How I Made Porn 20x More Efficient With Python Video Streaming
Porn is a big industry. There aren’t many sites on the Internet that can rival the traffic of its biggest players.
And juggling this immense traffic is tough. To make things even harder, much of the content served from porn sites is made up of low latency live streams rather than simple static video content. But for all of the challenges involved, rarely have I read about the developers who take them on. So I decided to write about my own experience on the job.

Porn is a big industry. There aren’t many sites on the Internet that can rival the traffic of its biggest players.
And juggling this immense traffic is tough. To make things even harder, much of the content served from porn sites is made up of low latency live streams rather than simple static video content. But for all of the challenges involved, rarely have I read about the developers who take them on. So I decided to write about my own experience on the job.

Gergely has worked as lead developer for an Alexa Top 50 website serving several a million unique visitors each month.
PREVIOUSLY AT

Porn is a big industry. There aren’t many sites on the Internet that can rival the traffic of its biggest players.
And juggling this immense traffic is tough. To make things even harder, much of the content served from porn sites is made up of low latency live video streams rather than simple static video content. But for all of the challenges involved, rarely have I read about the python developers who take them on. So I decided to write about my own experience on the job.
What’s the problem?
A few years ago, I was working for the 26th (at the time) most visited website in the world—not just the porn industry: the world.
At the time, the site served up porn video streaming requests with the Real Time Messaging protocol (RTMP). More specifically, it used a Flash Media Server (FMS) solution, built by Adobe, to provide users with live streams. The basic process was as follows:
- The user requests access to some live stream
- The server replies with an RTMP session playing the desired footage
For a couple reasons, FMS wasn’t a good choice for us, starting with its costs, which included the purchasing of both:
- Windows licenses for every machine on which we ran FMS.
- ~$4k FMS-specific licenses, of which we had to purchase several hundred (and more every day) due to our scale.
All of these fees began to rack up. And costs aside, FMS was a lacking product, especially in its functionality (more on this in a bit). So I decided to scrap FMS and write my own Python RTMP parser from scratch.
In the end, I managed to make our service roughly 20x more efficient.
Getting started
There were two core problems involved: firstly, RTMP and other Adobe protocols and formats were not open (i.e., publically available), which made them hard to work with. How can you reverse or parse files in a format about which you know nothing? Luckily, there were some reversing efforts available in the public sphere (not produced by Adobe, but rather by a group called OS Flash, now defunct) on which we based our work.
Note: Adobe later released “specifications” which contained no more information than what was already disclosed in the non-Adobe-produced reversing wiki and documents. Their (Adobe’s) specifications were of an absurdly low quality and made it near impossible to actually use their libraries. Moreover, the protocol itself seemed intentionally misleading at times. For example:
- They used 29-bit integers.
- They included protocol headers with big endian formatting everywhere—except for a specific (yet unmarked) field, which was little endian.
- They squeezed data into less space at the cost of computational power when transporting 9k video frames, which made little to no sense, because they were earning back bits or bytes at a time—insignificant gains for such a file size.
And secondly: RTMP is highly session oriented, which made it virtually impossible to multicast an incoming stream. Ideally, if multiple users wanted to watch the same live stream, we could just pass them back pointers to a single session in which that stream is being aired (this would be multicast video streaming). But with RTMP, we had to create an entirely new instance of the stream for every user that wanted access. This was a complete waste.
