
The Advanced Git Guide: Git Stash, Reset, Rebase, and More
Could you be using Git more efficiently?
The answer is probably a resounding “Yes,” which is why Toptal Software Engineer Ursula Clarke wrote today’s post.
In it, she teaches you how to use git stash, git reset, git bisect, git squash, and git rebase for maximum productivity.

Could you be using Git more efficiently?
The answer is probably a resounding “Yes,” which is why Toptal Software Engineer Ursula Clarke wrote today’s post.
In it, she teaches you how to use git stash, git reset, git bisect, git squash, and git rebase for maximum productivity.

Ursula has over five years of experience in software development and specializes in front-end development, especially intricate UI.
Expertise
Previously At

Every developer should have a good understanding of version control, and Git has become the de-facto standard for version control in software development.
Often though, developers only learn a few simple commands and overlook the power of Git history and the other things that Git can do to make you much more efficient. For example, managing releases is very easy with Git using git tag.
I took an advanced course in Git online (with Github) and proceeded to teach a beginner’s Git class in conjunction with Github. When I noticed there were not many technical articles on my favorite Git features, I jumped at the chance to share it with my fellow developers. In this post, you’ll learn how to leverage the following advanced Git functions:
-
git stash, which makes a temporary, local save of your code -
git reset, which lets you tidy up your code before doing a commit -
git bisect, a function that allows you to hunt out bad commits -
git squash, which allows you to combine your commits -
git rebase, which allows for applying changes from one branch onto another
Git Stash
Git stash enables you to save your code without making a commit. How is this useful? Picture the following scenario:
You’ve already made three neat and tidy commits, but you also have some uncommitted code that’s quite messy; you won’t want to commit it without removing your debugging code first. Then, for some reason, you suddenly need to attend to another task and have to switch branches. This can often happen if you are on your main branch, and you have forgotten to create a new branch for your feature. Right now, your code looks like this:
$ git status
On branch my-feature
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore -- <file>..." to discard changes in working directory)
modified: css/common.scss
no changes added to commit (use "git add" and/or "git commit -a")
$ git diff
diff --git a/css/common.scss b/css/common.scss
index 2090cc4..90fd457 100644
--- a/css/common.scss
+++ b/css/common.scss
@@ -13,6 +13,6 @@
body {
font-family: "Proxima Nova", Arial, sans-serif;
font-size: 13px;
- color: #333;
+ color: red;
background-color: #f00;
}
When you run git stash, the uncommitted code disappears without being committed. Stashing is like saving a temporary local commit to your branch. It is not possible to push a stash to a remote repository, so a stash is just for your own personal use.
$ git stash
Saved working directory and index state WIP on my-feature: 49ee696 Change text color
Your branch now appears as it was when you made your last commit. Now, you can safely change branches without losing your code or having a messy commit. When you switch back to your branch and run git stash list you’ll see a list of stashes that look something like this:
$ git stash list
stash@{0}: WIP on my-feature: 49ee696 Change text color
You can easily reapply the stashed content by running git stash apply. You can also apply a specific stash (if you have stashed more than once) by running git stash apply stash@{1} (the ‘1’ denotes the second before last stash). Here is an example of stashing more than one commit and applying a different stash:
$ git diff
diff --git a/css/common.scss b/css/common.scss
index 2090cc4..90fd457 100644
--- a/css/common.scss
+++ b/css/common.scss
@@ -13,6 +13,6 @@
body {
font-family: "Proxima Nova", Arial, sans-serif;
font-size: 13px;
- color: #333;
+ color: red;
background-color: #f00;
}
$ git stash
Saved working directory and index state WIP on my-feature: 49ee696 Change text color
$ git diff
diff --git a/css/common.scss b/css/common.scss
index 2090cc4..b63c664 100644
--- a/css/common.scss
+++ b/css/common.scss
@@ -13,6 +13,6 @@
body {
font-family: "Proxima Nova", Arial, sans-serif;
font-size: 13px;
- color: #333;
+ color: red;
background-color: #f00;
}
$ git stash
Saved working directory and index state WIP on my-feature: 49ee696 Change text color
$ git stash list
stash@{0}: WIP on my-feature: 49ee696 Change text color
stash@{1}: WIP on my-feature: 49ee696 Change text color
stash@{2}: WIP on my-feature: 49ee696 Change text color
$ git stash apply stash@{2}
On branch my-feature
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore -- <file>..." to discard changes in working directory)
modified: css/common.scss
no changes added to commit (use "git add" and/or "git commit -a")
git stash apply stash@{2} has applied the oldest stashed code, when we changed the colour of the text to red.
