
Ensemble Methods: The Kaggle Machine Learning Champion
Two heads are better than one. This proverb describes the concept behind ensemble methods in machine learning. Let’s examine why ensembles dominate ML competitions and what makes them so powerful.

Two heads are better than one. This proverb describes the concept behind ensemble methods in machine learning. Let’s examine why ensembles dominate ML competitions and what makes them so powerful.

Juan is a lecturer at the University of Buenos Aires. His research focuses on AI, NLP, and social networks. He has more than a decade of data science experience and he’s published papers at ML conferences, including SPIRE and ICCS.
Expertise
Previously At

The proverb “Two heads are better than one” takes on new meaning when it comes to machine learning ensembles. Ensemble methods are some of the most decorated ML families at Kaggle competitions, where they often win contests with their impressive results.
But it was a century before Kaggle when statistician Sir Francis Galton noticed the potency of aggregated intelligence. He happened upon a competition at a livestock fair where participants had to guess the weight of an ox. Eight hundred people submitted guesses, but their skill levels varied: Farmers and butchers guessed alongside city dwellers who had never seen an ox up close, so Galton thought the average guess would be quite wrong.
It turned out that the mean of the crowd’s guesses was off by less than a pound (< 0.1%). However, even the best individual predictions were well off the mark.
How could that be? What made such an unexpected result possible?
What Makes Machine Ensembles so Effective
The event that forced Galton to question his beliefs also illustrates what makes ensembles so powerful: If you have different and independent models, trained using different parts of data for the same problem, they will work better together than individually. The reason? Each model will learn a different part of the concept. Therefore, each model will produce valid results and errors based on its “knowledge.”
But the most interesting thing is that each true part will complement the others while the errors cancel out each other:

You need to train models with high variance (like decision trees) over distinct subsets of data. This added variance means that each model overfits different data, but when combined, the variance disappears, as if by magic. This creates a new, more robust model.
Just like in Galton’s case, when all data from all sources is combined, the result is “smarter” than isolated data points.
