Software Reengineering: From Spaghetti to Clean Design
Inheriting someone else’s code can be a nightmare, especially when the code is poorly designed and lacks documentation. In this post, Toptal Engineer Juan Pablo Scida provides a case study of how he reengineered a chat server written in Node.js, transforming its original spaghetti code into a cleanly architected and designed piece of software.

Inheriting someone else’s code can be a nightmare, especially when the code is poorly designed and lacks documentation. In this post, Toptal Engineer Juan Pablo Scida provides a case study of how he reengineered a chat server written in Node.js, transforming its original spaghetti code into a cleanly architected and designed piece of software.

Juan is a software architect with more than 10 years of experience. He is a certified .NET and Java developer, and loves Node.js and Erlang.
Expertise
PREVIOUSLY AT

Can you take a look at our system? The guy who wrote the software isn’t around anymore and we’ve been having a number of problems. We need somebody to look it over and clean it up for us.
Anyone who’s been in software engineering for a reasonable amount of time knows that this seemingly innocent request is often the beginning of a project that “has disaster written all over it”. Inheriting someone else’s code can be a nightmare, especially when the code is poorly designed and lacks documentation.
So when I recently received a request from one of our customers to look over his existing socket.io chat server application (written in Node.js) and improve it, I was extremely wary. But before running for the hills, I decided to at least agree to take a look at the code.
Unfortunately, looking at the code only reaffirmed my concerns. This chat server had been implemented as a single, large JavaScript file. Reengineering this single monolithic file into a cleanly architected and easily maintainable piece of software would indeed be a challenge. But I enjoy a challenge, so I agreed.

The Starting Point - Prepare For Reengineering
The existing software consisted of a single file containing 1,200 lines of undocumented code. Yikes. Moreover, it was known to contain some bugs and to have some performance issues.
In addition, examination of the log files (always a good place to start when inheriting someone else’s code) revealed potential memory leak issues. At some point, the process was reported to be using more than 1GB of RAM.
Given these issues, it immediately became clear that the code would need to be reorganized and modularized before even attempting to debug or enhance business logic. Toward that end, some of the initial issues that needed to be addressed included:
- Code Structure. The code had no real structure at all, making it difficult to distinguish configuration from infrastructure from business logic. There was essentially no modularization or separation of concerns.
- Redundant code. Some parts of the code (such as error handling code for every event handler, the code for making web requests, etc.) were duplicated multiple times. Replicated code is never a good thing, making code significantly harder to maintain and more highly prone to errors (when the redundant code gets fixed or updated in one place but not in the other).
- Hardcoded values. The code contained a number of hardcoded values (rarely a good thing). Being able to modify these values through configuration parameters (rather than requiring changes to hardcoded values in code) would increase flexibility and could also help facilitate testing and debugging.
- Logging. The logging system was very basic. It would generate a single giant log file that was difficult and clumsy to analyze or parse.
Key Architectural Objectives
In the process of beginning to restructure the code, in addition to addressing the specific issues identified above, I wanted to begin to address some of the key architectural objectives that are (or at least, should be) common to the design of any software system. These include:
- Maintainability. Never write software expecting to be the only person who will need to maintain it. Always consider how understandable your code will be to someone else, and how easy it will be for them to modify or debug.
- Extensibility. Never assume that the functionality you’re implementing today is all that will ever be needed. Architect your software in ways that will be easy to extend.
- Modularity. Separate functionality into logical and distinct modules, each with its own clear purpose and function.
- Scalability. Today’s users are increasingly impatient, expecting immediate (or at least close-to-immediate) response times. Poor performance and high latency can cause even the most useful application to fail in the marketplace. How will your software perform as the number of concurrent users and bandwidth requirements increase? Techniques such as parallelization, database optimization, and asynchronous processing can help improve the ability of your system to remain responsive, despite increasing load and resource demands.
Restructuring the Code
Our goal is to go from a single monolithic mongo source code file to a modularized set of cleanly architected components. The resulting code should be significantly easier to maintain, enhance, and debug.
For this application, I’ve decided to organize the code into the following distinct architectural components:
- app.js - this is our entry point, our code will run from here
- config - this where our configuration settings will reside
- ioW - an “IO wrapper” that will contain all IO (and business) logic
-
logging - all logging-related code (note that the directory structure will also include a new
logsfolder that will contain all the log files) - package.json - the list of package dependencies for Node.js
- node_modules - all modules required by Node.js
There is nothing magic about this specific approach; there could be many different ways to restructure the code. I just personally felt that this organization was sufficiently clean and well organized without being overly complex.
The resulting directory and file organization is shown below.