$ git diff
diff --git a/css/common.scss b/css/common.scss
index 2090cc4..90fd457 100644
--- a/css/common.scss
+++ b/css/common.scss
@@ -13,6 +13,6 @@
body {
font-family: "Proxima Nova", Arial, sans-serif;
font-size: 13px;
- color: #333;
+ color: red;
background-color: #f00;
}
If you decide not to commit your work once you have restored the stash, you can run git restore ., which discards uncommitted changes to tracked files.
As another example of how to use Git stash: say you have some new files, one of which has a bug. Leave all but the suspected bug file unstaged (code must be staged to be stashed), then you can stash that file and troubleshoot the issue. If the stashed file was not the problem, you can restore the stash.
$ git status
On branch my-feature
Untracked files:
(use "git add <file>..." to include in what will be committed)
css/colors.scss
nothing added to commit but untracked files present (use "git add" to track)
$ git add css/colors.scss
$ git stash
Saved working directory and index state WIP on my-feature: 0d8deef delete colors
$ git status
On branch my-feature
nothing to commit, working tree clean
$ git stash apply stash@{0}
On branch my-feature
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: css/colors.scss
You can also carry over your stashed commits to a new feature branch or debugging branch by using git stash branch:
$ git status
On branch my-feature
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore -- <file>..." to discard changes in working directory)
modified: css/common.scss
no changes added to commit (use "git add" and/or "git commit -a")
$ git stash
Saved working directory and index state WIP on my-feature: 66f3f3b Add colors file
$ git stash branch debugging-branch
M css/common.scss
Switched to a new branch 'debugging-branch'
Unstaged changes after reset:
M css/common.scss
On branch debugging-branch
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore -- <file>..." to discard changes in working directory)
modified: css/common.scss
Dropped refs/stash@{0} (d140624f60d8deef7bceb0d11fc80ed4fd47e0a1)
Note that when you have applied a stash, the stash is not deleted. You can remove stashes individually by using git drop, or remove all stashes by using git stash clear:
$ git stash list
stash@{0}: WIP on my-feature: 66f3f3b Add colors file
stash@{1}: WIP on my-feature: 0d8deef delete colors
stash@{2}: WIP on my-feature: 49ee696 Change text color
$ git stash drop stash@{2}
Dropped stash@{2} (8ed6d2ce101aa2e28c8ccdc94cb12df8e5c468d6)
$ git stash list
stash@{0}: WIP on my-feature: 66f3f3b Add colors file
stash@{1}: WIP on my-feature: 0d8deef delete colors
$ git stash clear
$ git stash list
$
Git Reset
If you do find yourself in the situation where you’ve accidentally committed some messy code, you can do a “soft” reset. This means that the code appears as if it has not been committed yet. Then you can tidy up your code in your IDE before making a cleaner commit. To do this you can run git reset --soft HEAD~1. This will reset the most recent commit. You can reset back more than one commit by changing the number after ~ e.g. git reset --soft HEAD~2.
$ git reset --soft HEAD~1
$ git status
On branch debugging-branch
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: css/common.scss
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore -- <file>..." to discard changes in working directory)
modified: css/common.scss
$ git diff
diff --git a/css/common.scss b/css/common.scss
index 2090cc4..90fd457 100644
--- a/css/common.scss
+++ b/css/common.scss
@@ -13,6 +13,6 @@
body {
font-family: "Proxima Nova", Arial, sans-serif;
font-size: 13px;
- color: $grey;
+ color: red;
background-color: #f00;
}
Git reset is bit more confusing, especially when teaching new Git users. A soft reset should be reserved for a genuine mistake whereas a stash can be used to swap code in and out.