A Closer Look at Ensemble Learning in Kaggle Competitions
At the Otto Group Product Classification Challenge, participants had to build a predictive model that was able to distinguish between main product categories.
Here you can see how the winning model was built. It was a stacking of three layers: The first had 33 models, the second added three more (XGBoost, a neural network, and AdaBoost), and the third was the weighted mean of the previous layer outputs. It was both a very complex model and an ensemble.
Another Kaggle success is the model created by Chenglong Chen at the Crowdflower Search Results Relevance competition. The challenge was to create a predictor that could be used to measure the relevance of search results. You can read the complete explanation of his method, but as our point of interest is ensembles, the critical part of the story is that the winning solution used an ensemble of 35 models, many of which were also ensembles—a meta-ensemble, so to speak.
Ensemble Methods
There are many ways of implementing ensemble methods in machine learning. We’ll explore some of the most popular methods:
-
Bagging
- Random Forest
-
Boosting
- AdaBoost
- Gradient Boosting and XGBoost
-
Hybrid Ensemble Methods
- Voting
- Stacking
- Cascading
Bagging
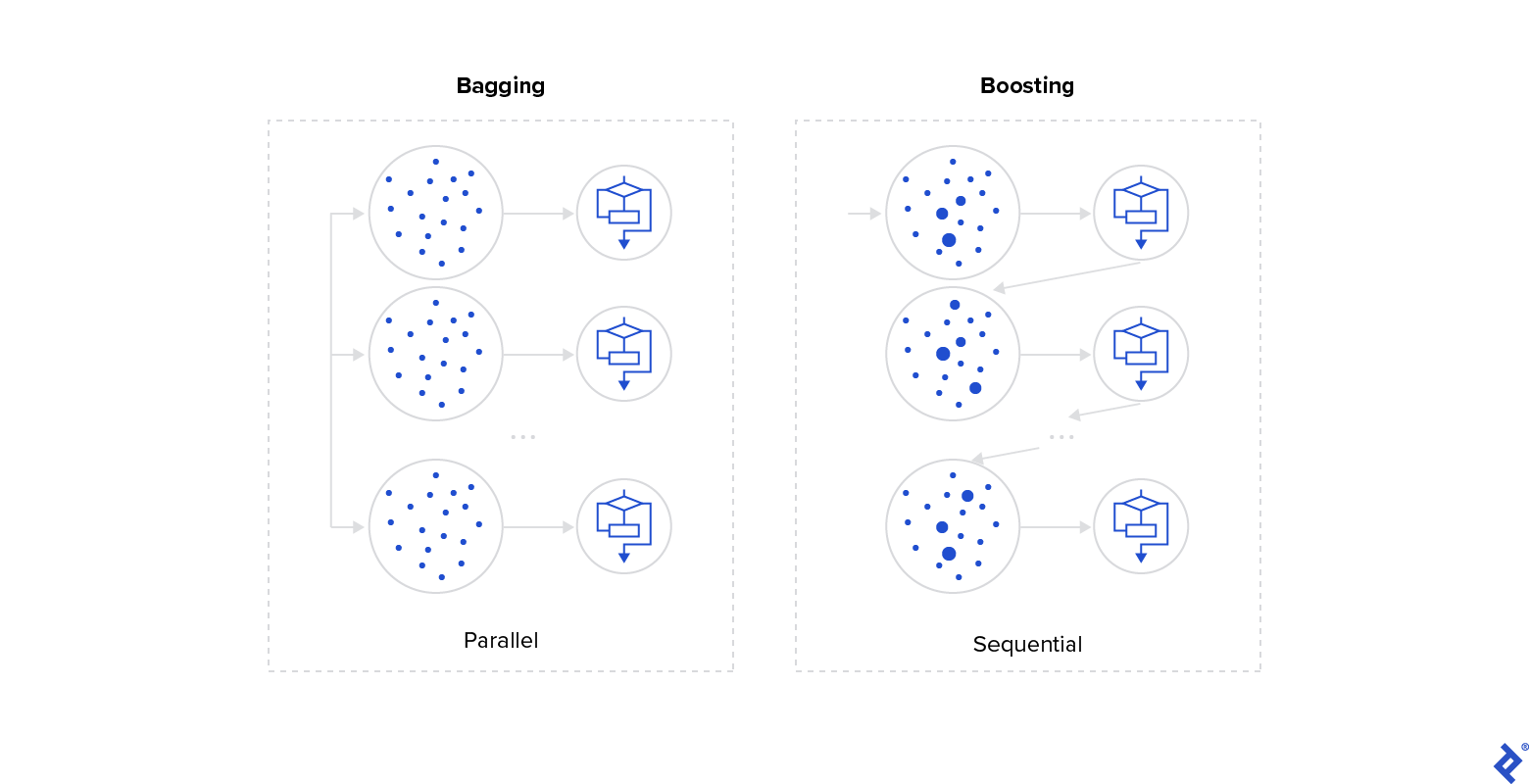
As mentioned, you need to train many models over different subsets of data. In practice, this is not easy because you will need much more data for many models than you would for a single model, and sometimes it is not easy to obtain high-quality datasets. This is when bagging (bootstrap aggregating) comes in handy, as it splits the data through bootstrapping: a random sample with a replacement, resulting in different subsets that overlap.
Once you have trained your ensemble models, you construct your final prediction by aggregating each model prediction through any metric you prefer: the mean, median, mode, and so on. You can also use model prediction probabilities to make a weighted metric:
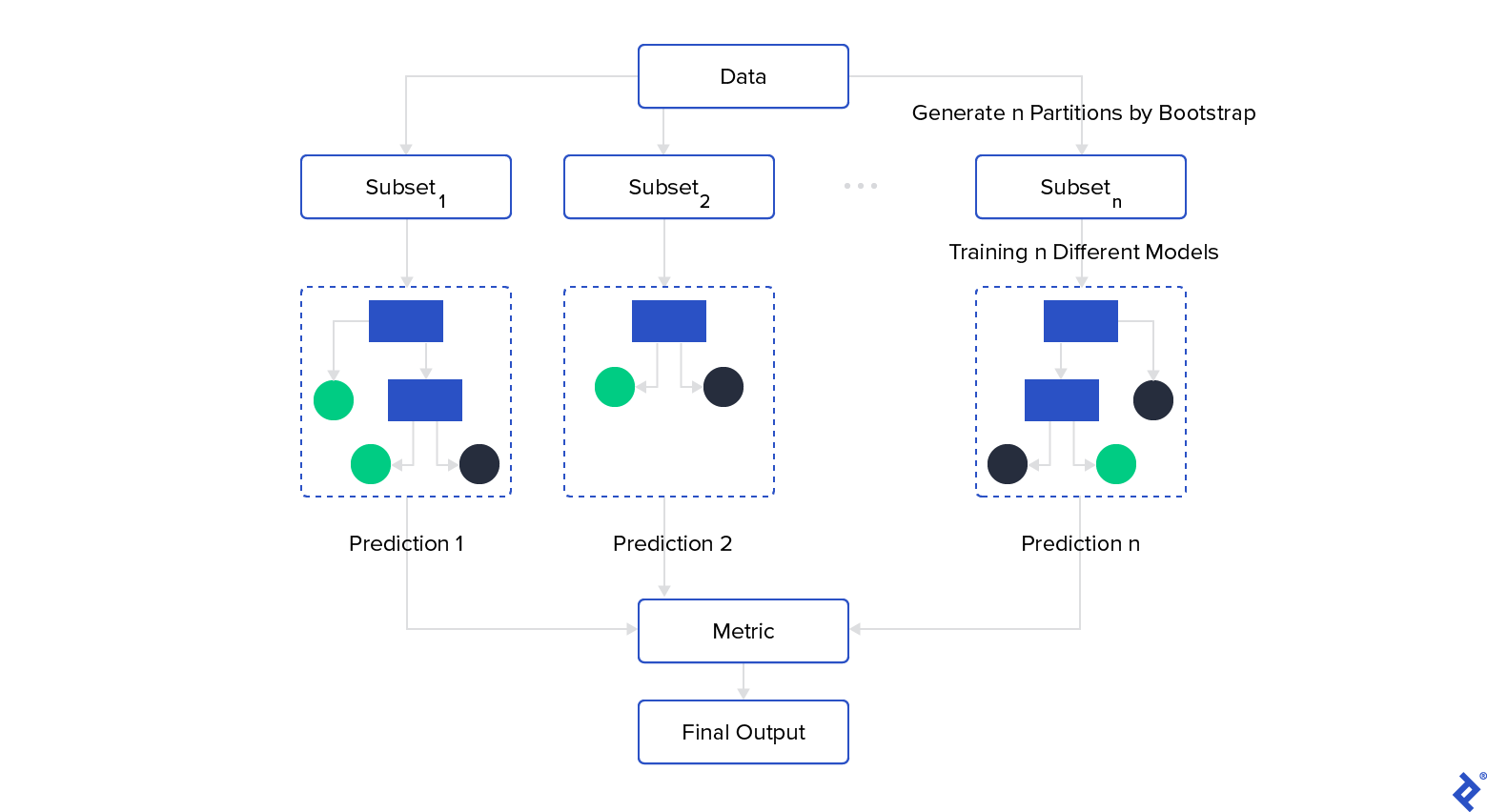
If we want to use decision trees as models but we have few strong predictive attributes in our data, all the trees will be similar. This is because the same attributes will tend to be in the root node, producing similar results in each branch of the tree.
Random Forest
One technique to address this problem is random forest. It makes a bagging ensemble using trees but each node constrains its possible attributes to a random subset. This forces the models to be different, resolving the previous problem. It also makes random forest a very good model for feature selection.