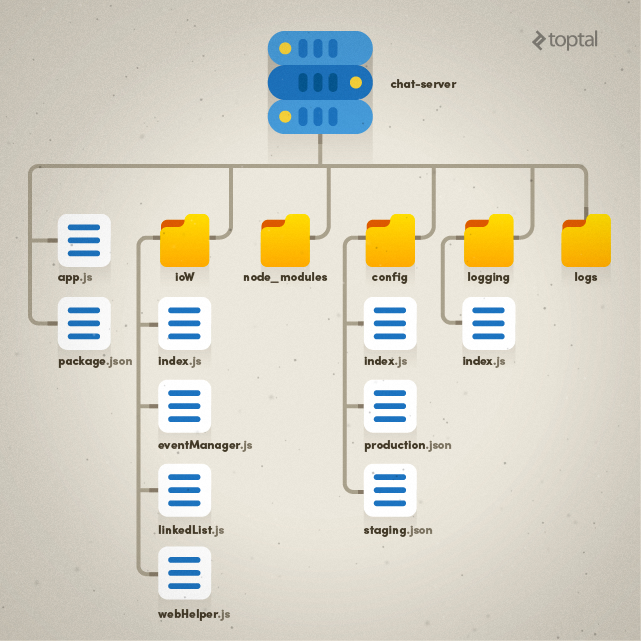
Logging
Logging packages have been developed for most of today’s development environments and languages, so it is rare nowadays that you will need to “roll your own” logging capability.
Since we’re working with Node.js, I selected log4js-node, which is basically a version of the log4js library for use with Node.js. This library has some cool features like the ability to log several levels of messages (WARNING, ERROR, etc.) and we can have a rolling file that can be divided, for example, on a daily basis, so we don’t have to deal with huge files that will take a lot of time to open and be difficult to analyze and parse.
For our purposes, I’ve created a small wrapper around log4js-node to add some specific additional desired capabilities. Note that I have elected to create a wrapper around log4js-node which I will then use throughout my code. This localizes implementation of these extended logging capabilities in a single location thereby avoiding redundancy and unneeded complexity throughout my code when I invoke logging.
Since we are working with I/O, and we would have several clients (users) that will spawn several connections (sockets), I want to be able to trace the activity of a specific user in the log files, and also want to know the source of each log entry. I’m therefore expecting to have some log entries regardind the status of the application, and some that are specific to user activity.
In my logging wrapper code, I’m able to map user ID and sockets, which will allow me to keep track of the actions that were performed prior and subsequent to an ERROR event. The logging wrapper will also allow me to create different loggers with different contextual information that I can pass to the event handlers so I know the source of the log entry.
The code for the logging wrapper is available here.
Configuration
It is often necessary to support different configurations for a system. These differences can either be differences between the development and production environments, or even based on the need to display different customer environments and usage scenarios.
Rather than requiring changes to code to support this, common practice is to control these differences in behavior by way of configuration parameters. In my case, I needed the ability to have different execution environments (staging and production), which may have different settings. I also wanted to ensure that the tested code worked well in both staging and production, and had I needed to change code for this purpose, it would have invalidated the testing process.
Using a Node.js environment variable, I can specify which configuration file I want to use for a specific execution. I therefore moved all the previously hardcoded configuration parameters into configuration files, and created a simple configuration module that loads the proper config file with the desired settings. I also categorized all the settings to enforce some degree of organization on the config file and to make it easier to navigate.
Here’s an example of a resulting config file:
{
"app": {
"port": 8889,
"invRepeatInterval":1000,
"invTimeOut":300000,
"chatLogInterval":60000,
"updateUsersInterval":600000,
"dbgCurrentStatusInterval":3600000,
"roomDelimiter":"_",
"roomPrefix":"/"
},
"webSite":{
"host": "mysite.com",
"port": 80,
"friendListHandler":"/MyMethods.aspx/FriendsList",
"userCanChatHandler":"/MyMethods.aspx/UserCanChat",
"chatLogsHandler":"/MyMethods.aspx/SaveLogs"
},
"logging": {
"appenders": [
{
"type": "dateFile",
"filename": "logs/chat-server",
"pattern": "-yyyy-MM-dd",
"alwaysIncludePattern": false
}
],
"level": "DEBUG"
}
}
Code Flow
So far we have created a folder structure to host the different modules, we have set up a way to load environment specific information, and created a logging system, so let’s see how we can tie together all the pieces without changing business specific code.
Thanks to our new modular structure of the code, our entry point app.js is simple enough, containing initialization code only:
var config = require('./config');
var logging = require('./logging');
var ioW = require('./ioW');
var obj = config.getCurrent();
logging.initialize(obj.logging);
ioW.initialize(config);
When we defined our code structure we said that the ioW folder would hold business and socket.io related code. Specifically, it will contain the following files (note that you can click on any of the file names listed to view the corresponding source code):
-
index.js– handles socket.io initialization and connections as well as event subscription, plus a centralized error handler for events -
eventManager.js– hosts all the business related logic (event handlers) -
webHelper.js– helper methods for doing web requests. -
linkedList.js– a linked list utility class
We refactored the code that makes web request and moved it to a separate file, and we managed to keep our business logic in the same place and unmodified.