You can also perform a hard reset (git reset --hard HEAD~1). This type of reset essentially erases your last commit. You should be very careful about performing hard resets, especially if you push your branch, as there is no way to restore your commit.
Git Bisect
My favourite Git tool is git bisect. I’ve only needed it a handful of times but when I did, it was invaluable! I primarily used it on large codebases where there was an issue for which nobody found the root cause, even after some vigorous debugging.
git bisect essentially performs a binary search between two given commits and then presents you with a specific commit’s details. You first need to give Git a good commit, where you know your functionality was working, and a bad commit. Note that as long as you have one good commit and one bad, the commits can be years apart (although the farther back in time you go, the more difficult it becomes!).
The most fun thing about git bisect is that you usually don’t really know who wrote the buggy commit when you start. The excitement of finding out where the bug was introduced has more than once caused a few coworkers to huddle around my computer!
To get started, switch to the buggy branch and find the good commits. You’ll need to go through your commit history and find the commit hash, then switch to that specific commit in detached HEAD mode and test your branch. Once you find a good and bad spot to work from, you can run a git bisect.
In this scenario, the text is red on this website we’ve made (though it could use a UI designer) but we don’t know how or when it was made red. This is a very simple example, in a real-life scenario you’d probably have a much less obvious problem e.g. a form not submitting/functioning.
When we run a git log, we can see the list of commits to pick from.
$ git log
commit a3cfe7f935c8ad2a2c371147b4e6dcd1a3479a22 (HEAD -> main)
Author: Ursula Clarke <email@example.com>
Date: Tue Feb 17 10:52:57 2026 +0100
Update .gitignore file for .DS_Store
commit 246e90977790967f54e878a8553332f48fae6edc
Author: Ursula Clarke <email@example.com>
Date: Tue Feb 17 10:51:23 2026 +0100
Change styling of page
commit d647ac489ad43b3c6eaea5aceb02b0a7d7e5cf8e
Author: Ursula Clarke <email@example.com>
Date: Tue Feb 17 10:50:48 2026 +0100
Change text color
commit 032a41136b6653fb9f7d81aef573aed0dac3dfe9
Author: Ursula Clarke <email@example.com>
Date: Tue Feb 17 10:42:57 2026 +0100
Change text color
commit 246e90977790967f54e878a8553332f48fae6edc
Author: Ursula Clarke <email@example.com>
Date: Tue Feb 17 10:41:23 2026 +0100
delete colors
commit d647ac489ad43b3c6eaea5aceb02b0a7d7e5cf8e
Author: Ursula Clarke <email@example.com>
Date: Tue Feb 17 10:50:48 2026 +0100
Change text color
commit ce861e4c6989a118aade031020fd936bd28d535b
Author: Ursula Clarke <email@example.com>
Date: Tue Feb 17 10:07:36 2026 +0100
...
If I open my webpage on the most recent commit hash, the text is red, so I know I have a problem.
Now we start the bisect and tell Git we have a bad commit.
$ git bisect start
$ git bisect bad 8d4615b9a963ef235c2a7eef9103d3b3544f4ee1
Now we go back in time to try and find a commit where the text was not red. Here I try checking out my first commit…
$ git switch --detach ce861e4c6989a118aade031020fd936bd28d535b
Note: checking out 'ce861e4c6989a118aade031020fd936bd28d535b'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later). Example:
git switch -c <new-branch-name>
HEAD is now at ce861e4 Add CSS styles
…and refreshing the webpage…
The text is no longer red, so this is a good commit! The newer the commit (i.e., the closer to the bad commit), the better:
$ git switch --detach d647ac489ad43b3c6eaea5aceb02b0a7d7e5cf8e
Previous HEAD position was ce861e4c6989a118aade031020fd936bd28d535b Add CSS styles
HEAD is now at d647ac4 Change text color
Git will now tell you how many commits it has to search before finding the right one. The number of commits Git will traverse depends on how many commits are in between the good and bad commit (the longer length of time, the more times Git needs to iterate).
Now, you’ll need to test your branch again and see if your issue has disappeared. Sometimes this can be a little cumbersome if you regularly update modules, since you may need to reinstall node modules on your front end repository. If there have been database updates you may also need to update these.
git bisect automatically checks out a commit in the middle of your good and bad commits. Here it is estimating one step to find the bad commit.