Random forest is one of the most popular ML models because it delivers good performance with low variance and training time.
Boosting
Boosting also uses bootstrapping to train the models, with the main difference being that it adds weights to each instance based on model prediction errors. While bagging is a parallel process, boosting is a sequential one, in which each model has more probabilities. This allows it access to some instances of previous model predictions.
With this modification, boosting tries to increase the focus over misclassified instances to reach better global performance:
It adds weights to models too. Predictors with better performance at training time will have a higher weight at the predicting stage.
Let’s take a closer look at some of the most popular boosting models:
AdaBoost
AdaBoost was one of the first implementations of boosting. It does almost exactly what we outlined about boosting in general and uses decision trees as models. Let’s explain the training phase with some pseudo coding:
For each instance i
Assign w[i] (weight, same for all)
For each iteration t
Generate a subset s[t] by weighted boosting (using the w[i] weights)
Train model m[t] using s[t]
Store m[t]
Calculate e[t] (error rate of m[t])
Assign error rate e[t] to stored m[t] model
If (e[t] <= a_threshold)
Exit for
Update weights using m[t] errors
At prediction time, it weights each prediction based on the error rate e[t] calculated for each one. Results with a high error rate will have less weight than others with better accuracy.
Gradient Boosting and XGBoost
One of the major problems when training so many models and making them work together is finding the best hyperparameter configuration. It is difficult to find the best configuration for a single model; finding the best configuration for n models increases the complexity exponentially. The ideal configuration for an isolated model is likely not the same as the configuration for a model that has to work with others. As such, you should search the configuration of all models at the same time, but how?
Gradient boosting brings an elegant solution to this problem. It creates a loss function that has, as input, all the hyperparameter values of all the models and, as output, the error of the whole ensemble. Through gradient descent, it finds the minimum value of the function (i.e., the lowest error) and thereby the best hyperparameter configuration for each model.