One important note: At this stage, eventManager.js still contains some helper functions that really should be extracted into a separate module. However, since our objective in this first pass was to reorganize the code while minimizing impact on the business logic, and these helper functions are too intricately tied into the business logic, we opted to defer this to a subsequent pass at improving the organization of the code.
Since Node.js is asynchronous by definition, we often encounter a bit of a rat’s nest of “callback hell” which makes the code particularly hard to navigate and debug. To avoid this pitfall, in my new implementation, I have employed the promises pattern and are specifically leveraging bluebird which is a very nice and fast promises library. Promises will allow us to be able to follow the code as if it was synchronous and also provide error management and a clean way to standardize responses between calls. There is an implicit contract in our code that every event handler must return a promise so we can manage centralized error handling and logging.
All the event handlers will return a promise (whether they make asynchronous calls or not). With this in place, we can centralize error handling and logging and we make sure that, if we have an unhandled error inside the event handler, that error is caught.
function execEventHandler(socket, eventName, eventHandler, data){
var sLogger = logging.createLogger(socket.id + ' - ' + eventName);
sLogger.info('');
eventHandler(socket, data, sLogger).then(null, function(err){
sLogger.error(err.stack);
});
};
In our discussion of logging, we mentioned that every connection would have its own logger with contextual information in it. Specifically, we are tying the socket id and the event name to the logger when we create it, so when we pass that logger to the event handler, every log line will have that information in it:
var sLogger = logging.createLogger(socket.id + ' - ' + eventName);
One other point worth mentioning with regard to event handling: In the original file, we had a setInterval function call that was inside the event handler of the socket.io connection event, and we have identified this function as a problem.
io.on('connection', function (socket) {
... Several event handlers ....
setInterval(function() {
try {
var date = Date.now();
var tmp = [];
while (0 < messageHub.count() && messageHub.head().date < date) {
var item = messageHub.remove();
tmp.push(item);
}
... Post Data to an external web service...
} catch (e) {
log('ERROR: ex: ' + e);
}
}, CHAT_LOGS_INTERVAL);
});
This code is creating a timer with a specified interval (in our case it was 1 minute) for every single connection request that we get. So, for example, if at any given time we have 300 online sockets, then we would have 300 timers executing every minute. The problem with this, as you can see in the code above, is that there is no usage of the socket nor any variable that was defined within the scope of the event handler. The only variable that is being used is a messageHub variable that is declared at the module level which means it is the same for all connections. There is therefore absolutely no need for a separate timer per connection. So we have removed this from the connection event handler and included it in our general initialization code, which in this case is the initialize function.
Finally, in our processing of responses In webHelper.js, we added processing for any unrecognized response that will log information which will then be helpful to the debugging process:
if (!res || !res.d || !res.d.IsValid){
logger.debug(sendData);
logger.debug(data);
reject(new Error('Request failed. Path ' + params.path + ' . Invalid return data.'));
return;
}
The final step is to set up a logging file for the standard error of Node.js. This file will contain unhandled errors that we may have missed. For setting the node process in Windows (not ideal but you know…) as a service, we use a tool called nssm which has a visual UI that allows you to define a standard output file, standard error file, and environmental variables.
About Node.js Performance
Node.js is a single-threaded programming language. In order to improve scalability, there are several alternatives that we can employ. There is the node cluster module or simply just adding more node processes and put an nginx on top of those to do the forwarding and load balancing.
In our case, though, given that every node cluster subprocess or node process will have its own memory space, we won’t be able to share information between those processes easily. So for this particular case, we will need to use an external data store (such as redis) in order to keep the online sockets available to the different processes.
Conclusion
With all this in place, we have achieved a significant cleanup of the code that was originally handed to us. This is not about making the code perfect, but rather is about reengineering it to create a clean architectural foundation that will be easier to support and maintain, and which will facilitate and simplify debugging.
Adhering to the key software design principles enumerated earlier – maintainability, extensibility, modularity, and scalability – we created modules and a code structure that clearly and cleanly identified the different module responsibilities. We also have identified some problems in the original implementation that lead to high memory consumption that was degrading performance.
Hope you enjoyed the article, let me know if you have further comments or questions.
Juan Pablo Scida
Córdoba, Argentina
Member since August 7, 2014
About the author
Juan is a software architect with more than 10 years of experience. He is a certified .NET and Java developer, and loves Node.js and Erlang.
Expertise
PREVIOUSLY AT