$ git bisect good 1cdbd113cad2f452290731e202d6a22a175af7f5
Bisecting: 1 revision left to test after this (roughly 1 step)
[ce861e4c6989a118aade031020fd936bd28d535b] Add CSS styles
$ git status
HEAD detached at ce861e4
You are currently bisecting, started from branch '8d4615b'.
(use "git bisect reset" to get back to the original branch)
Refresh the page, and see if your problem is gone. The issue is still there, so we tell Git that this is still a bad commit. No need to reference the commit hash this time since Git will use the commit you have checked out. We’ll need to repeat this process until Git has traversed all the possible steps.
$ git bisect bad
Bisecting: 0 revisions left to test after this (roughly 0 steps)
[cbf1b9a1be984a9f61b79ae5f23b19f66d533537] Add second paragraph to page
Refresh the page, and our issue is gone again, so this is a good commit:
At this stage Git has found the first bad commit:
$ git bisect good
ce861e4c6989a118aade031020fd936bd28d535b is the first bad commit
commit ce861e4c6989a118aade031020fd936bd28d535b
Author: Ursula Clarke <email@example.com>
Date: Tue Feb 17 10:52:57 2026 +0100
Add CSS styles
:000000 100644 0000000000000000000000000000000000000000 092bfb9bdf74dd8cfd22e812151281ee9aa6f01a M css
Now we can use git show to show the commit itself and identify the issue:
$ git show ce861e4c6989a118aade031020fd936bd28d535b
commit ce861e4c6989a118aade031020fd936bd28d535b
Author: Ursula Clarke <email@example.com>
Date: Tue Feb 17 10:52:57 2026 +0100
Add CSS styles
diff --git a/css/base.scss b/css/base.scss
index e69de29..26abf0f 100644
--- a/css/base.scss
+++ b/css/base.scss
@@ -1,7 +1,7 @@
body {
background-color: $white;
margin: 0px;
line-height: 20px;
- color: $grey;
+ color: red;
}
When you’re finished, you can run git bisect reset to reset your branch to its normal working state.
The closer the commits are together, the easier Git will be able to find the problem, but I’ve had it take 10 steps before and still find the bad commit easily. It’s not guaranteed to work, but it has found the issue most of the time for me. Congratulations, now you’re a code archaeologist!
Squashing Your Commits
I previously worked full time on an open source project for a global organization and I quickly learned how important it is to squash—or combine—your commits. I think it’s an excellent habit to get into, even if your employer doesn’t require it. It’s especially considerate for other developers who will need to review and edit features you have built later.
Why squash your commits?
- It’s easier for contributors to your repository to read. Imagine if you have a commit list like so:
- Implement carousel slider
- Add styling to carousel
- Add buttons to carousel
- Fix strange issue in IE with carousel
- Adjust margins in carousel
- It’s much easier to squash these into a single commit that says “Add carousel to homepage”.
- It encourages you to keep your commit messages understandable and relevant if every time you make a pull request, you have to squash your commits into one. How many times have you seen a commit titled “WIP,” “bugfix for login page,” or “fix typo”? It’s important to have relevant commit names e.g. “Bugfix for #444 login page - fix flicker due to missing $scope function”.
A reason you may not want to squash your commits could be because you are working on a very detailed and lengthy feature, and want to keep a daily history for yourself in case you come across bugs later on. Then your feature is easier to debug. However, when checking your feature into your main branch and you are confident it is bug free, it still makes sense to squash.