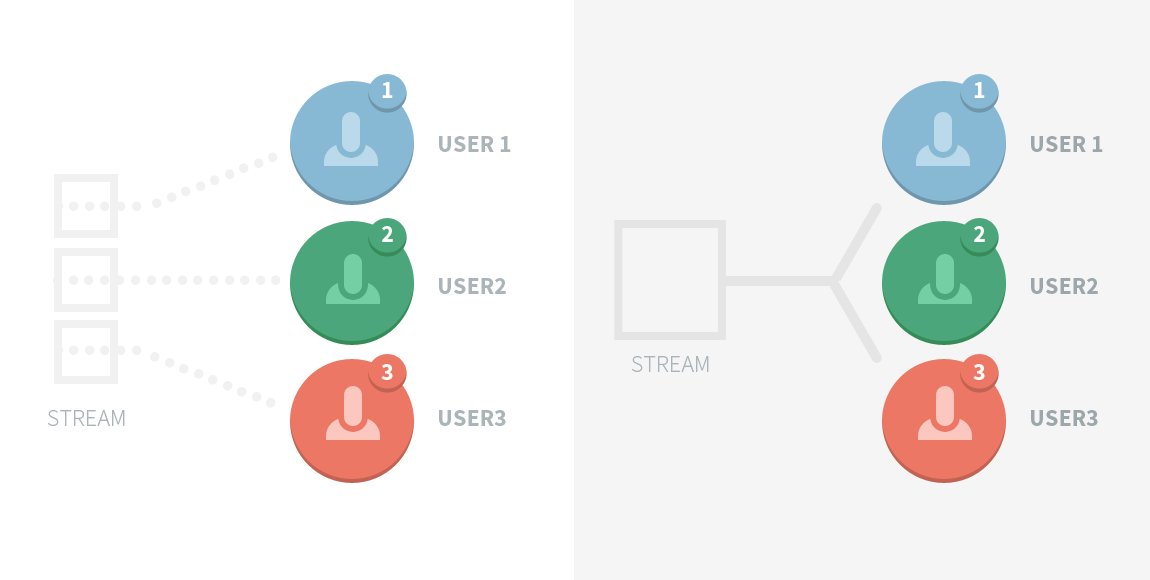
My Multicast Video Streaming Solution
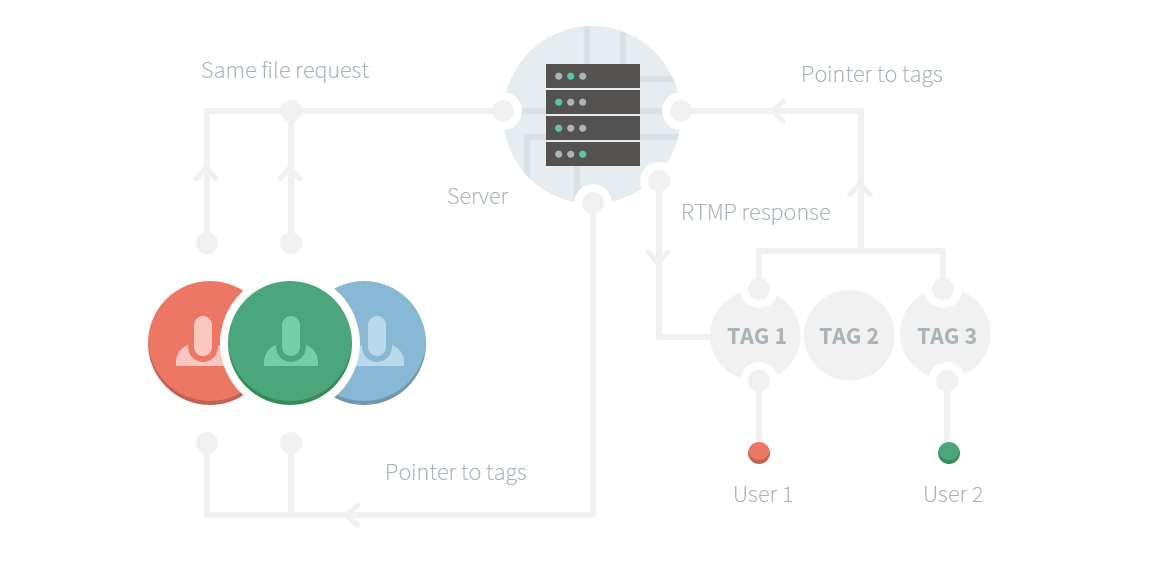
With that in mind, I decided to re-package/parse the typical response stream into FLV ‘tags’ (where a ‘tag’ is just some video, audio, or meta data). These FLV tags could travel within the RTMP with little issue.
The benefits of such an approach:
- We only needed to repackage a stream once (repackaging was a nightmare due to the lack of specifications and protocol quirks outlined above).
- We could re-use any stream between clients with very few problems by providing them simply with an FLV header, while an internal pointer to FLV tags (along with some sort of offset to indicate where they’re at in the stream) allowed access to the content.
I began development in the language I knew best at the time: C. Over time, this choice became cumbersome; so I started learning the basics of Python while porting over my C code. The development process sped up, but after a few demos, I quickly ran into the problem of exhausting resources. Python’s socket handling was not meant to handle these types of situations: specifically, in Python we found ourselves making multiple system calls and context switches per action, adding a huge amount of overhead.
Improving Video Streaming Performance: Mixing Python, RTMP, and C
After profiling the code, I chose to move the performance-critical functions into a Python module written entirely in C. This was fairly low-level stuff: specifically, it made use of the kernel’s epoll mechanism to provide a logarithmic order-of-growth.