This approach introduces a scaling problem. Enter the king of machine learning for structured data: extreme gradient boosting, XGBoost for short. It is an incredibly efficient implementation of gradient boosting, thanks to various techniques, such as parallelized computing, built-in cross-validation capability, regularization to avoid overfitting, and hardware optimization. XGBoost delivers outstanding performance.
XGBoost became popular when its creator used it for a Kaggle challenge and won by a wide margin. He published the result and created a Python wrapper to allow more people to use it. When many people recognized its potential, XGBoost quickly became an ML champion.
Hybrid Ensemble Methods
But the story doesn’t end there. We have seen many types of ensembles that all use the same kind of model—why not try combinations of different models? If you do that well, you can create an even more powerful ML method: a hybrid ensemble.
Voting
Voting is one of the simplest approaches to creating a hybrid ensemble. It trains many different model algorithms and makes them “vote” at the predicting phase:

You can add weights to each model based on its performance or predicting probabilities and generate a weighted vote.
Stacking
Stacking advances the idea of voting by adding a new layer over the base models to make the final prediction instead of merely calculating the mean or majority. It adds the concept of meta-learning, as the new layer learns not from the data but from the model predictions:
You can stack all the meta-layers you like, resulting in a model with many levels. For stacked models, I recommend using decision trees, SVMs, or perceptrons. For base models, you can use any method you want, even another ensemble, creating an ensemble of ensembles. Stacking works even better with base models like decision trees that generate not only a value prediction, but also the probability of it being correct.
Stacking is less popular than bagging or boosting because it is more difficult to interpret what stacked models are learning and because there are a much greater number of variants: You can play with many combinations of model algorithms, hyperparameter configurations, and stacking layers. However, with the right combination of models, stacking can be even stronger than boosting and bagging.
Cascading
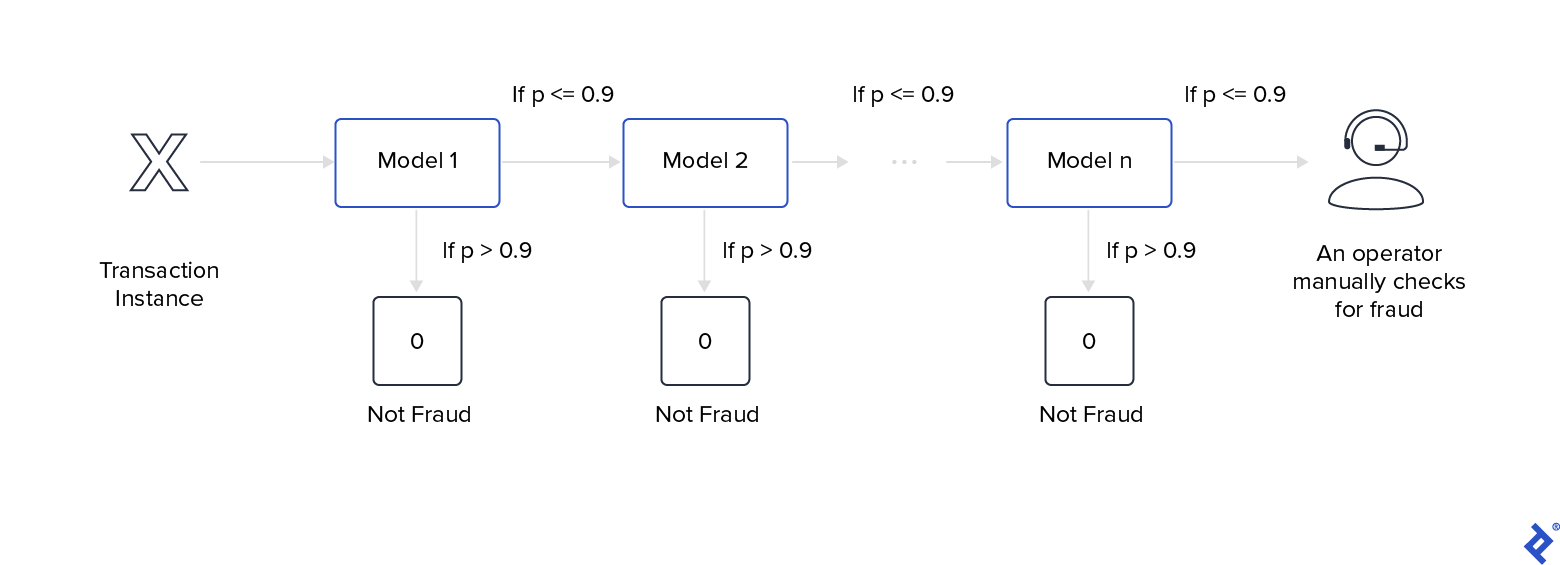
Cascading is used when you want to have a great degree of certainty in the prediction. It uses a stacking approach but has only one model in each layer. At each level, models discard instances that they deem to be not of the desired class.