In this scenario, I have made five commits, but all of them are related to one feature. My commit messages are also too closely related to merit being separate—all of my commits are about styling the page for this new feature:
$ git log
commit a8fbb81d984a11adc3f72ce27dd0c39ad24403b7 (HEAD -> main)
Author: Ursula Clarke <email@example.com>
Date: Tue Feb 17 11:16:10 2026 +0100
Import colors
commit e2b3ddd5e8b2cb1e61f88350d8571df51d43bee6
Author: Ursula Clarke <email@example.com>
Date: Tue Feb 17 11:15:32 2026 +0100
Add new color
commit d647ac489ad43b3c6eaea5aceb02b0a7d7e5cf8e
Author: Ursula Clarke <email@example.com>
Date: Tue Feb 17 10:50:48 2026 +0100
Change text color
commit c005d9ceeefd4a8d4e553e825fa40aaafdac446e
Author: Ursula Clarke <email@example.com>
Date: Tue Feb 17 09:59:57 2026 +0100
Add CSS styles
commit 9e046b7df59cef07820cc90f694fabc666731bd2
Author: Ursula Clarke <email@example.com>
Date: Tue Feb 17 09:56:28 2026 +0100
Add second paragraph to page
commit 5aff973577d67393d914834e8af4c5d07248d628
Author: Ursula Clarke <email@example.com>
Date: Mon Feb 16 16:04:22 2026 +0100
Add colors CSS file and edit background color
You can also use git merge --squash, but I think it is clearer to use rebase because when you cherry pick your commits it is easier to see the commit description. If you run a git merge --squash, you first have to do a hard reset of your commits (git reset --hard HEAD~1 ), and it’s easy to get confused with exactly how many commits you need to do this with. I find git rebase to be more visual.
Start by running git rebase -i --root and your default text editor on the command line will open with your list of commits:
pick eb1eb3c Update homepage
pick 5aff973 Add colors CSS file and edit background color
pick 9e046b7 Add second paragraph to page
pick c005d9c Add CSS styles
pick d647ac4 Change text color
pick e2b3ddd Add new color
pick a8fbb81 Import colors
# Rebase a8fbb81 onto b862ff2 (7 commands)
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
# d, drop = remove commit
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
#
# Note that empty commits are commented out
You may just want to squash your last few commits, in which case you could run git rebase -i HEAD~3 and be presented with your last three commits:
pick eb1eb3c Update homepage
pick 5aff973 Add colors CSS file and edit background color
pick 9e046b7 Add second paragraph to page
# Rebase b862ff2..9e046b7 onto b862ff2 (3 commands)
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
# d, drop = remove commit
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
#
# Note that empty commits are commented out
Now we can squash all commits into the first commit as shown below.
pick eb1eb3c Update homepage
squash 5aff973 Add colors CSS file and edit background color
squash 9e046b7 Add second paragraph to page
# Rebase b862ff2..9e046b7 onto b862ff2 (3 commands)
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
# d, drop = remove commit
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
#
# Note that empty commits are commented out
When you save the file, Git will open your commit message to edit.
# This is a combination of 3 commits.
# This is the 1st commit message:
Update homepage
# This is the commit message #2:
Add colors CSS file and edit background color
# This is the commit message #3:
Add second paragraph to page
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
#
# Date: Wed Feb 18 18:31:28 2026 +0100
#
# interactive rebase in progress; onto b862ff2
# Last commands done (3 commands done):
# squash 5aff973 Add colors CSS file and edit background color
# squash 9e046b7 Add second paragraph to page
# No commands remaining.
# You are currently rebasing branch 'main' on 'b862ff2'.
#
# Changes to be committed:
# new file: .gitignore
# new file: css/base.css
# new file: css/base.scss
# new file: css/colors.css
# new file: css/colors.css.map
# new file: css/colors.scss
# new file: css/common.css
# new file: css/common.scss
# new file: index.html
#
While we are doing the rebase, we can also edit the commit description so that it is easier to read.
Implement new design for homepage. Add .gitignore file for Sass folder.
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
#
Save this file again and you’re done! When we take another look at the Git log we can see there is just one clean commit.
[detached HEAD 574ec7e] Implement new design for homepage. Add .gitignore file for Sass folder.
Date: Wed Feb 18 18:31:28 2026 +0100
10 files changed, 215 insertions(+)
create mode 100644 .gitignore
create mode 100644 css/base.css
create mode 100644 css/base.scss
create mode 100644 css/colors.css
create mode 100644 css/colors.css.map
create mode 100644 css/colors.scss
create mode 100644 css/common.css
create mode 100644 css/common.scss
create mode 100644 index.html
create mode 100644 verylargefile.txt
Successfully rebased and updated refs/heads/main.
