounterContainerComponent implements OnInit {
decreaseIsDisabled$ = this.store.select(selectDecreaseIsDisabled);
increaseIsDisabled$ = this.store.select(selectIncreaseIsDisabled);
currentValue$ = this.store.select(selectCurrentValue);
constructor(private store: Store<CounterState>) {}
decrease() {
this.store.dispatch(CounterActions.DecreaseValue);
}
increase() {
this.store.dispatch(CounterActions.IncreaseValue);
}
}
In modern Angular applications, this pattern may also be implemented using Signals, which provide synchronous state access without relying on Observables, though from a pattern point of view, this distinction is not especially important, as we are still selecting a slice of state.
Let’s step back and look at the big picture to see what we’ve achieved thus far. We have a Counter Application, which has three main parts that are almost decoupled from each other. Nobody knows how the application state is managing itself or how the rendering layer renders the state.
The decoupled parts use the bridge (Actions, Selectors) to connect to each other. They are decoupled to such an extent that we could take the whole State Application code and move it to another project, like for a mobile version for example. The only thing we would have to implement would be the rendering. But what about testing?
In my humble opinion, testing is the best part of NgRx. Testing this sample project is akin to playing tic-tac-toe. There are only pure functions and pure components, so testing them is a breeze. Now imagine if this project becomes larger, with hundreds of components. If we follow the same pattern, we would just add more and more pieces together. It would not become a messy, unreadable blob of source code.
We’re almost done. There’s only one important thing left to cover: side effects. I mentioned side effects many times so far but I stopped short of explaining where to store them.
That’s because side effects are the icing on the cake and by building this pattern, it’s very easy to remove them from the application code.
Angular Signals and Modern NgRx
Up to this point, we’ve looked at NgRx through the lens of reducers, actions, and selectors. That model is still widely used, but Angular itself has evolved in recent years.
Since Angular 16, the framework has introduced Signals, a new reactive primitive that offers a different way to think about state. By Angular 18 and beyond, Signals have become a common alternative to RxJS-based patterns, especially for local or feature-level state.
The key difference is in how reactivity is expressed. Instead of working with asynchronous streams and subscriptions, Signals provide a more direct and synchronous model. A value can be read at any time, and Angular tracks dependencies automatically, updating only what needs to change.
NgRx has adapted to this shift without abandoning its core ideas.
NgRx SignalStore
For simpler or more localized scenarios, NgRx now provides SignalStore, which allows us to manage state using Signals instead of reducers and actions.
If we revisit our counter example, a Signal-based store might look like this:
import { patchState, signalStore, withMethods, withState } from '@ngrx/signals';
export const CounterStore = signalStore(
withState({
currentValue: 0,
}),
withMethods((store) => ({
increase() {
patchState(store, (state) => ({
currentValue: state.currentValue + 1,
}));
},
decrease() {
patchState(store, (state) => ({
currentValue: state.currentValue - 1,
}));
},
}))
);
This should feel familiar, but also noticeably simpler. The state and the logic that updates it live together, and methods can update state through patchState. There are no reducers or actions here because, for this kind of local state, they are often unnecessary.
Signals vs. the Redux Pattern
The traditional NgRx Store follows a Redux-inspired pattern. Actions describe what happened, reducers determine how state changes, and selectors expose slices of that state. This structure enforces a strong separation of concerns and makes state transitions predictable.
SignalStore takes a different approach. By colocating state and behavior, it reduces boilerplate and can make smaller features easier to reason about. However, this simplicity comes with trade-offs. The Redux-style approach still provides clearer boundaries, more explicit state transitions, and better tooling for large applications.
This means the two approaches are not competing so much as complementing each other. SignalStore works well for local or feature-level state, where simplicity and directness are valuable. The traditional NgRx Store remains a strong choice for global state, complex workflows, and scenarios where side effects and cross-cutting concerns need to be carefully managed.
Many modern Angular applications use both patterns side by side, choosing the right tool depending on the complexity of the problem.