With cascading, simple models evaluate data before complex models do. At the predicting step, the first model receives the data. If the certainty is not greater than x (the value has to be high, something greater than 0.9), it passes the instance to the next model. Otherwise, the cascade returns the predicted output of that model. If no layer can predict the desired class with a high degree of certainty, the ensemble returns the negative class.
A classical use case for this model is predicting when a transaction is likely to be fraudulent. Let’s assume a system computes millions of transactions per day and that it is impossible to control each of them manually. Using a cascading ensemble can discard transactions that are not fraudulent with a very high probability, leaving only a small subset of transactions to check manually:

These models are good options when you need an excellent recall metric.
Unlike voting and stacking, a cascading ensemble uses a multistate approach rather than a multiexpert approach. It’s important to be cautious about very deep cascading because it could produce overfitting.
The Value of Ensemble Methods
Combining many models allows us to create better and more powerful predictors, as happens when humans work together. We outlined three families of ensembles—bagging, boosting, and hybrids—and saw how they train and predict.
A decision tree could be a very weak and unstable model (with a high variance), but a crowd of different trees (random forest) can be a very accurate and stable predictor. One of the principal advantages of ensembles is that they construct models with low variance and low bias, one of the biggest trade-offs in machine learning. In most cases, they outperform other methods, and sometimes they are even better than deep learning. They tend to be weaker than deep neural networks only when operating on unstructured data.
If we continue the comparison to deep neural networks, we can also say that ensembles tend to be lighter and faster at the training and testing phases. Also, they don’t require expensive hardware to run, such as powerful, discrete GPUs.
It’s true that ensembles lack the possibility of being understood intuitively by humans because having tens or hundreds of models working at the same time creates a huge and complex tool. Thankfully, some techniques allow us to understand how these methods make their decisions. One of the most popular is LIME, a method that creates interpretable explanations for a particular instance over any machine learning model.
Kaggle competitions don’t exist solely so developers can have fun, learn new skills, or win prizes. The ultimate goal is to create strong models and release them into the wild, to let them do their magic in real-world scenarios. These kinds of models are used by organizations that handle critical issues. For example, fraud detection is a common use case in industries like banking and travel, which deal with large amounts of money being moved in single transactions.
Ensembles produce better predictions with a lower variance and bias than other models. However, it is difficult to interpret what they are learning, and that can be of critical importance in some sensitive applications. One example of this is the personal loan industry: An ML model could determine whether or not an individual is eligible for a loan. However, if the client asks why the financial institution denied the loan, there should be a detailed explanation, not just “Because our ML model said so.”
Ultimately, whether you want to create powerful ML models for enterprise applications, big banks or small businesses, or just enter contests to boost your professional reputation, ensembles should be your tool of choice.
Further Reading on the Toptal Blog:
- Ensemble Methods: Elegant Techniques to Produce Improved Machine Learning Results
- Adversarial Machine Learning: How to Attack and Defend ML Models
- Strategic Listening: A Guide to Python Social Media Analysis
- Sound Logic and Monotonic AI Models
- A Machine Learning Tutorial With Examples: An Introduction to ML Theory and Its Applications
Understanding the basics
Ensemble learning uses many different machine learning methods working together at the same time. This makes it one of the most powerful and easy to train predictor families in existence today.
Decision trees are not ensembles when they are isolated but a set of decision trees working together can create different types of ensembles, such as gradient boosting or random forest.
There are five types of model ensembles: bagging, boosting, voting, stacking, and cascading.
Kaggle competitions are contests organized by Kaggle, where participants try to create the best machine learning model to solve a given problem. Many competitions offer substantial financial rewards and are sponsored by companies that want to implement these solutions.
Juan Manuel Ortiz de Zarate
Buenos Aires, Argentina
Member since November 6, 2019
About the author
Juan is a lecturer at the University of Buenos Aires. His research focuses on AI, NLP, and social networks. He has more than a decade of data science experience and he’s published papers at ML conferences, including SPIRE and ICCS.
Expertise
PREVIOUSLY AT