$ git log
commit 574ec7e5d7d7a96427e049cad9806cdef724aedd (HEAD -> main)
Author: Ursula Clarke <email@example.com>
Date: Wed Feb 18 18:31:28 2026 +0100
Implement new design for homepage. Add .gitignore file for Sass folder.
Git Rebase
Developers are usually hesitant to use git rebase because they know that a rebase can be used to permanently delete files from your codebase.
As we saw above, git rebase can be used to keep your code and tidy it as well as delete - but what if you really do want to permanently remove a file from history?
I once witnessed a scenario where a member of our development team had accidentally committed a very large file to the codebase. It was part of a much bigger branch so the large file went unnoticed in code review and was mistakenly checked into the main branch. This became an issue whenever anyone wanted to re-clone the repository - it took a very long time to download! And of course, the file in question was unnecessary. It wouldn’t have been a problem if the file was the last commit to the main branch - in that case you could just run a hard reset (git reset --hard HEAD~1) and force push the branch.
Likewise, if the file was the only change in a given commit, you could just remove the entire commit by running git reset --hard <commit-id>. In our scenario, though, the large file was committed alongside other code that we wanted to keep in history, as the second-to-last commit.
These days, I’d probably reach for git-filter-repo when removing large files, secrets, or other unwanted content from Git history. In this example, though, we’ll use git rebase because it illustrates how history rewriting works under the hood and gives you fine-grained control over individual commits.
Once you find the troublesome commit, switch to it in detached HEAD mode using git switch --detach and the commit hash:
$ git switch --detach ce861e4c6989a118aade031020fd936bd28d535b
Note: checking out 'ce861e4c6989a118aade031020fd936bd28d535b'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later). Example:
git switch -c <new-branch-name>
HEAD is now at ce861e4 Add CSS styles
Remove the file, or edit your code, and leave the code (or files) you want to keep intact.
$ rm verylargefile.txt
$ git status
HEAD detached at ce861e4
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git restore -- <file>..." to discard changes in working directory)
deleted: verylargefile.txt
no changes added to commit (use "git add" and/or "git commit -a")
Make sure you run git add -A so that your deleted file is staged and Git knows to remove it. Now run git commit --amend -v and Git will ask you to edit your commit message.
After this, run git rebase --onto HEAD <commit-id> main. This is where you could come across some merge conflicts, meaning there is a conflict between your new commit and the old code. Git will ask you to resolve the conflict:
$ git add -A
$ git status
HEAD detached at ce861e4
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
deleted: verylargefile.txt
$ git commit --amend -v
[detached HEAD 7c9516a] Add CSS styles
Date: Thu Feb 19 14:43:54 2026 +0100
3 files changed, 9 insertions(+), 2 deletions(-)
create mode 100644 css/common.css.map
delete mode 100644 verylargefile.txt
$ git status
HEAD detached from ce861e4
nothing to commit, working tree clean
$ git rebase --onto HEAD ce861e4
First, rewinding head to replay your work on top of it...
Fast-forwarded HEAD to HEAD.