Handling Side Effects in NgRx
Let’s say our Counter Application has a timer in it and every three seconds it automatically increases the value by one. This is a simple side effect, which has to live somewhere. It’s the same side effect, by definition, as an Ajax request.
If we think about side effects, most have two main reasons to exist:
- Doing anything outside the state environment
- Updating application state
In modern Angular and NgRx applications, side effects are typically triggered by actions and handled using tools like NgRx Effects or integrated into SignalStore methods, depending on the chosen state management approach.
From a conceptual point of view, however, the distinction remains the same. For example, storing some state inside the LocalStorage is the first option, while updating the state from the Ajax response is the second. But they both share the same signature: Each side effect has to have some starting point. It needs to be called at least once to prompt it to start the action.
As we outlined earlier, NgRx has a nice tool for giving someone a command. That’s an action. We could call any side effect by dispatching an action. The pseudo code could look like this:
function startTimer(){
setInterval(()=>{
console.log("Hello application");
},3000)
}
on(CounterActions.StartTime,startTimer)
...
// We start timer by dispatching an action
dispatch(CounterActions.StartTime);
It’s pretty trivial. As I mentioned earlier, side effects either update something or not. If a side effect doesn’t update anything, there’s nothing to do; we just leave it. But if we want to update a state, how do we do it? The same way a component tries to update a state: calling another action. So we call an action inside the side effect, which updates the state:
function startTimer(store) {
setInterval(()=> {
// We are dispatching another action
dispatch(CounterActions.IncreaseValue)
}, 3000)
}
on(CounterActions.StartTime, startTimer);
...
// We start timer by dispatching an action
dispatch(CounterActions.StartTime);
We now have a fully functional application.
Summarizing Our NgRx Experience
There are some important topics I would like to mention before we finish our NgRx journey:
- The code shown is simple pseudo code I invented for the article; it is only fit for demonstration purposes. NgRx is the place where real sources live.
- There is no official guideline that proves my theory about connecting functional programming with the NgRx library. It’s just my opinion formed after reading dozens of articles and source code samples created by highly skilled people.
- After using NgRx you will definitely realize that it’s way more complex than this simple example. My goal was not to make it look simpler than it actually is but to show you that even though it’s a bit complex and may even result in a longer path to the destination, it’s worth the added effort.
- The worst usage for NgRx is to use it everywhere, regardless of the size or complexity of the application. There are some cases in which you should not use NgRx; for example, in forms. While reactive forms can be integrated with NgRx, they are closely tied to the DOM and Angular’s form APIs, so storing every form interaction in NgRx often adds more complexity than value. If you try to decouple forms from the DOM, you will find yourself hating not only NgRx but web technology in general.
- Sometimes using the same boilerplate code, even for a small example, can turn into a nightmare, even if it can benefit us in the future. If that’s the case, just integrate with another amazing library, which is a part of the NgRx ecosystem (ComponentStore and its newer Signal-based counterparts).
Further Reading on the Toptal Blog:
Understanding the basics
NgRx is a global state management library that helps decouple the Domain and Business layers from the Rendering layer. It’s fully reactive. All changes can be listened to using simple Observables, which makes complex business scenarios easier to handle.
It makes applications much more maintainable and testing-friendly because it decouples Business and Domain logic from the Rendering layer. It’s also easier to debug because every action in the application is a command that can be traced back using Redux DevTools.
Never use NgRx if your application is a small one with just a couple of domains or if you want to deliver something quickly. It comes with a lot of boilerplate code, so in some scenarios it will make your coding more difficult.
NgRx and RxJS have nothing in common. They’re different libraries with different purposes. NgRx is a state management library, whereas RxJS is more of a toolkit library that wraps JavaScript asynchronous behavior into the Observer and observables. In addition, NgRx uses RxJS internally.

Tbilisi, Georgia
Member since February 9, 2021
About the author
With solid full-stack experience, Luka is currently working as a front-end team lead and developer, specializing in Node.js, Angular, and JavaScript.