
Big Data Architecture for the Masses: A ksqlDB and Kubernetes Tutorial
Today’s cloud building blocks empower any size team—even a lone engineer—to build big data solutions. Learn how to use open-source tools to create scalable architecture for your next project.

Today’s cloud building blocks empower any size team—even a lone engineer—to build big data solutions. Learn how to use open-source tools to create scalable architecture for your next project.

Dmitrii is a solution architect and developer with more than 11 years of experience and expertise in SQL, NoSQL, and Kubernetes. He built big data architecture at Videoland, founded and acted as CTO for Deetask, a Vietnamese marketplace app similar to Thumbtack, and holds a master’s degree in computer science from Izhevsk State Technical University.
Previously At

For more than two decades, few developers and architects dared touch big data systems due to implementation complexities, excessive demands for capable engineers, protracted development times, and the unavailability of key architectural components.
But in recent years, the emergence of new big data technologies has allowed a veritable explosion in the number of big data architectures that process hundreds of thousands—if not more—events per second. Without careful planning, using these technologies could require significant development efforts in execution and maintenance. Fortunately, today’s solutions make it relatively simple for any size team to use these architectural pieces effectively.
Period | Characterized by | Description |
|---|---|---|
2000-2007 | The prevalence of SQL databases and batch processing | The landscape is composed of MapReduce, FTP, mechanical hard drives, and the Internet Information Server. |
2007-2014 | The rise of social media: Facebook, Twitter, LinkedIn, and YouTube |
Photos and videos are being created and shared at an unprecedented rate via increasingly ubiquitous smartphones. The first cloud platforms, NoSQL databases, and processing engines (e.g., Apache Cassandra 2008, Hadoop 2006, MongoDB 2009, Apache Kafka 2011, AWS 2006, and Azure 2010) are released and companies hire engineers en masse to support these technologies on virtualized operating systems, most of which are on-site. |
2014-2020 | Cloud expansion | Smaller companies move to cloud platforms, NoSQL databases, and processing engines, backing an ever wider variety of apps. |
2020-Present | Cloud evolution | Big data architects shift their focus toward high availability, replication, auto-scaling, resharding, load balancing, data encryption, reduced latency, compliance, fault tolerance, and auto-recovery. The use of containers, microservices, and agile processes continues to accelerate. |
Modern architects must choose between rolling their own platforms using open-source tools or choosing a vendor-provided solution. Infrastructure-as-a-service (IaaS) is required when adopting open-source offerings because IaaS provides the basic components for virtual machines and networking, allowing engineering teams the flexibility to craft their architecture. Alternatively, vendors’ prepackaged solutions and platform-as-a-service (PaaS) offerings remove the need to gather these basic systems and configure the required infrastructure. This convenience, however, comes with a larger price tag.
Companies may effectively adopt big data systems using a synergy of cloud providers and cloud-native, open-source tools. This combination allows them to build a capable back end with a fraction of the traditional level of complexity. The industry now has acceptable open-source PaaS options free of vendor lock-in.
In the remainder of this article, we present a big data architecture that showcases ksqlDB and Kubernetes operators, which depend on the open-source Kafka and Kubernetes (K8s) technologies, respectively. Additionally, we’ll incorporate YugabyteDB to provide new scalability and consistency capabilities. Each of these systems is powerful independently, but their capabilities amplify when combined. To tie our components together and easily provision our system, we rely on Pulumi, an infrastructure-as-code (IaC) system.
Our Sample Project’s Architectural Requirements
Let’s define hypothetical requirements for a system to demonstrate a big data architecture aimed at a general-purpose application. Say we work for a local video-streaming company. On our platform, we offer localized and original content, and need to track progress functionality for each video a customer watches.
Our primary use cases are:
Stakeholder | Use Case |
|---|---|
Customers | Customer content consumption generates system events. |
Third-party License Holders | Third-party license holders receive royalties based on owned content consumption. |
Integrated Advertisers | Advertisers require impression metric reports based on user actions. |
Assume that we have 200,000 daily users, with a peak load of 100,000 simultaneous users. Each user watches two hours per day, and we want to track progress with five-second accuracy. The data does not require strong accuracy (as compared with payment systems, for example).
So we have roughly 300 million heartbeat events daily and 100,000 requests per second (RPS) at peak times:
300,000 users x 1,440 heartbeat events generated over two daily hours per user (12 heartbeat events per minute x 120 minutes daily) = 288,000,000 heartbeats per day ≅ 300,000,000
We could use simple and reliable subsystems like RabbitMQ and SQL Server, but our system load numbers exceed the limits of such subsystems’ capabilities. If our business and transaction load grows by 100%, for instance, these single servers would no longer be able to handle the workload. We need horizontally scalable systems for storage and processing, and we as developers must use capable tools—or suffer the consequences.
Before we choose our specific systems, let’s consider our high-level architecture:
With our system structure specified, we now get to go shopping for suitable systems.
Data Storage
Big data requires a database. I’ve noticed a trend away from pure relational schemas toward a blend of SQL and NoSQL approaches.
SQL and NoSQL Databases
Why do companies choose databases of each type?
SQL | NoSQL |
|---|---|
|
|
Modern databases of each type are beginning to implement one another’s features. The differences between SQL and NoSQL offerings are rapidly shrinking, making it more challenging to choose a tool for our architecture. Current database industry rankings indicate that there are nearly 400 databases to choose from.
Distributed SQL Databases
Interestingly, a new class of databases has evolved to cover all significant functionality of the NoSQL and SQL systems. A distinguishing feature of this emergent class is a single logical SQL database that is physically distributed across multiple nodes. While offering no dynamic schema, the new database class boasts these key features:
- Transactions
- Synchronous replication
- Query distribution
- Distributed data storage
- Horizontal write scalability
Per our requirements, our design should avoid cloud lock-in, eliminating database services like Amazon Aurora or Google Spanner. Our design should also ensure that the distributed database handles the expected data volume. We’ll use the performant and open source YugabyteDB for our project needs; here’s what the resulting cluster architecture will look like:

More precisely, we chose YugabyteDB because it is:
- PostgreSQL-compatible and works with many PostgreSQL database tools such as language drivers, object-relational mapping (ORM) tools, and schema-migration tools.
- Horizontally scalable, where performance scales out simply as nodes are added.
- Resilient and consistent in its data layer.
- Deployable in public clouds, natively with Kubernetes, or on its own managed services.
- 100% open source with powerful enterprise features such as distributed backups, encryption of data at rest, in-flight TLS encryption, change data capture, and read replicas.
Our chosen product also features attributes that are desirable for any open-source project:
- A healthy community
- Outstanding documentation
- Rich tooling
- A well-funded company to back up the product
With YugabyteDB, we have a perfect match for our architecture, and now we can look at our stream-processing engine.
Real-time Stream Processing
You’ll recall that our example project has 300 million daily heartbeat events resulting in 100,000 requests per second. This throughput generates a lot of data that is not useful to us in its raw form. We can, however, aggregate it to synthesize our desired final form: For each user, which segments of videos did they watch?
Using this form results in a significantly smaller data storage requirement. To translate the raw data into our desired format, we must first implement real-time stream-processing infrastructure.
Many smaller teams with no big data experience might approach this translation by implementing microservices subscribed to a message broker, selecting recent events from the database, and then publishing processed data to another queue. Though this approach is simple, it forces the team to handle deduplication, reconnections, ORMs, secrets management, testing, and deployment.
More knowledgeable teams that approach stream processing tend to choose either the pricier option of AWS Kinesis or the more affordable Apache Spark Structured Streaming. Apache Spark is open source, yet vendor-specific. Since the goal of our architecture is to use open-source components that allow us the flexibility of choosing our hosting partner, we will look at a third, interesting alternative: Kafka in combination with Confluent’s open-source offerings that include schema registry, Kafka Connect, and ksqlDB.
Kafka itself is just a distributed log system. Traditional Kafka shops use Kafka Streams to implement their stream processing, but we will use ksqlDB, a more advanced tool that subsumes Kafka Streams’ functionality:

More specifically, ksqlDB—a server, not a library—is a stream-processing engine that allows us to write processing queries in an SQL-like language. All of our functions run inside of a ksqlDB cluster that, typically, we physically position close to our Kafka cluster, so as to maximize our data throughput and processing performance.
We’ll store any data we process in an external database. Kafka Connect allows us to do this easily by acting as a framework to connect Kafka with other databases and external systems, such as key-value stores, search indices, and file systems. If we want to import or export a topic—a “stream” in Kafka parlance—into a database, we don’t need to write any code.
Together, these components allow us to ingest and process the data (for example, group heartbeats into window sessions) and save to the database without writing our own traditional services. Our system can handle any workload because it is distributed and scalable.
Kafka is not perfect. It is complex and requires deep knowledge to set up, work with, and maintain. As we’re not maintaining our own production infrastructure, we’ll use managed services from Confluent. At the same time, Kafka has a huge community and a vast collection of samples and documentation that can help us in just about any situation.
Operational Tools
Now that we have covered our core architectural components, let’s look at operational tools to make our lives simpler.
Infrastructure-as-code: Pulumi
Infrastructure-as-code (IaC) enables DevOps teams to deploy and manage infrastructure with simple instructions at scale across multiple providers. IaC is a critical best practice of any cloud-development project.
Most teams that use IaC tend to go with Terraform or a cloud-native offering like AWS CDK. Terraform requires we write in its product-specific language, and AWS CDK only works within the AWS ecosystem. We prefer a tool that allows better flexibility in writing our deployment specifications and doesn’t lock us into a specific vendor. Pulumi perfectly matches these requirements.
Pulumi is a cloud-native platform that allows us to deploy any cloud infrastructure, including virtual servers, containers, applications, and serverless functions.
We don’t need to learn a new language to work with Pulumi. We can use one of our favorites:
- Python
- JavaScript
- TypeScript
- Go
- .NET/C#
- Java
- YAML