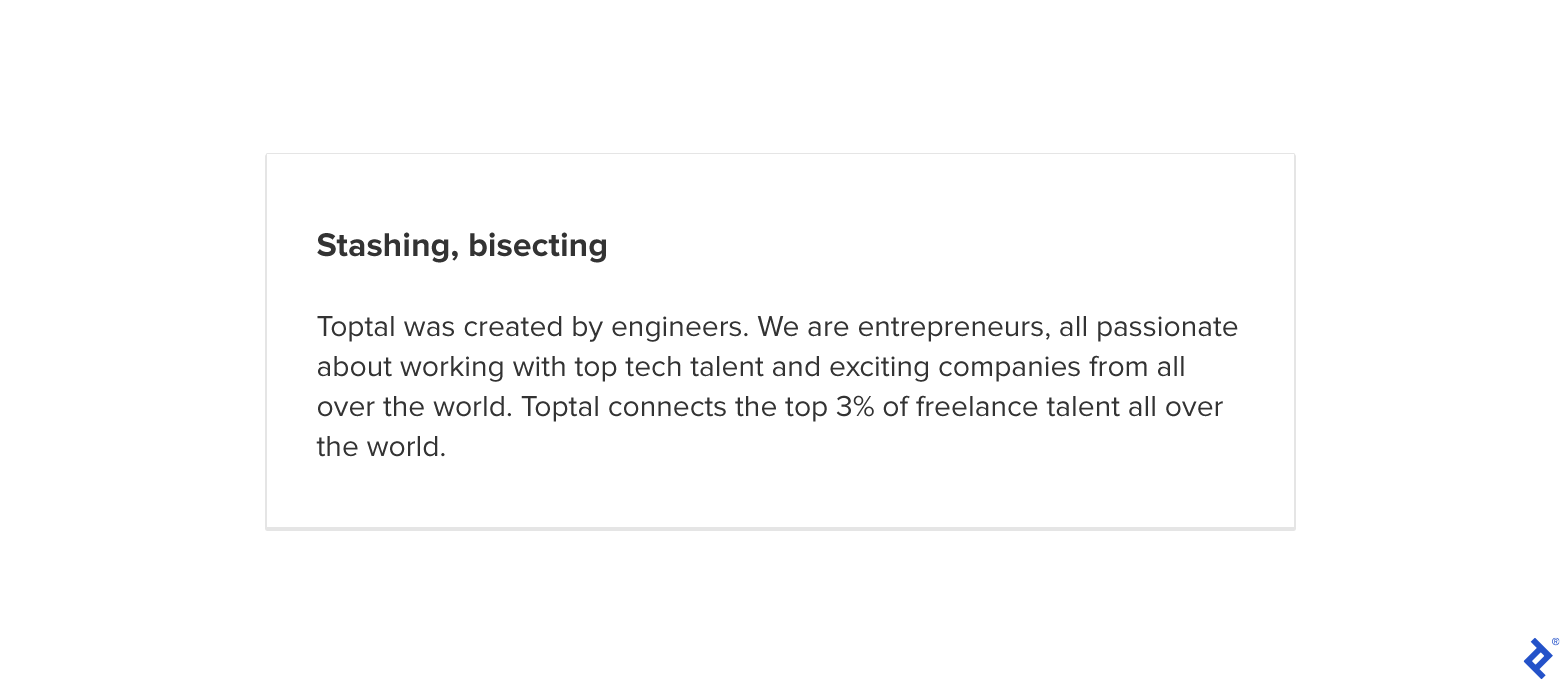
If you open the file in your text editor, you’ll see that Git has marked out two versions of the index file. You simply need to remove one or edit one to keep the changes you like.
<p>
Toptal was created by engineers. We are entrepreneurs, all passionate about
working with top tech talent and exciting companies from all over the world.
</p>
<<<<<<< HEAD
<p>
Toptal connects the top 3% of freelance talent all over the world.
</p>
</main>
</body>
</html>
=======
</main>
</body>
</html>
>>>>>>> Add index file
The code between <<<<<<< HEAD and the line of equals signs is one version, and the code between the equals signs and >>>>>>> Add index file is the version from the “Add index file” commit. So you can see that one version has the additional paragraph of “Toptal connects the top 3% of freelance talent all over the world,” while the other does not.
Save your edited file and run git add filename followed by git rebase --continue. If there are no changes you can also run git rebase --skip. It can take a while to go through the rebasing if there were a lot of commits between your “large file” commit and the latest commit on main.
Be patient, and if you’re in a large team make sure to get a second opinion! It’s especially important to consult with the person(s) who wrote the commit(s) you are merging, if possible.
Remember that the merge changes are relevant to the specific commit in history, and not your most up to date changes. I.e. if you are editing a commit from when the text on your site was Arial, and it is now Verdana, you should still keep that commit with the history of Arial as the font face.
Note also that if Git sees a space or an end of line character, it can cause a merge conflict, so be careful!
More Than Just Commit and Pull
Git is more powerful than a lot of developers think. If you happen to be introducing a newbie, make sure to give them some tips on these invaluable features. It makes for a more efficient workflow.
Looking to learn more about Git? Take a look at Toptal’s Git Tips and Practices page.
Ursula Clarke
Bruges, Belgium
Member since January 13, 2017
About the author
Ursula has over five years of experience in software development and specializes in front-end development, especially intricate UI.
Expertise
PREVIOUSLY AT