In asynchronous socket programming there are facilities that can provide you with info whether a given socket is readable/writable/error-filled. In the past, developers have used the select() system call to get this information, which scales badly. Poll() is a better version of select, but it's still not that great as you have to pass in a bunch of socket descriptors at every call.
Epoll is amazing as all you have to do is register a socket and the system will remember that distinct socket, handling all the gritty details internally. So there's no argument-passing overhead with each call. It also scales far better and returns only the sockets that you care about, which is way better than running through a list of 100k socket descriptors to see if they had events with bitmasks--which you need to do if you use the other solutions.
But for the increase in performance, we paid a price: this approach followed a completely different design pattern than before. The site’s previous approach was (if I recall correctly) one monolithic process which blocked on receiving and sending; I was developing an event-driven solution, so I had to refactor the rest of the code as well to fit this new model.
Specifically, in our new approach, we had a main loop, which handled receiving and sending as follows:
- The received data was passed (as messages) up to the RTMP layer.
- The RTMP was dissected and FLV tags were extracted.
- The FLV data was sent to the buffering and multicasting layer, which organized the streams and filled the low-level buffers of the sender.
- The sender kept a struct for every client, with a last-sent index, and tried to send as much data as possible to the client.
This was a rolling window of data, and included some heuristics to drop frames when the client was too slow to receive. Things worked pretty well.
Systems-level, architectural, and hardware issues
But we ran into another problem: the kernel’s context switches were becoming a burden. As a result, we chose to write only every 100 milliseconds, rather than instantaneously. This aggregated the smaller packets and prevented a burst of context switches.
Perhaps a larger problem lied in the realm of server architectures: we needed a load-balancing and failover-capable cluster—losing users due to server malfunctions is not fun. At first, we went with a separate-director approach, in which a designated ‘director’ would try to create and destroy broadcaster feeds by predicting demand. This failed spectacularly. In fact, everything we tried failed pretty substantially. In the end, we opted for a relatively brute-force approach of sharing broadcasters among the cluster’s nodes randomly, equaling out the traffic.
This worked, but with one drawback: although the general case was handled pretty well, we saw terrible performance when everyone on the site (or a disproportionate number of users) watched a single broadcaster. The good news: this never happens outside a marketing campaign. We implemented a separate cluster to handle this scenario, but in truth we reasoned that jeopardizing the paying user’s experience for a marketing effort was senseless—in fact, this wasn’t really a genuine scenario (although it would have been nice to handle every imaginable case).
Conclusion
Some statistics from the end-result: Daily traffic on the cluster was about a 100k users at peak (60% load), ~50k on average. I managed two clusters (HUN and US); each of them handled about 40 machines to share the load. The aggregated bandwidth of the clusters was around 50 Gbps, from which they used around 10 Gbps while at peak load. In the end, I managed to push out 10 Gbps/machine easily; theoretically1, this number could’ve gone as high as 30 Gbps/machine, which translates to about 300k users watching streams concurrently from one server.
The existing FMS cluster contained more than 200 machines, which could’ve been replaced by my 15—only 10 of which would do any real work. This gave us roughly a 200/10 = 20x improvement.
Probably my greatest take-away from the Python video streaming project was that I shouldn’t let myself be stopped by the prospect of having to learn a new skill set. In particular, Python, transcoding, and object-oriented programming, were all concepts with which I had very sub-professional experience before taking on this multicast video project.
That, and that rolling your own solution can pay big.
1 Later, when we put the code into production, we ran into hardware issues, as we used older sr2500 Intel servers which could not handle 10 Gbit Ethernet cards because of their low PCI bandwidths. Instead, we used them in 1-4x1 Gbit Ethernet bonds (aggregating the performance of several network interface cards into a virtual card). Eventually, we got some of the newer sr2600 i7 Intels, which served 10 Gbps over optics without any performance kinks. All the projected calculations refer to this hardware.
Further Reading on the Toptal Blog:
- 7 Expert Tips for Creating a Convincing Promo Video
- Machine Learning Video Analysis: Identifying Fish
- A Step-by-Step Guide to Creating Animated Product Explainer Videos
- Building an Angular Video Player With Videogular
- A Machine Learning Tutorial With Examples: An Introduction to ML Theory and Its Applications
Gergely Kalman
Málaga, Spain
Member since April 4, 2016
About the author
Gergely has worked as lead developer for an Alexa Top 50 website serving several a million unique visitors each month.
PREVIOUSLY AT