So how do we put Pulumi to work? For example, say we want to provision an EKS cluster in AWS. We would:
- Install Pulumi.
- Install and configure AWS CLI.
- Pulumi is just an intelligent wrapper on top of supported providers.
- Some providers require calls to their HTTP API, and some, like AWS, rely on its CLI.
- Run
pulumi up.- The Pulumi engine reads its current state from storage, calculates the changes made to our code, and attempts to apply those changes.
In an ideal world, our infrastructure would be installed and configured through IaC. We’d store our entire infrastructure description in Git, write unit tests, use pull requests, and create the whole environment using one click in our continuous integration and continuous deployment tool.
Kubernetes Operators
Kubernetes is a cloud application operating system. It can be self-managed, managed, or bare metal, or in the cloud, K3s, or OpenShift. But the core is always Kubernetes. Outside of rare instances involving serverless, legacy, and vendor-specific systems, Kubernetes is a must-have component when building solid architecture, and is only growing in popularity.

We will deploy all of our stateful and stateless services to Kubernetes. For our stateful services (i.e., YugabyteDB and Kafka), we will use an additional subsystem: Kubernetes operators.

A Kubernetes operator is a program that runs in and manages other resources in Kubernetes. For example, if we want to install a Kafka cluster with all its components (e.g., schema registry, Kafka Connect), we would need to oversee hundreds of resources, such as stateful sets, services, PVCs, volumes, config maps, and secrets. Kubernetes operators help us by removing the overhead of managing these services.
Stateful system publishers and enterprise developers are the leading writers of these operators. Regular developers and IT teams can leverage these operators to more easily manage their infrastructures. Operators allow for a straightforward, declarative state definition that is then used to provision, configure, update, and manage their associated systems.
In the early big data days, developers managed their Kubernetes clusters with raw manifest definitions. Then Helm entered the picture and simplified Kubernetes operations, but there was still room for further optimization. Kubernetes operators came into being and, in concert with Helm, made Kubernetes a technology that developers could quickly put into practice.
To demonstrate how pervasive these operators are, we can see that each system presented in this article already has its released operators:
Pulumi | Uses an operator to implement GitOps principles and apply changes as soon as they are committed to a git repository. |
Kafka |
With all of its components, has two operators:
|
YugabyteDB | Provides an operator for ease of use. |
Having discussed all significant components, we may now examine an overview of our system.
Our Architecture With Preferred Systems
Although our design comprises many components, our system is relatively simple in the overall architecture diagram:

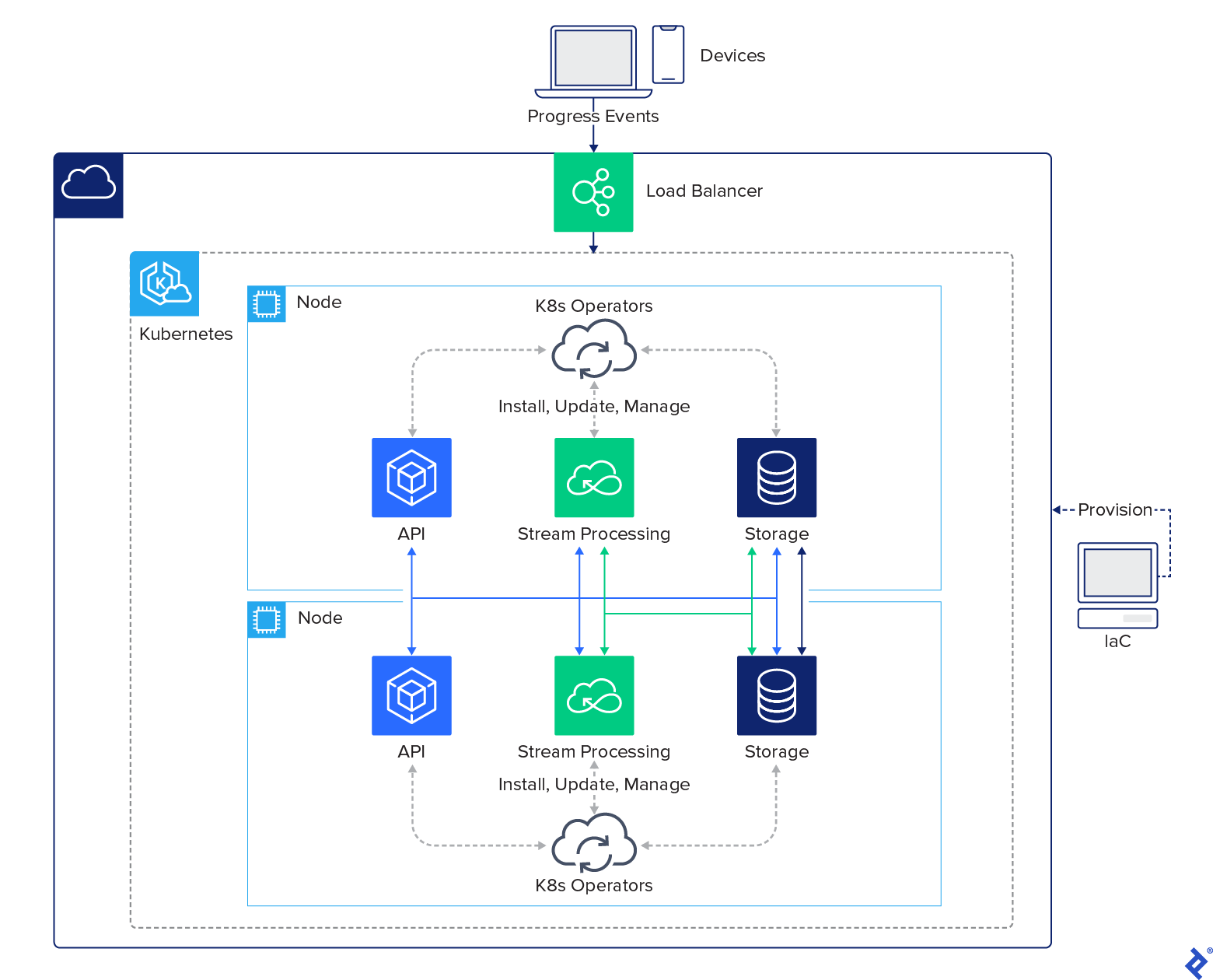
Focusing on our Kubernetes environment, we can simply install our Kubernetes operators, Strimzi and YugabyteDB, and they will do the rest of the work to install the remaining services. Our overall ecosystem within our Kubernetes environment is as follows:

This deployment describes a distributed cloud architecture made simple using today’s technologies. Implementing what was impossible as recently as five years ago may only take only a few hours today.
The editorial team of the Toptal Engineering Blog extends its gratitude to David Prifti and Deepak Agrawal for reviewing the technical content and code samples presented in this article.
Further Reading on the Toptal Blog:
Understanding the basics
Distributed storage, computation, and the messaging to connect the two are the key components to any big data architecture.
Big data architects solve the same problems as other software architects, while also designing low-latency and high-availability systems with workloads that exceed 100,000 requests per second.
There is no best architecture for a big data application. What is best for Google may not be what’s best for TikTok, for example. However, event-driven architecture is the current design approach for distributed systems in which multi-cloud deployment, microservices, asynchronous multicast event-based communications protocols, and real-time stream processing prevail.
ksqlDB is a stream-processing engine that allows developers to write solutions in an SQL-like language.
K8s—shorthand for Kubernetes—is used for the orchestration and deployment of containerized applications.
Kubernetes operators are plugins (application-specific controllers) that assist Kubernetes implementations with maintenance, configuration, and deployment tasks.
Nha Trang, Khanh Hoa Province, Vietnam
Member since May 3, 2022
About the author
Dmitrii is a solution architect and developer with more than 11 years of experience and expertise in SQL, NoSQL, and Kubernetes. He built big data architecture at Videoland, founded and acted as CTO for Deetask, a Vietnamese marketplace app similar to Thumbtack, and holds a master’s degree in computer science from Izhevsk State Technical University.
PREVIOUSLY AT